joey234/mmlu-college_biology-neg-prepend-fix
收藏Hugging Face2023-08-21 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/joey234/mmlu-college_biology-neg-prepend-fix
下载链接
链接失效反馈官方服务:
资源简介:
---
configs:
- config_name: default
data_files:
- split: dev
path: data/dev-*
- split: test
path: data/test-*
dataset_info:
features:
- name: question
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
- name: negate_openai_prompt
struct:
- name: content
dtype: string
- name: role
dtype: string
- name: neg_question
dtype: string
- name: fewshot_context
dtype: string
- name: ori_prompt
dtype: string
splits:
- name: dev
num_bytes: 6719
num_examples: 5
- name: test
num_bytes: 417471
num_examples: 144
download_size: 14610
dataset_size: 424190
---
# Dataset Card for "mmlu-college_biology-neg-prepend-fix"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
提供机构:
joey234
原始信息汇总
数据集卡片 "mmlu-college_biology-neg-prepend-fix"
配置
- 默认配置
- 数据文件
- 开发集 (dev)
- 路径:
data/dev-*
- 路径:
- 测试集 (test)
- 路径:
data/test-*
- 路径:
- 开发集 (dev)
- 数据文件
数据集信息
-
特征
- 问题 (
question)- 数据类型: 字符串 (
string)
- 数据类型: 字符串 (
- 选项 (
choices)- 序列类型: 字符串 (
string)
- 序列类型: 字符串 (
- 答案 (
answer)- 数据类型: 类别标签 (
class_label)- 标签名称:
- 0: A
- 1: B
- 2: C
- 3: D
- 标签名称:
- 数据类型: 类别标签 (
- 否定开放AI提示 (
negate_openai_prompt)- 结构:
- 内容 (
content)- 数据类型: 字符串 (
string)
- 数据类型: 字符串 (
- 角色 (
role)- 数据类型: 字符串 (
string)
- 数据类型: 字符串 (
- 内容 (
- 结构:
- 否定问题 (
neg_question)- 数据类型: 字符串 (
string)
- 数据类型: 字符串 (
- 少量样本上下文 (
fewshot_context)- 数据类型: 字符串 (
string)
- 数据类型: 字符串 (
- 原始提示 (
ori_prompt)- 数据类型: 字符串 (
string)
- 数据类型: 字符串 (
- 问题 (
-
分割
- 开发集 (
dev)- 字节数: 6719
- 样本数: 5
- 测试集 (
test)- 字节数: 417471
- 样本数: 144
- 开发集 (
-
下载大小: 14610 字节
-
数据集大小: 424190 字节
搜集汇总
数据集介绍
构建方式
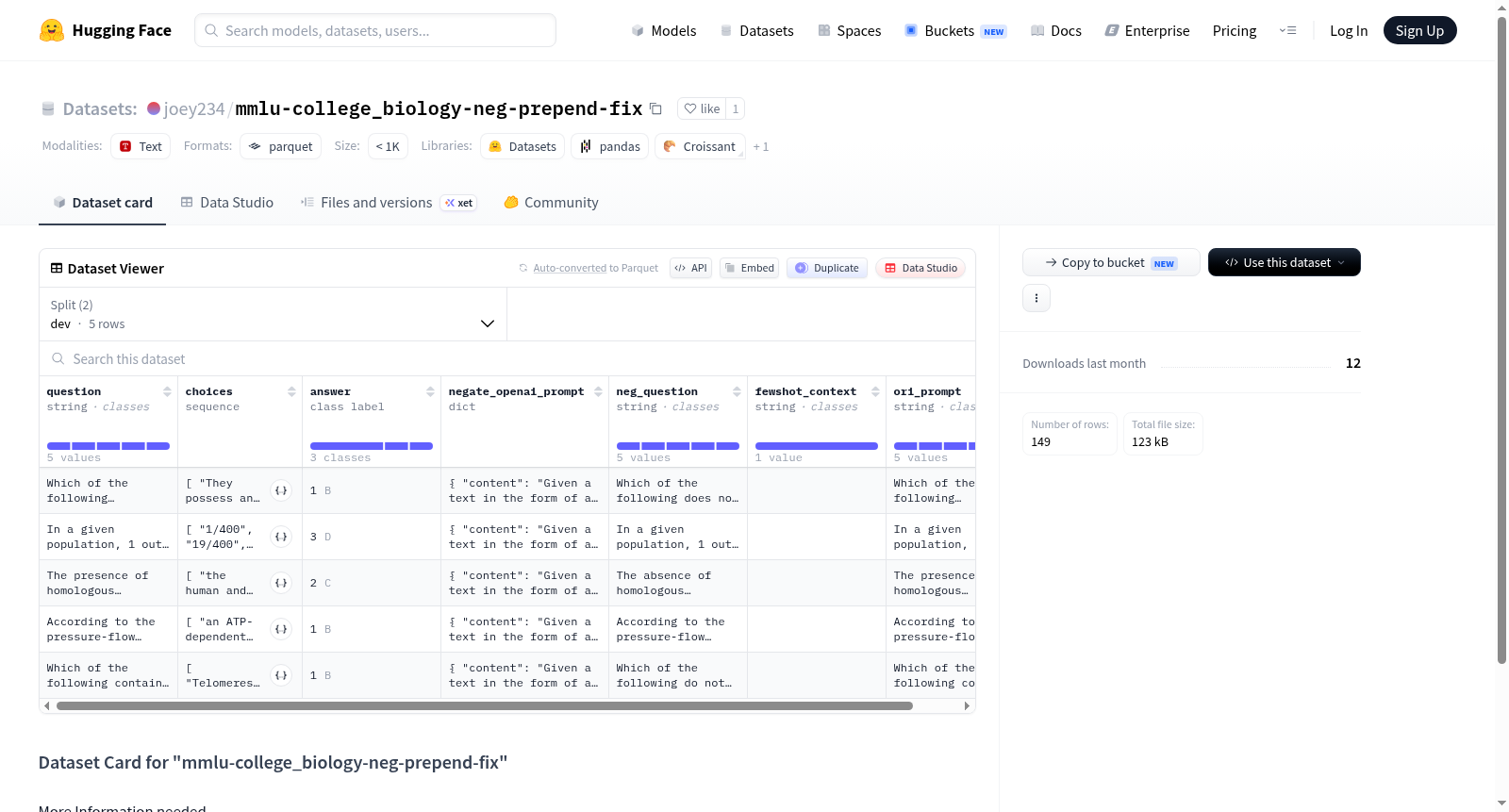
该数据集基于MMLU(Massive Multitask Language Understanding)基准测试中的大学生物学子集构建而成。通过将原始选择题的提问方式转化为否定前置的表述形式,并对OpenAI提示模板进行修正,形成了独特的负样本增强结构。数据集包含dev和test两个划分,其中dev集含5个样本用于调优,test集包含144个样本用于评估。每个样本保留原始问题、选项、答案标签,并额外添加了否定化的问题文本、修正后的提示模板以及少样本上下文信息。
使用方法
使用时可通过HuggingFace Datasets库直接加载,指定config_name为'default'即可获取dev和test两个拆分。适用于评估大语言模型在生物学领域否定推理任务上的性能,尤其适合对比模型在原始正向提问与否定前置提问下的准确率差异。建议使用neg_question字段作为输入,以answer字段中的类别标签(A-D)作为评估标准,同时可利用fewshot_context字段构建少样本学习场景。
背景与挑战
背景概述
大规模多任务语言理解(MMLU)基准测试自2020年由Dan Hendrycks等人提出以来,已成为评估语言模型在广泛知识领域内推理能力的重要标杆。该数据集聚焦于大学生物学子领域,旨在衡量模型对生物学核心概念、术语及逻辑关系的掌握程度。joey234/mmlu-college_biology-neg-prepend-fix作为MMLU的子集,由独立研究者Joey234于2023年发布,其核心研究问题在于修正原始数据集中否定前缀处理不当导致的语义偏差,以提升评估的科学性。通过引入否定词前置的标准化策略,该数据集为语言模型在专业学科(如分子生物学、生态学)中的鲁棒性测试提供了更精确的基准,对推动可信AI在教育与科研领域的应用具有关键影响。
当前挑战
该数据集面临的核心挑战首先源于领域问题的复杂性:大学生物学涵盖从细胞机制到生态系统动态的多元主题,要求模型不仅记忆事实,还需理解因果链条与实验设计逻辑,这对当前语言模型的深度推理能力构成显著考验。构建过程中,原始MMLU数据集的否定词(如“not”“except”)常因位置歧义导致模型误判,Joey234团队通过手动审查与算法校正,将否定词统一移至问题开头,但这一过程面临语义保真度的权衡——强制前置可能改变原句的隐含焦点,且需确保144个测试样本与5个开发样本的修正一致性,避免引入新的噪声。此外,数据集规模较小(仅149个总样本)限制了统计显著性,使得评估结果易受随机波动影响。
常用场景
经典使用场景
在自然语言处理与知识推理的交叉领域中,joey234/mmlu-college_biology-neg-prepend-fix数据集专为评估和提升大语言模型在大学生物学知识上的鲁棒性而设计。其经典使用场景聚焦于对抗性负样本测试,即通过引入否定前缀扰动(neg-prepend)来构造具有挑战性的题目变体,从而检验模型在语义反转或否定条件下的逻辑推理与事实检索能力。这一场景对于理解模型在复杂知识问答中的脆弱性具有重要价值,尤其适用于探测模型对否定词句的敏感度以及其在多选推理任务中的稳定性。
解决学术问题
该数据集的核心学术贡献在于解决了大语言模型在专业学科知识问答中面对否定表达时性能显著下降的普遍问题。传统评估基准如MMLU虽覆盖广泛,却忽略了语言变体对模型推理的干扰效应。通过系统性地对原始生物学问答进行否定前缀改造,该数据集揭示了模型在语义反转情境下的认知偏差,为研究语言模型的逻辑一致性、鲁棒性以及对抗性泛化能力提供了标准化测试平台。其意义在于推动学术界从单一准确率评估转向更全面的鲁棒性分析,促进模型在关键学科领域(如医学、生物学)中可信赖推理的发展。
实际应用
在实际应用层面,该数据集可被用于教育科技领域的智能辅导系统开发,例如用于构建能够识别并纠正学生常见误解的对话式学习助手。通过模拟否定性提问场景,系统可训练模型在解答生物学问题时忽略语义干扰,从而提升其作为虚拟教师或考试辅助工具的可靠性。此外,在自动出题与评估系统中,该数据集可指导生成具有区分度的对抗性试题,帮助识别学习者对概念掌握的深层薄弱环节。在生物信息学知识库的问答接口中,此类鲁棒性优化能有效减少因用户表述歧义导致的错误反馈,增强人机交互的实用效能。
数据集最近研究
最新研究方向
在人工智能与教育测评交叉领域,MMLU(大规模多任务语言理解)基准测试已成为评估大语言模型知识广度的标杆。针对College Biology子集的研究正聚焦于模型对否定性表述的鲁棒性,这一方向与当前大模型在科学推理中的脆弱性热点紧密相关。该数据集通过引入neg-prepend-fix机制,在生物学问题前系统性地添加否定前缀,旨在暴露模型在理解否定逻辑时的常见偏差。前沿研究不仅关注模型在标准多选题上的准确率,更深入探讨其在对抗性否定提示下的认知一致性,这对于提升AI在医学、科研等高风险领域的可信应用具有关键意义。相关热点事件包括近期多项研究揭示大模型在逻辑否定推理上的系统性缺陷,而该数据集为量化并缓解此类问题提供了标准化测试平台,推动了大模型从机械记忆向真正理解科学概念的演进。
以上内容由遇见数据集搜集并总结生成


