varshith7/income-tax-act-india
收藏Hugging Face2026-04-25 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/varshith7/income-tax-act-india
下载链接
链接失效反馈官方服务:
资源简介:
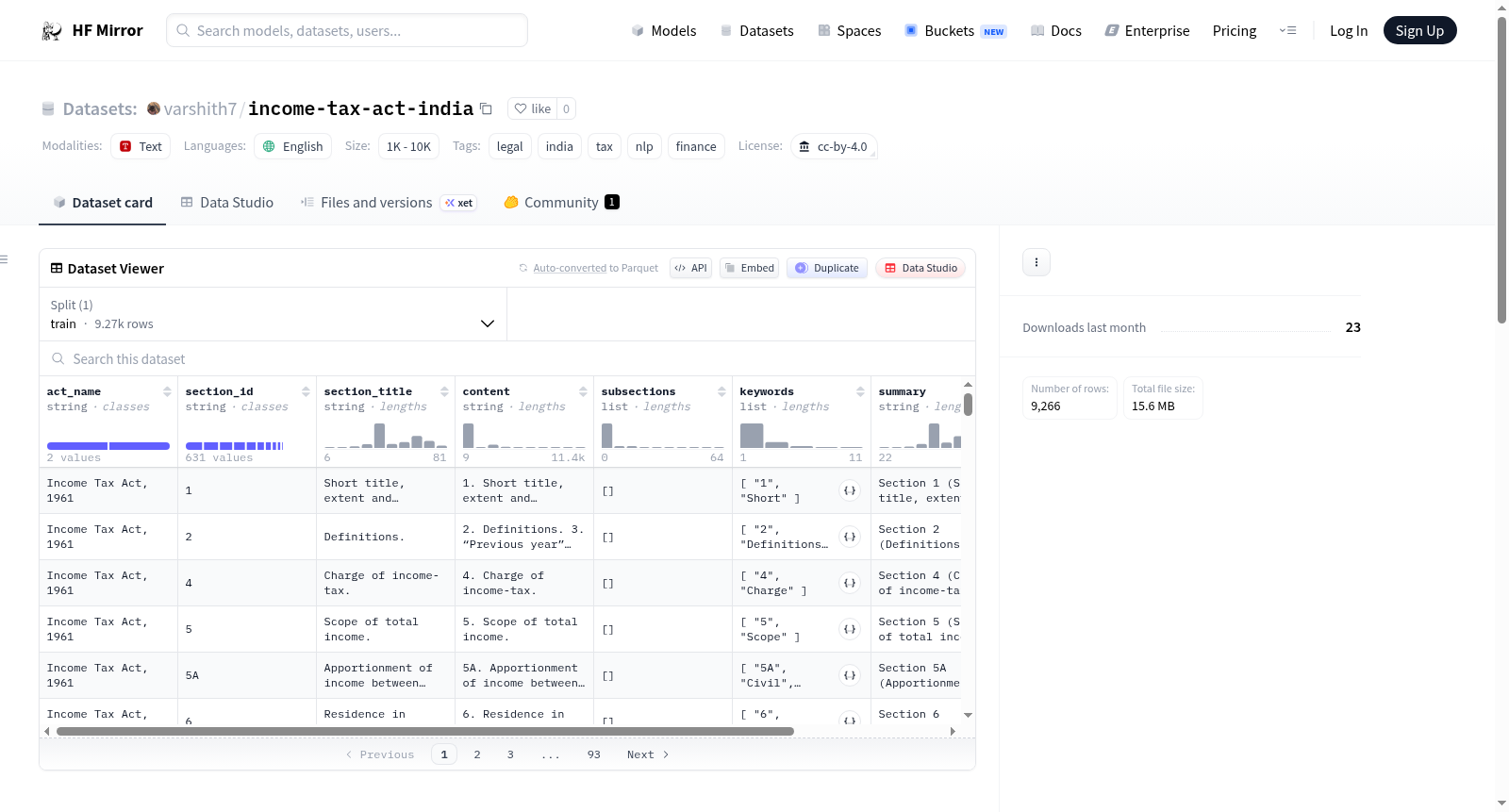
这是一个机器可读的、CA级别的印度所得税法结构化数据集。数据集包含解析和结构化的印度所得税法法律部分,已从官方PDF中处理提取出丰富的元数据,用于NLP任务、RAG应用和LLM微调。提供1961年法案的完整版本和2025年法案的结构占位符版本。数据以JSON格式提供,每个部分包含section_id、section_title、content等字段。适用于法律文档检索(RAG)、财务合规AI代理和复杂税法的摘要等使用案例。
A machine-readable, CA-level structured dataset of the Indian Income Tax Act. The dataset contains the parsed and structured legal sections of the Income Tax Act of India, processed from the official PDFs to extract rich metadata for use in NLP tasks, RAG applications, and LLM fine-tuning. It includes the complete 1961 Act and a structural placeholder for the 2025 Act. The data is provided in JSON format, with each section containing fields such as section_id, section_title, and content. Suitable for use cases like legal document retrieval (RAG), financial compliance AI agents, and summarization of complex tax law.
提供机构:
varshith7
搜集汇总
数据集介绍
构建方式
该数据集源自印度政府官方PDF文件,通过解析和结构化处理,将《印度所得税法》的法律条文转化为机器可读的JSON格式。每个条目包含章节标识符、标题、完整法律文本、子章节列表、自动生成的关键金融/法律实体以及摘要信息。数据集涵盖1961年法案及2025年法案(后者为结构性占位符,待正式版本整合),规模在1千至1万条之间。
特点
数据集具有高结构化与丰富元数据的特点,专为自然语言处理任务设计。其C级精度的法律文本解析确保了专业适用性,而自动提取的关键词和摘要则便于快速检索与理解。此外,数据集支持跨版本对比,可服务于法律文档检索、金融合规AI代理及复杂税法摘要等场景。
使用方法
适用于基于检索增强生成的法律文档检索、面向金融合规的智能代理开发以及税法条文摘要等下游任务。用户可直接加载JSON格式数据,利用章节标识符与元数据进行高效索引,或结合大语言模型进行微调,以提升在印度税务法律领域的专业问答与信息提取能力。
背景与挑战
背景概述
在自然语言处理与法律科技交叉领域,结构化法律数据的稀缺始终制约着智能法律应用的发展。印度作为全球重要的新兴经济体,其所得税法的数字化解析对于税务合规自动化具有深远意义。该数据集由相关研究机构基于印度政府官方出版物加工而成,于近期发布,提供了1961年及2025年两个版本的印度所得税法结构化内容,涵盖章节标识、标题、全文、子节映射、关键财务法律实体以及摘要等丰富元数据。该数据集的问世,旨在为法律文档检索、金融合规AI代理以及复杂税法摘要等下游任务提供高质量的语料基础,有望推动税务领域的检索增强生成(RAG)与大型语言模型微调技术取得实质性进展。
当前挑战
该数据集所解决的核心领域挑战在于,印度所得税法体系庞大、条文繁复,传统上依赖专家人工解读,而机器可读的结构化数据长期缺失,严重阻碍了自动化合规与智能税务助手的发展。构建过程中面临多重困难:首先,官方PDF文档格式非一致且包含大量交叉引用,解析时需精确识别章节层级与嵌套关系;其次,法律文本中的专业术语与复杂逻辑结构(如条件豁免、计算门槛)增加了元数据自动提取的难度;最后,2025年版本尚未完成全面整合,当前仅作为结构占位符存在,数据时效性与完整性的动态维护构成持续性挑战。
常用场景
经典使用场景
在自然语言处理与法律智能的交叉领域中,结构化法律文本的深度解析一直是研究难点。该数据集将印度《所得税法》1961版与2025版的法律条文转化为机器可读的JSON格式,每个条款均包含章节标识、标题、全文、子条款映射、自动提取的关键词以及摘要信息。它最经典的使用场景在于法律文档的检索增强生成(RAG)系统——研究者可基于该数据集构建高效的法律条文向量数据库,当用户提出税务咨询时,系统能精准定位相关法条并生成合乎逻辑的解释,从而大幅提升法律信息检索的准确性与时效性。
衍生相关工作
该数据集已催生了一系列富有影响力的衍生研究工作。基于其结构化特性,研究者开发了面向印度税法的知识图谱构建框架,将各条款间的关联、援引与修订历史实体化,形成可推理的法条关系网络。另有团队利用其摘要字段训练了专门的税法文本压缩模型,在保持法律语义完整性的前提下实现高效的内容凝练。此外,该数据集还被用于测试跨语言法律迁移学习,探索将印度税法中蕴含的英联邦法律逻辑范式应用于其他国家的税法解析任务,推动法律人工智能在全球化背景下的知识共享与范式创新。
数据集最近研究
最新研究方向
该数据集为印度所得税法(1961年及2025年版本)的结构化解析,属于法律自然语言处理(Legal NLP)与金融合规人工智能领域的前沿资源。近期研究方向聚焦于利用该数据集构建检索增强生成(RAG)系统,以支持税务法律问答、复杂法律条文摘要及自动化合规审查。结合印度政府推进数字化治理与税法改革的热点事件,该数据集为开发面向税务从业者的AI代理提供了高质量语料,助力提升法律文本的可访问性与理解效率,对推动法律科技与金融智能化的交叉研究具有重要价值。
以上内容由遇见数据集搜集并总结生成


