DADO
收藏github2025-04-24 更新2025-05-16 收录
下载链接:
https://github.com/Godeex/LLM-DADO-Data-Generator
下载链接
链接失效反馈官方服务:
资源简介:
数据集包括原始的训练/验证/测试数据、生成的训练数据以及标签名称,可在https://huggingface.co/datasets/GLOX/DADO的子文件夹`./dataset`中找到。具体数据集包括Amazon、Reddit和SST-2,分别用于产品评论、网络帖子和电影评论的多类别分类任务。
This dataset consists of raw training, validation, test data, generated training data, and label names, which can be found in the `./dataset` subfolder of the Hugging Face dataset repository at https://huggingface.co/datasets/GLOX/DADO. The specific datasets included are Amazon, Reddit, and SST-2, which are respectively used for multi-class classification tasks of product reviews, online posts, and movie reviews.
创建时间:
2025-04-24
原始信息汇总
DADO数据集概述
数据集基本信息
- 来源:Hugging Face数据集仓库(GLOX/DADO)
- 存储位置:https://huggingface.co/datasets/GLOX/DADO
数据集组成
生成/黄金数据集
| 数据集名称 | 训练样本数 | 测试样本数 | 类别数 | 任务类型 | 领域 |
|---|---|---|---|---|---|
| Amazon | 13.8k | 1.2k | 23 | 多分类 | 产品评论 |
| 26.6k | 2.3k | 45 | 多分类 | 网络帖子 | |
| SST-2 | 6.9k | 1.8k | 2 | 多分类 | 电影评论 |
数据属性
- 属性信息存放于
./datasets子目录中
相关代码
- 训练数据生成代码:位于
gen_train_data目录 - 分类器训练代码:位于
train_classifier目录,包含:run_amazon.shrun_reddit.shrun_sst.sh
搜集汇总
数据集介绍
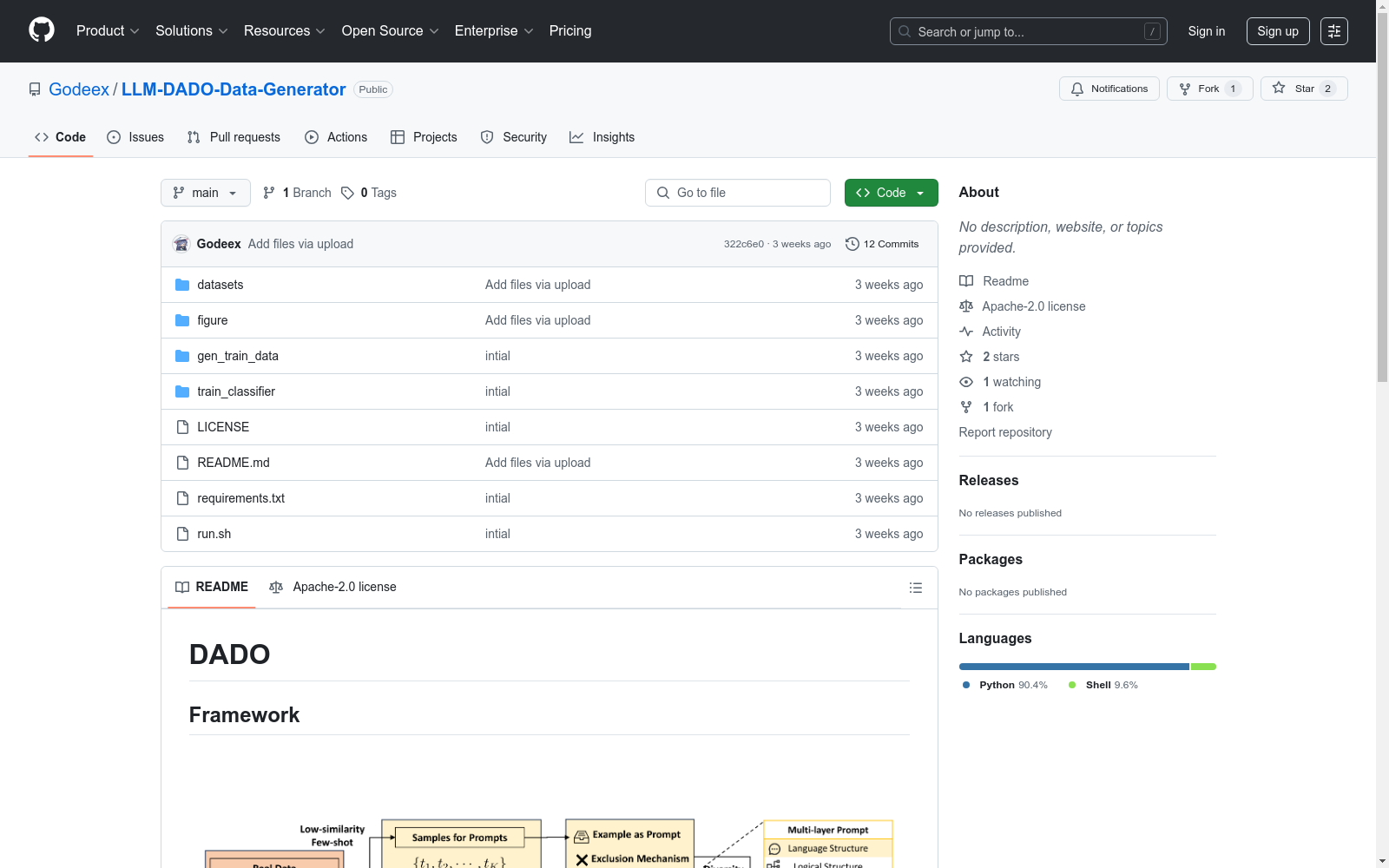
构建方式
DADO数据集的构建依托于多源异构文本数据,通过系统化的数据采集与标注流程完成。其核心框架整合了亚马逊产品评论、Reddit网络帖子和SST-2电影评论三大领域的原始文本,采用半自动化标注技术生成训练集与测试集。具体构建过程中,研发团队设计了分层抽样策略确保类别均衡,并利用领域专家复核机制提升标注质量,最终形成包含23至45个细粒度分类标签的标准化语料库。
特点
该数据集最显著的特征在于其跨领域多任务设计,覆盖电子商务、社交媒体和影视娱乐三大应用场景。各子集规模差异体现了真实场景的数据分布特性,如Reddit子集包含26.6k训练样本以适应网络文本的多样性,而SST-2子集则聚焦2分类情感分析的精粒度建模。数据采用结构化存储方案,每个样本均附带完整的元数据描述,包括领域标记、任务类型和细粒度类别标签,为迁移学习研究提供了理想基准。
使用方法
研究者可通过HuggingFace平台直接加载预处理好的数据集,配套脚本支持快速复现基线实验。针对不同领域任务,分别提供run_amazon.sh、run_reddit.sh和run_sst.sh三个标准化训练管道,内置数据增强与模型优化策略。用户亦可调用gen_train_data模块生成定制化训练数据,或基于train_classifier模块进行跨领域迁移实验。数据集采用模块化目录结构,原始数据、生成数据与标签体系均独立存储,便于扩展新的下游任务。
背景与挑战
背景概述
DADO数据集是由GLOX研究团队构建的多领域文本分类基准数据集,其核心研究目标在于探索生成式数据增强技术在自然语言处理任务中的有效性。该数据集整合了Amazon产品评论、Reddit网络帖子和SST-2电影评论三个典型领域的文本数据,涵盖从二元分类到多类别的复杂语义判别任务。通过系统性地构建生成训练集与黄金测试集的对比框架,该数据集为研究数据增强技术的泛化能力提供了标准化评估平台,显著推动了文本分类领域的方法创新和实证研究。
当前挑战
DADO数据集面临的挑战主要体现在两个方面:在领域问题层面,多源异构文本的语义鸿沟导致统一分类模型难以同时适应产品评论的情感极性识别、社交帖子的主题归类以及影评的二元情感判别等差异化任务;在构建过程中,生成数据与原始数据的分布对齐问题尤为突出,需要精确控制生成模型的参数以避免引入语义漂移或标签噪声。此外,不同领域间显著的类别数量不平衡现象(如23类与45类的并存)也对评估指标的公平性提出了更高要求。
常用场景
经典使用场景
在自然语言处理领域,DADO数据集凭借其多领域文本分类任务的丰富标注数据,成为评估模型泛化能力的基准工具。该数据集覆盖产品评论、网络帖子和电影评论三大领域,尤其适合研究跨领域迁移学习中的知识迁移机制。研究者常利用其23至45类的细粒度分类体系,验证模型在复杂语义场景下的分类性能。
实际应用
在实际应用层面,DADO支持电商平台构建精准的产品评价分析系统,其细粒度情感标签可识别23类商品特性的用户反馈。社交媒体监测领域则利用Reddit子集的45类主题分类能力,实现网络热点话题的实时追踪。电影产业借助SST-2子集的二元情感分析模型,快速评估观众对影片的情感倾向。
衍生相关工作
基于DADO的经典研究包括跨领域对抗训练框架的设计,其中领域判别器与分类器的联合优化显著提升了模型泛化性。在数据增强方向,研究者开发了基于该数据集的条件文本生成模型,通过控制生成样本的领域特征有效扩充训练集。近期工作还探索了元学习在DADO多任务场景中的应用,实现了分类模型的快速领域适应。
以上内容由遇见数据集搜集并总结生成


