label-test
收藏Hugging Face2025-11-30 更新2025-12-01 收录
下载链接:
https://huggingface.co/datasets/carlcode/label-test
下载链接
链接失效反馈官方服务:
资源简介:
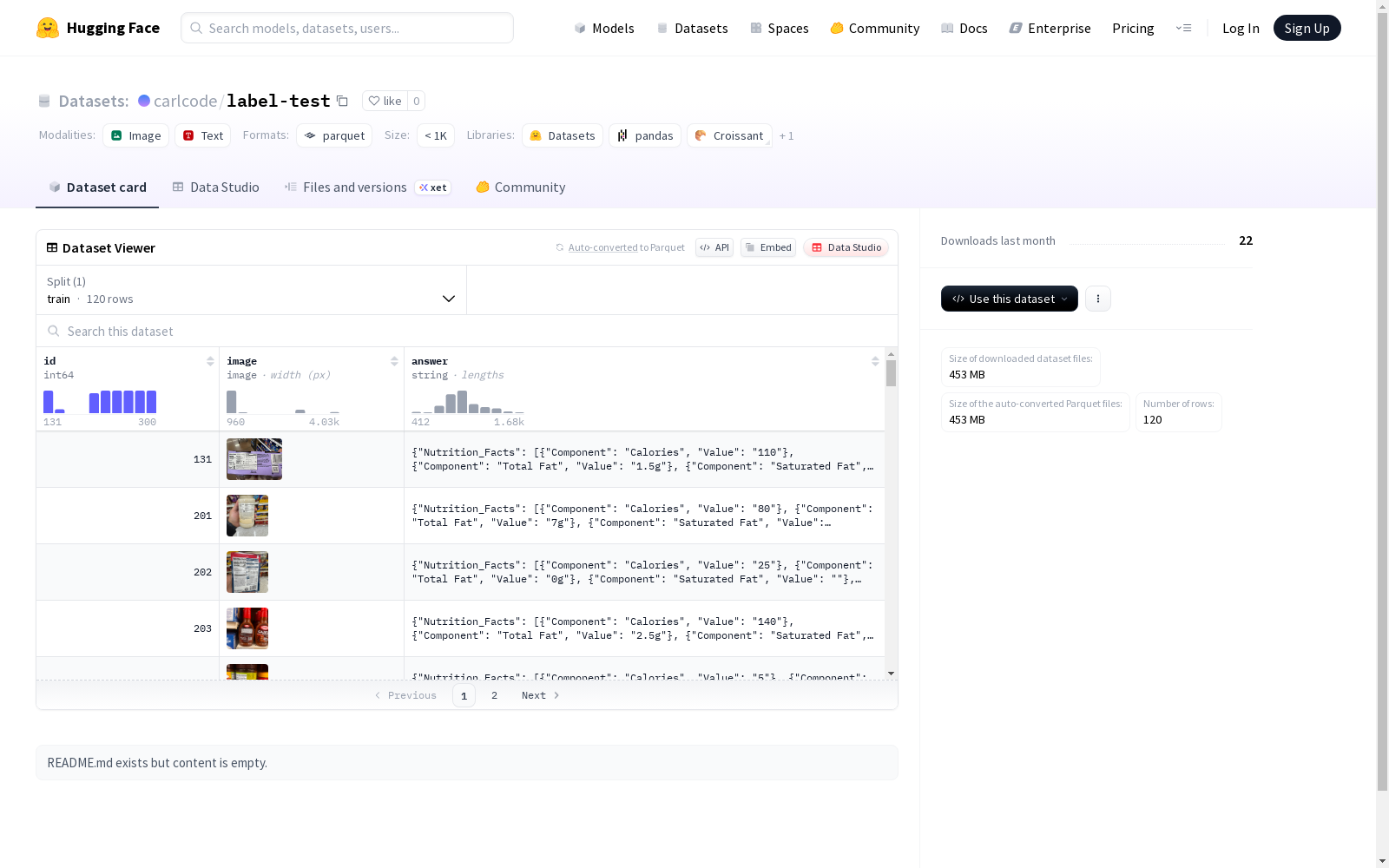
该数据集包含三个字段:id(整型)、image(图片)和answer(字符串)。数据集被划分为训练集,共有110个示例,总大小为342,367,918字节。
创建时间:
2025-11-30
原始信息汇总
数据集概述
基本信息
- 数据集名称: label-test
- 发布者: carlcode
- 存储位置: https://huggingface.co/datasets/carlcode/label-test
数据特征
- 特征字段:
- id (int64类型)
- image (image类型)
- answer (string类型)
数据规模
- 训练集:
- 样本数量: 110
- 数据集大小: 342,367,918字节
- 下载大小: 339,751,602字节
文件结构
- 默认配置:
- 训练集文件路径: data/train-*
搜集汇总
数据集介绍
构建方式
在视觉语言多模态研究领域,label-test数据集的构建采用了结构化数据采集流程。该数据集通过整合图像与文本标注信息,形成了包含110个训练样本的标准化集合。每个样本由唯一标识符、图像数据及对应的文本答案构成,原始数据经过格式统一与质量校验后,以分块存储技术组织成训练集,总数据量约342MB,体现了多模态数据协同构建的典型方法。
特点
该数据集展现出鲜明的多模态特性,其核心特征在于图像与文本答案的紧密耦合。数据集包含整型标识、图像像素矩阵和字符串答案三类结构化特征,所有样本均通过严格的数值类型定义确保数据一致性。训练集以高密度方式存储,单个样本平均达3MB,这种设计既保留了图像原始信息,又通过轻量级文本标注实现了高效的多模态关联,为视觉问答任务提供了精准的语义对齐基础。
使用方法
基于其标准化存储结构,使用者可通过配置默认数据路径直接加载训练集。数据文件采用分块存储模式,支持流式读取与批量处理。在实际应用中,研究者可调用图像解码器解析像素数据,同时结合文本答案字段构建端到端的视觉语言模型。该数据集适用于监督学习框架,通过特征提取与跨模态注意力机制,能够有效支撑图像理解与语义推理任务的模型训练与验证。
背景与挑战
背景概述
随着人工智能在视觉与语言交叉领域的深入发展,多模态数据集成为推动模型理解复杂场景的关键工具。label-test数据集作为该领域的重要资源,由研究团队精心构建,旨在探索图像与文本答案之间的语义关联。该数据集通过整合视觉信息和对应的自然语言响应,为核心研究问题——即多模态语义对齐与推理——提供了实证基础,对促进视觉问答及跨模态理解技术的发展具有显著影响力。
当前挑战
在视觉问答领域,模型需克服图像内容多样性与答案生成一致性的挑战,例如处理模糊场景或抽象概念的准确解析。构建label-test数据集时,研究人员面临数据采集与标注的复杂性,包括确保图像质量与答案的相关性,以及处理大规模多模态数据存储与高效访问的技术难题,这些因素共同增加了数据集的创建与维护成本。
常用场景
实际应用
在智能教育系统和辅助医疗诊断中,该数据集支撑的视觉问答技术可实现自动化图像解读。例如在医学影像分析中,模型能根据X光片生成病理描述,大幅提升诊断效率;在盲人辅助设备领域,则能实时转换视觉信息为语音指导。
衍生相关工作
基于该数据集衍生的经典工作包括多模态预训练框架VL-BERT和视觉语言导航系统ViLBERT。这些模型通过联合学习视觉概念与语言语义,开创了跨模态注意力机制新范式,为后续的CLIP、ALBEF等融合模型奠定了理论基础。
以上内容由遇见数据集搜集并总结生成


