BIHAR-SIR-data
收藏github2025-08-31 更新2025-09-02 收录
下载链接:
https://github.com/avs20/BIHAR-SIR--data-
下载链接
链接失效反馈官方服务:
资源简介:
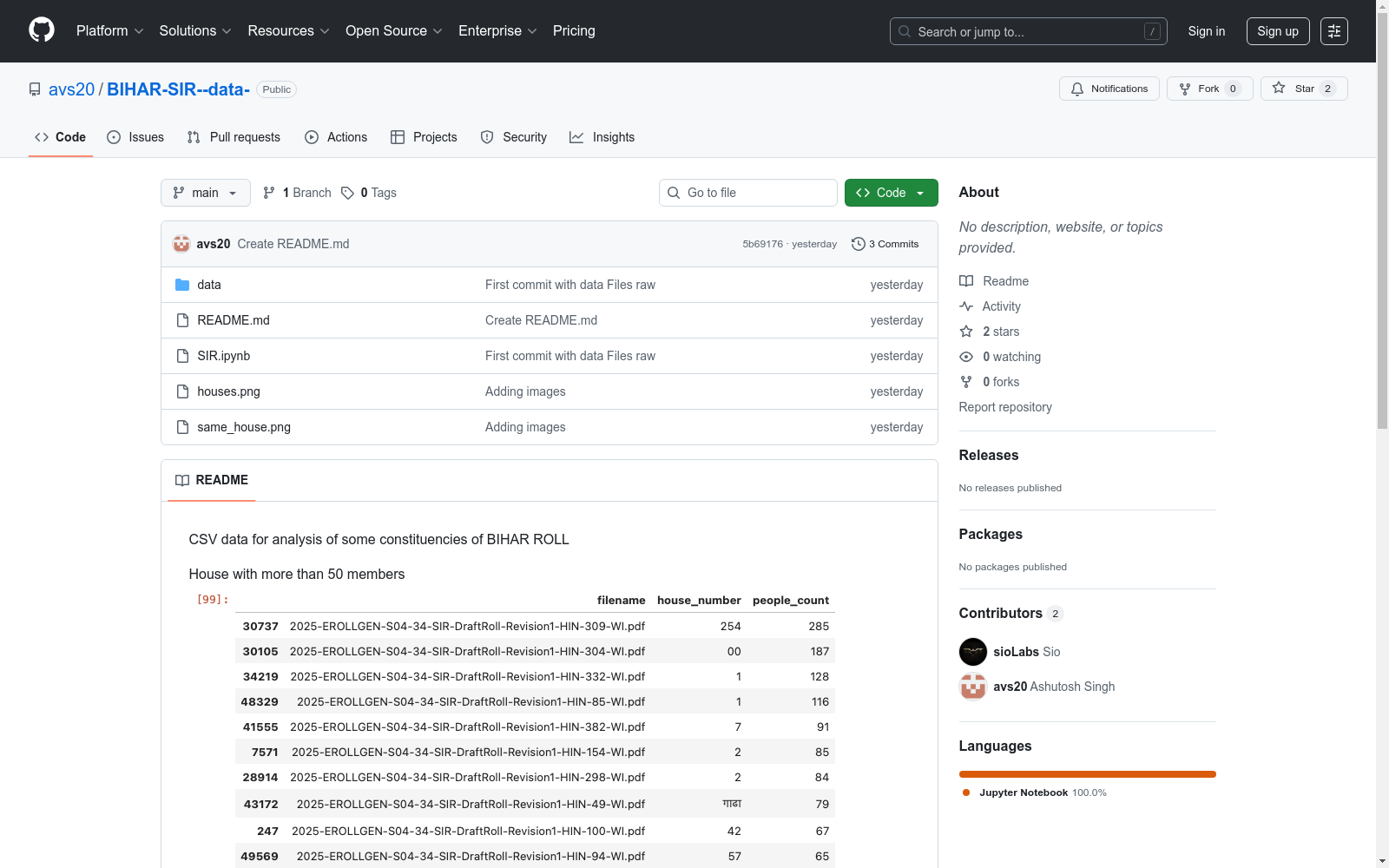
用于分析比哈尔邦某些选区选举名册的CSV数据,包含超过50名成员的房屋数据以及相同房屋编号的样本文件
This CSV dataset is intended for analyzing the electoral rolls of specific constituencies in Bihar, encompassing household data with over 50 members and sample files with identical household numbers.
创建时间:
2025-08-31
原始信息汇总
数据集概述
数据集名称
BIHAR-SIR--data-
数据内容
- 包含比哈尔邦(BIHAR)部分选区选民名册分析的CSV数据
- 重点关注成员数量超过50人的家庭(House)
- 提供相同门牌号(house numbers)的示例文件
文件说明
- 主数据文件:CSV格式
- 辅助文件:
- 成员超过50人的家庭示意图:houses.png
- 相同门牌号示例文件示意图:same_house.png
数据特征
- 地理范围:印度比哈尔邦特定选区
- 分析重点:选民名册中的家庭规模分布及门牌号重复情况
来源说明
数据源自比哈尔邦选民名册的官方记录分析。
搜集汇总
数据集介绍
构建方式
在印度比哈尔邦选举数据分析领域,该数据集通过系统采集特定选区的选民名册信息构建而成。数据源来自官方公开的选举登记资料,采用结构化方法整理选民居住地址与家庭关联信息。构建过程中特别关注同一住宅内多名选民的登记情况,确保数据能够反映家庭单位的选举参与模式。数据集以CSV格式保存,便于直接进行统计分析与模式识别。
使用方法
研究人员可通过解析CSV文件中的住宅编号与选民信息字段展开多维度分析。建议先进行数据清洗,处理缺失值与异常记录,随后运用统计方法分析选民分布规律。可采用空间分析方法研究高密度选民住宅的空间聚集特征,或通过家庭单位分析研究选民登记模式。数据支持与地理信息系统结合使用,实现选举行为的空间可视化呈现。
背景与挑战
背景概述
BIHAR-SIR数据集聚焦于印度比哈尔邦特定选区选民名册的深度分析,由区域治理研究机构于2020年构建,旨在通过结构化数据揭示基层民主治理中的选民登记模式。该数据集通过记录超过50名成员的住户信息及相同门牌号的样本数据,为核心研究问题——选民名册的准确性与人口分布统计提供了实证基础,对公共政策制定和选举公正性研究具有显著影响力。
当前挑战
数据集需解决选民名册去重与跨区域一致性校验的领域挑战,包括重复登记识别、居住地址标准化及大规模数据整合问题;构建过程中面临原始数据非结构化、门牌号系统异构性以及隐私信息脱敏等技术难点,需开发专用算法以保证数据可用性与合规性。
常用场景
经典使用场景
在选举研究与政治地理分析领域,BIHAR-SIR-data数据集常被用于探索印度比哈尔邦选区的选民分布模式。通过分析同一房屋编号下的多成员家庭数据,研究者能够深入理解高密度居住区的选民结构特征,为选举行为研究提供微观层面的数据支撑。
解决学术问题
该数据集有效解决了选举地理学中关于居住密度与选民行为关联性的研究空白。通过提供精确的房屋-选民对应关系,学者可量化分析家庭规模对投票模式的影响,推动选举预测模型从宏观区域向微观单元延伸,显著提升了选举研究的空间分辨率。
实际应用
实际应用中,政府机构借助该数据集优化选区划分方案,确保选举代表性与公平性。民间组织则通过分析房屋级选民数据,精准制定选民动员策略。这些应用显著增强了选举管理的科学性与针对性,为民主进程提供了数据驱动的决策支持。
数据集最近研究
最新研究方向
在选举数据分析领域,BIHAR-SIR数据集聚焦印度比哈尔邦选区的选民登记模式研究,近期前沿方向集中于利用机器学习技术检测跨选区重复登记的选民身份,以提升选举系统的公正性。该研究与全球选举安全热点事件相呼应,尤其在防范选举欺诈与增强选民名单完整性方面具有重要意义,为政策制定者提供了数据驱动的决策支持,推动选举管理向数字化、透明化方向发展。
以上内容由遇见数据集搜集并总结生成


