greenadntan/child-welfare-outcomes-institutional-vs-homebased
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/greenadntan/child-welfare-outcomes-institutional-vs-homebased
下载链接
链接失效反馈官方服务:
资源简介:
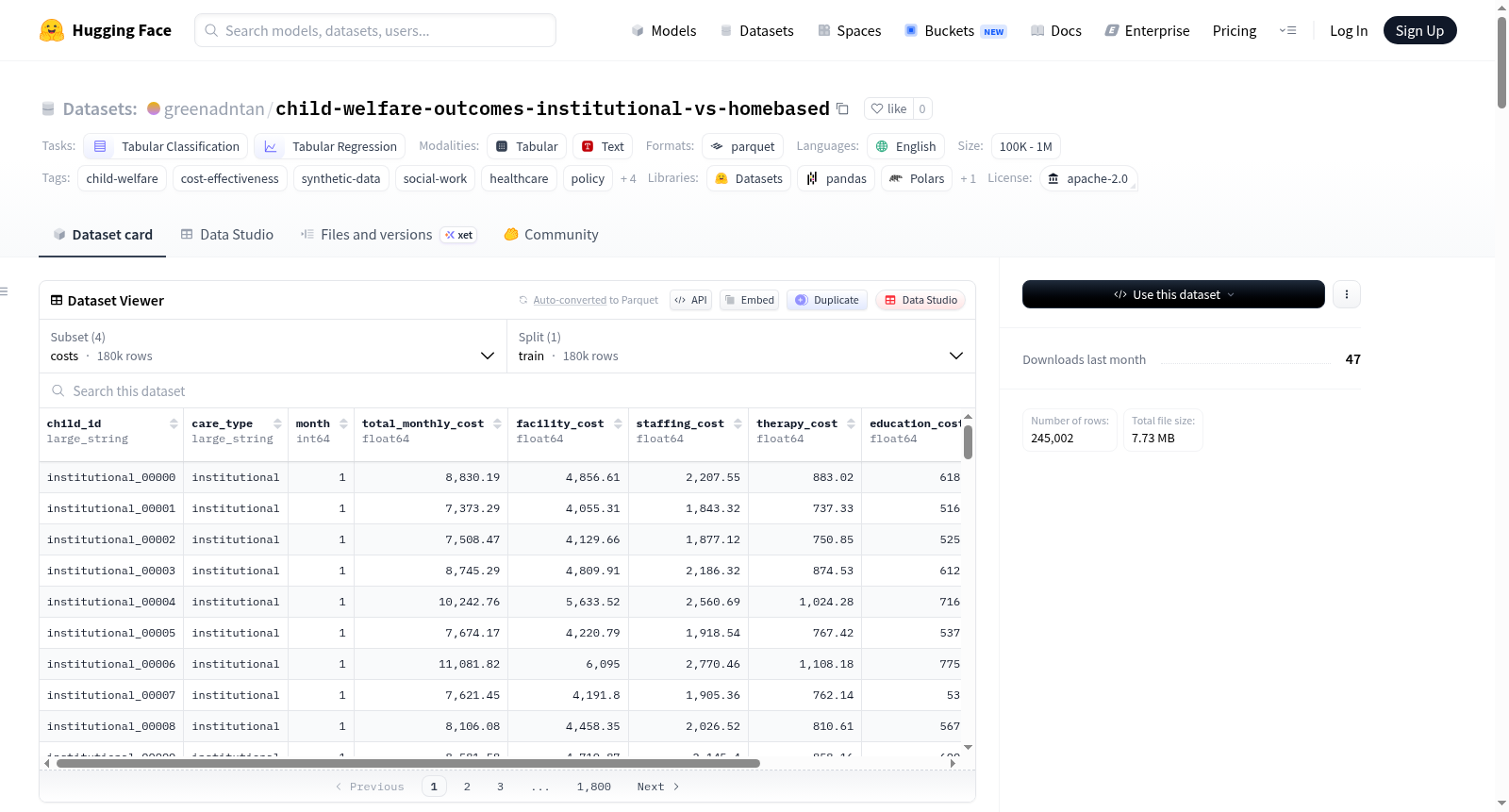
这是一个合成的纵向数据集,比较了机构/寄宿护理与家庭专业亲近(HBPN)之间的儿童福利结果。HBPN是一种家庭干预模式,由训练有素的专业人员在家庭环境中提供密集支持。数据集反映了儿童福利研究中的“两倍成功率”发现:家庭专业护理中的儿童在显著降低的成本下,实现了大约两倍的安置成功率。数据集包含四个子集:儿童级最终结果(outcomes)、季度纵向记录(trajectories)、月度成本明细(costs)和聚合程序统计(summary)。此外,还包括两个XGBoost模型:成功分类器和成本效益回归器。数据集适用于政策建模、成本效益分析、机器学习方法开发和教育目的,但不适用于临床决策。
Synthetic longitudinal dataset comparing child welfare outcomes between institutional/residential care and home-based professional nearness (HBPN) — a family-based intervention model where trained professionals provide intensive support within a home setting. This dataset preserves the well-documented twice the success rate finding from decades of child welfare research: children in home-based professional care achieve approximately 2× the placement success rate of those in institutional settings, at substantially lower cost. The dataset includes four configurations: child-level final outcomes (outcomes), quarterly longitudinal records (trajectories), monthly cost breakdown (costs), and aggregate program statistics (summary). It also includes two XGBoost models: a success classifier and a cost-effectiveness regressor. Suitable for policy modeling, cost-effectiveness analysis, ML method development, and educational purposes, but not for clinical decisions.
提供机构:
greenadntan
搜集汇总
数据集介绍
构建方式
该数据集为合成纵向数据,旨在对比机构照护与家庭本位专业亲近模式下的儿童福利效果。构建流程首先基于美国儿童福利人口统计分布,抽样生成人口学特征,进而采用S型增长曲线模拟个体在三年内每季度的认知、行为与依恋轨迹,并引入回归事件与安置中断建模。成本数据则以对数正态分布生成月度明细,涵盖设施、人员、治疗、教育及行政开支,并对HBPN模式施加阶梯下降模型。最终结局标签通过逻辑回归模型校准,确保机构照护与HBPN的成功率分别稳定在32%与64%附近,同时保留个体协变量的异质性效应。
特点
该数据集的核心特点在于其内置了多项与文献校准一致的实证发现:HBPN相比机构照护可实现约两倍的安置成功率(63.8% vs 32.3%),同时降低70%的三年总成本,每健康福祉点的成本效益提升4.43倍。数据集还反映了HBPN在IQ增益、行为改善与依恋提升方面的显著优势,增量成本效果比显示其为绝对占优策略。此外,数据集包含四个配置模块——儿童结局、季度轨迹、月度成本与项目汇总——支持多层次分析,并附带预训练的XGBoost分类与回归模型,揭示照护类型是预测成功与成本效益的最重要特征。
使用方法
用户可通过Hugging Face的datasets库快速加载该数据集,调用load_dataset函数并指定配置名称(outcomes、trajectories、costs或summary)即可获取对应的Parquet格式数据。加载后的数据可转换为pandas DataFrame进行分组统计,例如计算不同照护类型的平均成功率。预训练模型位于models目录下,Success Classifier用于预测安置成功率,Cost-Effectiveness Regressor用于预测每健康福祉点成本,用户可直接应用于政策建模、成本效益分析或机器学习方法开发等场景。
背景与挑战
背景概述
该数据集由研究者greenadntan于2026年创建,聚焦儿童福利领域中机构养育与家庭式专业照护(Home-Based Professional Nearness, HBPN)的成效对比。基于布加勒斯特早期干预项目、MTFC俄勒冈研究等经典文献校准,核心研究问题在于探究不同照护模式对儿童认知、行为、依恋及成本效益的长期影响。数据集通过合成技术再现了家庭式照护成功率约为机构照护两倍(63.8%对32.3%)、成本降低70%的关键发现,为儿童福利政策建模、成本效果分析及机器学习方法开发提供了标准化研究基准,在实证研究与数据驱动决策间架起桥梁。
当前挑战
该领域核心挑战在于机构照护与家庭式照护的比较长期被混杂变量和选择偏倚困扰,真实世界中儿童分配非随机化,使得因果推断困难。数据集通过合成校准方法部分规避此问题,但构建中面临诸多技术挑战:如何从经典文献中提取精确效应量并转化为参数化生成模型,如何模拟儿童个体发育轨迹的非线性增长、突发危机事件对成本的异常冲击,同时保持32%与64%目标成功率的全局校准。此外,数据需兼顾结构化跨度(从个体层面到季度纵向记录到月度成本明细)与多维度指标(认知、行为、依恋、教育投入、成本效益)的协调一致,对生成框架的稳健性要求极高。
常用场景
经典使用场景
该数据集的核心用途在于对比机构照护与家庭型专业照护两种儿童福利模式的成效差异,尤其聚焦于安置成功率、心理发展、行为改善及成本效益等关键指标。研究者可借此构建分类与回归模型,如预测安置是否成功或每福祉点成本,从而评估不同照护方式的干预效果。数据集提供的纵向轨迹与成本明细记录,还支持时间序列分析与增量成本效益比计算,为儿童福利领域的政策仿真与干预方案优化提供了坚实的量化基础。
衍生相关工作
该数据集衍生的经典工作包括基于XGBoost的安置成功分类器与成本效益回归模型,前者以照护类型为最强预测因子(特征重要性达49%),后者则揭示了照护模式对成本效益的绝对主导作用(重要性93%)。这些模型可扩展为儿童福利决策支持系统的核心组件,例如结合因果推断方法识别家庭型照护效果的异质性,或与强化学习结合动态优化照护分配策略。此外,数据的合成生成方法本身也为隐私受限的社会科学领域提供了高效的仿真数据范例,推动了合成数据在政策分析中的规范化应用。
数据集最近研究
最新研究方向
当前,儿童福利领域的前沿研究方向正聚焦于家庭式专业照护(HBPN)与机构寄养模式的对比评估,该数据集精准呼应了这一热点。近年来,受布加勒斯特早期干预项目、MTFC俄勒冈研究等里程碑式成果的推动,关于家庭环境对儿童认知、行为及依恋发展深远影响的实证积累日益丰厚。数据内置的关键发现表明,HBPN模式不仅将安置成功率提升至机构照护的约两倍,更在36个月周期内实现人均21万美元以上的成本节约,同时带来IQ增益超10分、行为改善近5倍的显著优势。这一合成数据集通过校准真实研究分布,为政策建模、成本效益分析及机器学习方法开发提供了标准化基准,尤其增量成本效益比(ICER)的负值验证了HBPN的绝对主导地位,对推动儿童福利体系从机构化向去机构化转型具有重要的决策支撑意义。
以上内容由遇见数据集搜集并总结生成


