有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
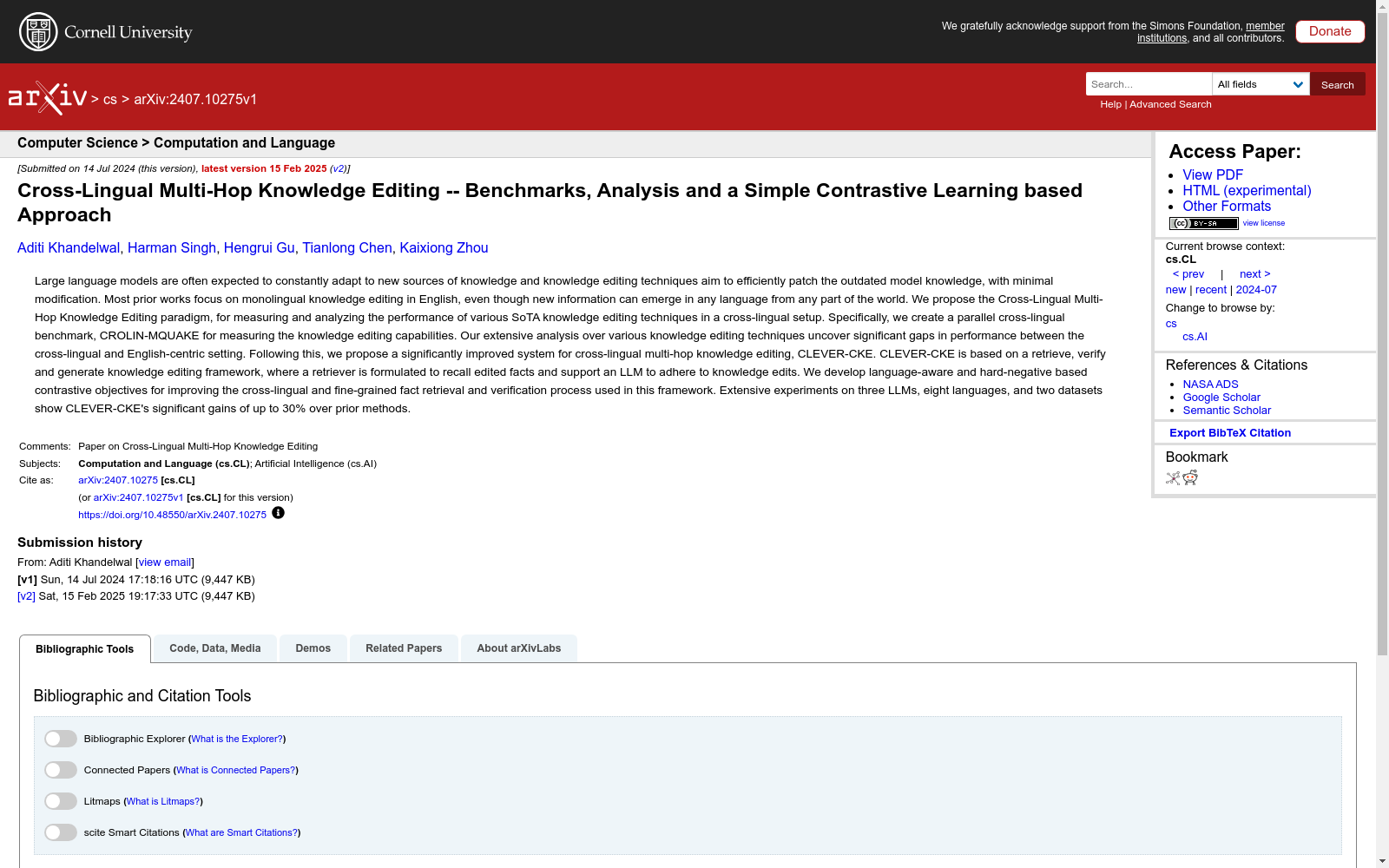
典型分布式光伏出力预测数据集
光伏电站出力数据每5分钟从电站机房监控系统获取;气象实测数据从气象站获取,气象站建于电站30号箱变附近,每5分钟将采集的数据通过光纤传输到机房;数值天气预报数据利用中国电科院新能源气象应用机房的WRF业务系统(包括30TF计算刀片机、250TB并行存储)进行中尺度模式计算后输出预报产品,每日8点前通过反向隔离装置推送到电站内网预测系统。
国家基础学科公共科学数据中心 收录
中国交通事故深度调查(CIDAS)数据集
交通事故深度调查数据通过采用科学系统方法现场调查中国道路上实际发生交通事故相关的道路环境、道路交通行为、车辆损坏、人员损伤信息,以探究碰撞事故中车损和人伤机理。目前已积累深度调查事故10000余例,单个案例信息包含人、车 、路和环境多维信息组成的3000多个字段。该数据集可作为深入分析中国道路交通事故工况特征,探索事故预防和损伤防护措施的关键数据源,为制定汽车安全法规和标准、完善汽车测评试验规程、
北方大数据交易中心 收录
HazyDet
HazyDet是由解放军工程大学等机构创建的一个大规模数据集,专门用于雾霾场景下的无人机视角物体检测。该数据集包含383,000个真实世界实例,收集自自然雾霾环境和正常场景中人工添加的雾霾效果,以模拟恶劣天气条件。数据集的创建过程结合了深度估计和大气散射模型,确保了数据的真实性和多样性。HazyDet主要应用于无人机在恶劣天气条件下的物体检测,旨在提高无人机在复杂环境中的感知能力。
arXiv 收录
CAP-DATA
CAP-DATA数据集由长安大学交通学院的研究团队创建,包含11,727个交通事故视频,总计超过2.19百万帧。该数据集不仅标注了事故发生的时间窗口,还提供了详细的文本描述,包括事故前的实际情况、事故类别、事故原因和预防建议。数据集的创建旨在通过结合视觉和文本信息,提高交通事故预测的准确性和解释性,从而支持更安全的驾驶决策系统。
arXiv 收录
GME Data
关于2021年GameStop股票活动的数据,包括每日合并的GME短期成交量数据、每日失败交付数据、可借股数、期权链数据以及不同时间框架的开盘/最高/最低/收盘/成交量条形图。
github 收录