personal-finance-ml-dataset
收藏Hugging Face2025-11-17 更新2025-11-18 收录
下载链接:
https://huggingface.co/datasets/asafmak/personal-finance-ml-dataset
下载链接
链接失效反馈官方服务:
资源简介:
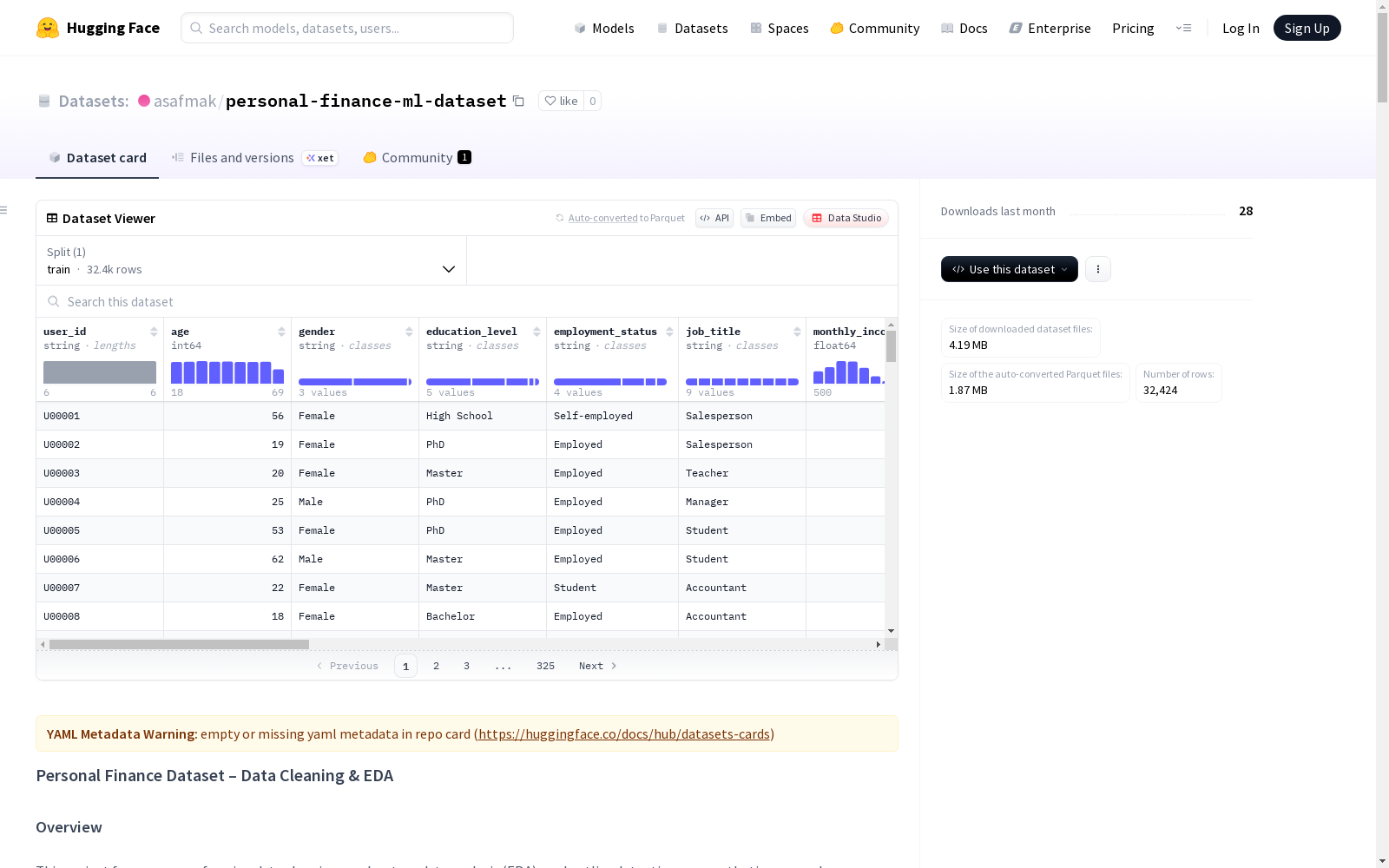
该数据集包含个人财务信息,记录总数为32,424条。主要特征包括月收入、月支出、储蓄金额、贷款金额、信用评分、债务收入比、教育水平、就业状况、地区等个人财务属性。
创建时间:
2025-11-14
原始信息汇总
数据集概述
基本信息
- 数据集名称: Personal Finance ML Dataset
- 数据来源: Kaggle个人理财机器学习数据集
- 记录数量: 32,424条个人记录
主要特征
- 月收入
- 月支出
- 储蓄金额
- 贷款金额
- 信用评分
- 债务收入比
- 教育水平
- 就业状况
- 地区
- 其他个人理财属性
数据清洗过程
- 检查并处理缺失值
- 解析日期列并转换为正确的日期时间格式
- 验证无逻辑错误值(负年龄、负收入、无效信用评分范围)
- 检查重复行
- 确保分类值不包含拼写错误
- 将贷款相关字段中的不适用零值替换为NaN
探索性数据分析
统计分析
- 关键数值变量的统计分布分析
- 主要数值变量的直方图分析
- 变量间关系的相关性热图
- 用于检测异常值的箱线图分析
关键发现
- 收入、支出和储蓄等财务属性呈现右偏分布
- 支出、收入和储蓄之间存在中等程度的相关性
异常值检测
- 收入、支出、储蓄和贷款金额等财务变量显示强烈的右偏分布,存在许多高价值异常值
- debt_to_income_ratio列包含不切实际的极端值
- 年龄、credit_score和savings_to_income_ratio等更稳定的变量显示正态分布,异常值相对较少
关键分析结论
收入与支出关系
- 月收入与月支出之间存在明显的正相关关系
- 收入越高,支出倾向于增加
收入与储蓄关系
- 月收入与总储蓄之间存在强烈的正相关关系
- 高收入者倾向于显著增加绝对储蓄额
储蓄与信用评分关系
- 储蓄与信用评分之间没有有意义的关联
地区贷款率
- 各地区的贷款率几乎相同(39%-41%)
- 地区对贷款可能性没有显著影响
性别收入差异
- 不同性别的收入水平几乎相同
- 所有性别群体的月收入均约为4,000美元
收入与财务风险关系
- 高财务风险个体的收入显著较低
- 低收入与高财务风险密切相关
总体结论
收入是影响财务稳定性的主要因素。高收入个体倾向于支出更多、储蓄更多,并且通常表现出较低的财务风险水平。相比之下,性别和地区等因素仅显示最小差异,未得出有意义的见解。
搜集汇总
数据集介绍
构建方式
在个人金融分析领域,数据质量直接影响模型性能。该数据集源自Kaggle平台,通过合成方法生成32,424条个人财务记录,涵盖月收入、月支出、储蓄金额等核心维度。构建过程中采用系统化数据清洗流程,包括缺失值处理、日期格式标准化、异常值检测与逻辑校验,特别针对贷款相关字段的零值替换为NaN,确保数据真实性与分析有效性。
特点
该数据集呈现典型的个人金融数据特征,数值型变量如收入与支出呈现右偏分布,隐含社会经济分层现象。关键变量间存在适度相关性,例如收入与储蓄量的正向关联,而债务收入比字段则存在合成数据特有的极端值。值得注意的是,信用评分与储蓄量未显现显著相关性,区域与性别变量在贷款行为和收入分布上表现出高度均质化特征。
使用方法
针对机器学习建模需求,该数据集适用于监督学习与无监督学习任务。研究者可基于财务风险标签构建分类模型,或利用聚类算法探索客户分群模式。在使用过程中建议重点关注右偏分布的数值变量,通过对数变换改善模型性能,同时注意债务收入比字段的阈值设定。可视化分析表明,箱形图与相关热霾能有效揭示变量间潜在关系,为特征工程提供重要依据。
背景与挑战
背景概述
个人金融机器学习数据集作为金融科技领域的重要数据资源,其构建旨在通过合成数据模拟真实世界个人金融行为。该数据集由Kaggle平台于近年发布,汇集了涵盖收入、支出、储蓄、信贷等维度的32,424条个人金融记录,为研究个人金融风险预测与行为模式提供了量化基础。通过整合多维度金融属性,该数据集有效支撑了信用评估模型开发与金融决策支持系统的研究,推动了数据驱动型个人金融服务的发展。
当前挑战
在解决个人金融风险评估问题时,数据集需应对收入分布高度右偏、极端债务收入比等复杂金融特征带来的建模挑战。构建过程中面临合成数据与真实场景的语义鸿沟,包括异常值处理逻辑矛盾、分类变量一致性校验等数据质量控制难题,同时需平衡隐私保护与数据可用性的双重需求。
常用场景
经典使用场景
在个人金融分析领域,该数据集常被用于构建机器学习模型以预测个体财务风险水平。通过整合月收入、支出、储蓄及信用评分等多维特征,研究人员能够训练分类器识别高财务风险群体,为信贷评估和金融监管提供数据支撑。
实际应用
商业银行与金融科技机构借助该数据集开发智能风控系统,通过分析客户财务行为模式优化贷款审批流程。保险行业则利用其建立精准保费定价模型,同时政府监管部门可基于数据洞察制定更有效的普惠金融政策。
衍生相关工作
基于该数据集衍生的经典研究包括联邦学习框架下的隐私保护财务预测模型,以及结合图神经网络的多维度信用传播分析。这些工作不仅拓展了可解释AI在金融领域的应用边界,还催生了《IEEE金融数据分析》等国际期刊的特刊议题。
以上内容由遇见数据集搜集并总结生成


