TSEC-Dataset
收藏github2024-05-20 更新2024-05-31 收录
下载链接:
https://github.com/haopenghui/TSEC-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
TSEC-Dataset是为训练和测试驾驶场景视频字幕方法而开发的,旨在描述自我车辆、道路环境和其他交通参与者的关键事件。数据集通过选择不同的视频来源,包括车载摄像头、公共数据集视频以及从BiliBili和Youtube下载的交通事故视频,来获取多样化的交通场景。视频被分割成包含1到3个关键事件的独立片段,总计8,000个视频片段,总时长11.5小时。
The TSEC-Dataset is developed for training and testing video captioning methods in driving scenarios, aiming to describe key events involving the ego vehicle, road environment, and other traffic participants. The dataset captures diverse traffic scenes by selecting various video sources, including in-car cameras, videos from public datasets, and traffic accident videos downloaded from BiliBili and YouTube. The videos are segmented into independent clips containing 1 to 3 key events, totaling 8,000 video clips with a combined duration of 11.5 hours.
创建时间:
2024-05-20
原始信息汇总
TSEC-Dataset概述
数据集目的
TSEC-Dataset旨在为驾驶场景的视频字幕方法提供训练和测试数据。该数据集专注于描述自我车辆、道路环境和其他交通参与者的关键事件。
数据集内容
- 视频来源:使用车载摄像头拍摄的视频、其他公共数据集视频、以及从BiliBili和Youtube下载的交通事故视频。
- 视频处理:视频被分割成包含1至3个关键事件的子片段。
- 视频特性:包含不同天气、时间段、道路条件和车辆条件的多样化场景,特别选择了多个交叉口场景。
- 视频数量和时长:共8,000个视频片段,总时长11.5小时。
数据集标注
- 标注方法:参与者模拟驾驶体验,观看无字幕的原始视频,并通过投票方法确定场景中的关键事件类型。
- 关键事件:每段视频识别出票数最高的四个关键事件进行详细标注。
获取方式
- 使用限制:仅供研究和私人学习使用。
- 请求流程:通过电子邮件(haopenghui2022@gmail.com)请求,需提供数据库使用描述和签署的协议副本。
- 用户资格:必须是合法机构或其部门,学术请求需使用大学邮箱,并由教授或正式员工签名。
使用条款
- 隐私保护:如发现个人或车辆信息,请联系数据集提供者进行删除。
- 版权信息:数据集版权归山东大学计算机视觉与模式识别实验室所有,遵循Creative Commons Attribution-NonCommercial-ShareAlike 4.0 License。
搜集汇总
数据集介绍
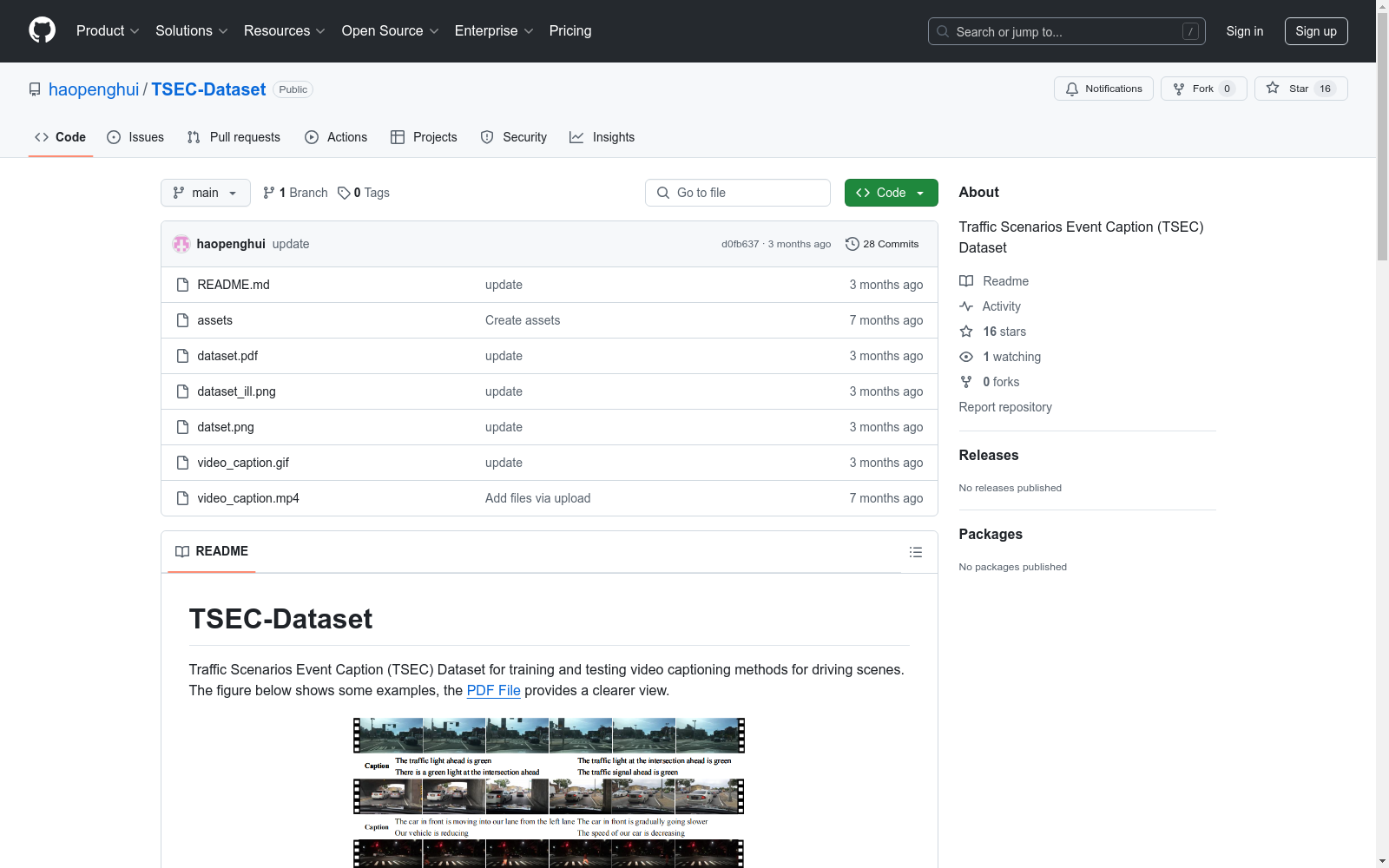
构建方式
为了应对驾驶场景中视频描述任务的特殊需求,TSEC-Dataset通过整合多种来源的视频数据构建而成。研究团队首先采集了车载摄像头拍摄的视频,并结合公开数据集和从BiliBili、Youtube等平台获取的交通事故视频。为确保数据的多样性和代表性,视频片段在处理时遵循了多重规则,包括选择不同天气、时段、路况和车辆状态的场景,以及包含完整事件的片段。此外,复杂交通情况如交叉路口的场景也被纳入其中。最终,数据集包含了8,000个视频片段,总时长为11.5小时。
特点
TSEC-Dataset的显著特点在于其针对驾驶场景的精细化设计。数据集不仅涵盖了多种交通事件,如车辆状态、道路环境和交通参与者行为,还通过随机化视频顺序和投票机制减少了标注的主观性。此外,数据集的多样性体现在不同天气、时段、路况和车辆状态的场景中,使其成为训练和测试视频描述方法的理想选择。
使用方法
TSEC-Dataset的获取需通过电子邮件向指定地址发送请求,邮件中需详细描述数据集的预期用途,并附上签署的协议文件。数据集仅限于学术研究和私人学习使用,不得用于商业目的。下载链接将通过邮件提供,且请求可能会被拒绝。使用时需遵守版权和隐私条款,确保对原始作者的归属,并遵循非商业性使用和共享许可。
背景与挑战
背景概述
随着自动驾驶技术的迅猛发展,对驾驶场景的理解与描述成为关键研究方向。TSEC-Dataset由山东大学计算机视觉与模式识别实验室开发,旨在为驾驶场景的视频字幕生成提供高质量的数据支持。该数据集创建于近期,汇集了通过车载摄像头、公开数据集以及从Bilibili和YouTube下载的交通事故视频,经过精心剪辑与标注,形成了包含8,000个视频片段、总时长11.5小时的多样化驾驶场景数据集。其核心研究问题在于如何准确描述自车、道路环境及其他交通参与者的关键事件,为视频字幕生成方法的训练与测试提供了独特的资源。
当前挑战
TSEC-Dataset在构建过程中面临多重挑战。首先,驾驶场景的复杂性要求数据集涵盖不同天气、时段、路况及车辆状态,以确保多样性和代表性。其次,交通事件的主观性使得标注过程需要通过投票机制来确定关键事件类型,增加了标注的复杂性。此外,数据集的隐私与版权问题也需严格管理,确保仅用于学术研究,并保护个人与车辆信息的安全。这些挑战不仅反映了数据集构建的技术难度,也凸显了其在推动自动驾驶领域研究中的重要性。
常用场景
经典使用场景
TSEC-Dataset在自动驾驶和智能交通领域中,被广泛用于训练和测试视频字幕生成模型,以描述驾驶场景中的关键事件。该数据集通过分割原始视频为多个子片段,每个子片段关联1至3个关键事件,从而提供了丰富的交通场景描述。这种设计使得模型能够更好地理解和生成与驾驶环境相关的自然语言描述,为自动驾驶系统提供了重要的语义信息支持。
实际应用
在实际应用中,TSEC-Dataset可用于开发和优化自动驾驶系统的感知模块,帮助车辆更好地理解复杂的交通环境。例如,通过分析数据集中的事件描述,自动驾驶系统可以更准确地识别和预测其他交通参与者的行为,从而提高驾驶安全性。此外,该数据集还可用于智能交通管理系统的开发,提升交通监控和事件响应的效率。
衍生相关工作
基于TSEC-Dataset,研究者们开发了多种视频字幕生成模型,并在自动驾驶和智能交通领域取得了显著进展。例如,一些研究工作利用该数据集训练深度学习模型,以生成更精确的交通事件描述,从而提升自动驾驶系统的决策能力。此外,该数据集还激发了关于多模态数据融合的研究,探索如何将视频信息与自然语言描述相结合,以实现更智能的交通系统。
以上内容由遇见数据集搜集并总结生成


