DeOcc-1-to-3
收藏arXiv2025-06-27 更新2025-06-28 收录
下载链接:
https://github.com/Quyans/DeOcc123
下载链接
链接失效反馈官方服务:
资源简介:
DeOcc-1-to-3数据集由厦门大学教育部分多媒体可信感知与高效计算重点实验室和北京航空航天大学虚拟现实技术与系统国家重点实验室创建。该数据集包含约40,000个样本,旨在解决从单张部分遮挡的图像中重建3D对象的问题。数据集包含多种遮挡级别、对象类别和掩码模式,为评估遮挡感知视图合成和3D重建方法提供了标准化的评估协议。
The DeOcc-1-to-3 dataset was created by the Key Laboratory of Multimedia Trusted Perception and Efficient Computing of the Ministry of Education, Xiamen University, and the State Key Laboratory of Virtual Reality Technology and Systems, Beihang University. It contains approximately 40,000 samples, and aims to address the problem of 3D object reconstruction from a single partially occluded image. The dataset includes various occlusion levels, object categories and mask patterns, providing a standardized evaluation protocol for assessing occlusion-aware view synthesis and 3D reconstruction methods.
提供机构:
厦门大学教育部分多媒体可信感知与高效计算重点实验室, 北京航空航天大学虚拟现实技术与系统国家重点实验室
创建时间:
2025-06-27
原始信息汇总
DeOcc-1-to-3 数据集概述
基本信息
- 名称: DeOcc-1-to-3
- 类型: 3D去遮挡框架
- 官方实现: 论文《DeOcc-1-to-3: 3D De-Occlusion from a Single Image via Self-Supervised Multi-View Diffusion》的官方实现
核心功能
- 从单张遮挡图像合成六张结构一致的新视角图像
- 实现精确的Amodal 3D重建
主要特点
- 多视角合成: 生成六张结构一致的新视角图像
- 自监督训练: 使用预训练多视角扩散模型生成的伪真实视图进行训练
- 兼容性: 可与现有3D重建流程(如InstantMesh)无缝集成
- 基准测试: 首个针对遮挡感知3D重建的基准测试
当前状态
- 代码、数据集和模型即将发布
搜集汇总
数据集介绍
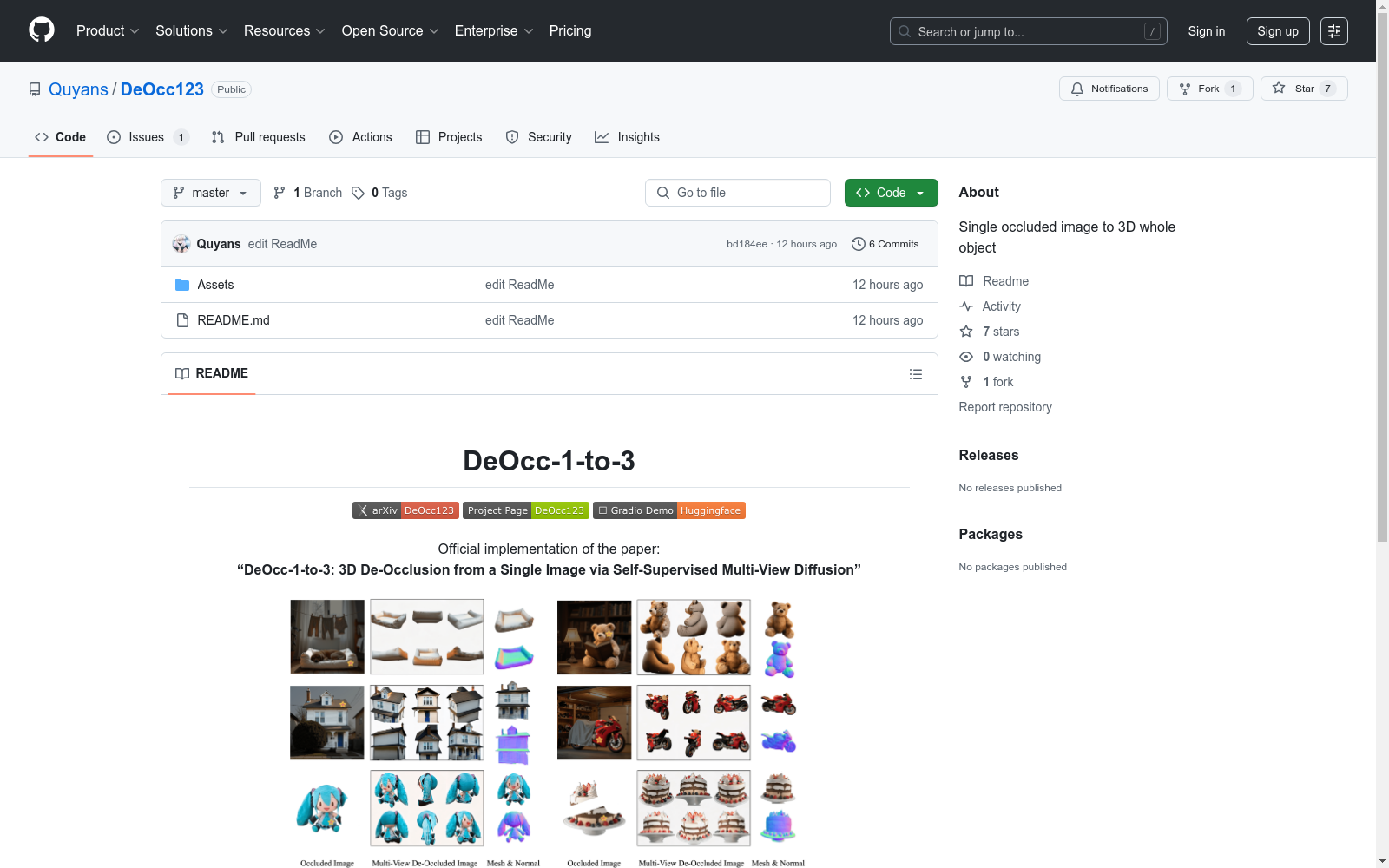
构建方式
DeOcc-1-to-3数据集的构建基于自监督学习框架,通过随机遮挡技术生成遮挡-未遮挡图像对。具体而言,利用SA-1B数据集中的前景对象分割结果,将随机选择的对象叠加到自然背景上合成遮挡场景。随后采用预训练的多视角扩散模型为未遮挡图像生成六视角伪真实视图,形成最终包含4万高质量样本的训练集。该过程创新性地结合了二维遮挡合成与三维一致性监督,无需人工标注即可实现结构感知的遮挡补全学习。
使用方法
该数据集主要服务于三维去遮挡生成任务,使用流程分为三个阶段:首先将单张遮挡图像输入微调后的多视角扩散模型,生成六视角RGB图像;随后通过标准化的3×2拼接格式输出,保持与Zero123++等架构的兼容性;最终可接入InstantMesh等重建框架生成完整三维网格。值得注意的是,整个流程无需文本提示,在推理阶段采用EMA权重(β=0.9999)确保生成稳定性。基准评估建议采用Occ-LVIS的五级分层协议,综合考量不同遮挡难度下的重建质量。
背景与挑战
背景概述
DeOcc-1-to-3数据集由厦门大学可信多媒体感知与高效计算教育部重点实验室和北京航空航天大学虚拟现实技术与系统国家重点实验室的研究团队于2025年提出,旨在解决单幅遮挡图像下的三维去遮挡与多视角生成问题。该数据集基于自监督学习框架,利用Pix2Gestalt数据集中的遮挡-非遮挡图像对及伪真实视图进行训练,实现了从单幅遮挡图像直接生成六视角结构一致的去遮挡图像,显著提升了三维重建的完整性与一致性。其创新性在于将遮挡补全与多视角生成任务统一于端到端框架,克服了传统两阶段方法中多视角不一致与误差累积的缺陷,为计算机视觉领域的遮挡感知三维建模提供了重要基准。
当前挑战
该数据集面临的核心挑战包括:1) 领域问题层面,单视角遮挡图像的三维重建存在严重几何模糊性,现有方法难以在遮挡区域推断合理的几何与外观信息,导致多视角生成结果出现结构断裂或纹理失真;2) 构建过程中需解决自监督训练下伪真实视图的噪声干扰问题,以及随机遮挡模拟与真实场景间的域差异。此外,基准评估需覆盖不同遮挡比例(10%-40%)、复杂物体类别及多样化掩模模式,对数据多样性与模型泛化能力提出极高要求。
常用场景
经典使用场景
DeOcc-1-to-3数据集在计算机视觉领域的经典应用场景主要集中于单幅遮挡图像的多视角去遮挡与三维重建。该数据集通过自监督学习框架,能够从单幅被部分遮挡的RGB图像中生成六种结构一致的新视角图像,为下游的三维重建任务提供高质量输入。这一能力在现实场景中尤为重要,例如在自动驾驶、机器人操作和增强现实等领域,物体常因遮挡导致视觉信息不完整,而DeOcc-1-to-3通过联合学习遮挡补全与多视角生成,显著提升了三维模型的完整性与一致性。
解决学术问题
DeOcc-1-to-3数据集解决了单幅遮挡图像三维重建中的关键学术问题。传统方法通常假设输入图像完全可见,导致在遮挡情况下生成的多视角图像结构不一致,进而影响三维重建质量。该数据集通过端到端的遮挡感知多视角生成框架,避免了传统两阶段流程(如先二维修复再三维重建)中的误差累积问题。其自监督训练策略利用遮挡-未遮挡图像对和伪真实视角,无需人工标注即可实现结构感知的补全与视角一致性学习,为遮挡场景下的三维重建提供了新的研究范式。
实际应用
在实际应用中,DeOcc-1-to-3数据集展现了广泛的适用性。例如,在工业检测中,可对部分遮挡的零件进行完整三维建模;在文化遗产保护中,能够从单张受损文物照片恢复其三维结构;在电子商务中,支持从遮挡的商品图像生成多角度展示视图。该数据集生成的六视角图像可直接兼容InstantMesh等主流三维重建框架,输出水密网格和高精度表面法线,满足实时渲染与编辑的需求。其泛化能力覆盖了从自然遮挡到人工合成的多样化场景,为实际应用提供了可靠的技术支持。
数据集最近研究
最新研究方向
在计算机视觉领域,单图像3D重建一直是极具挑战性的任务,尤其是面对现实世界中的遮挡情况时。DeOcc-1-to-3数据集的提出,标志着遮挡感知的多视图生成技术迈入新阶段。该数据集通过自监督学习框架,实现了从单张遮挡图像到多视角去遮挡图像的端到端生成,为下游3D重建任务提供了结构一致的输入。当前研究热点集中在如何提升模型在复杂遮挡场景下的泛化能力,以及如何将生成的多视图无缝集成到NeRF、3D高斯泼溅等先进重建框架中。这一技术突破对增强现实、机器人视觉等领域具有深远影响,为处理真实场景中的遮挡问题提供了标准化解决方案。
相关研究论文
- 1DeOcc-1-to-3: 3D De-Occlusion from a Single Image via Self-Supervised Multi-View Diffusion厦门大学教育部分多媒体可信感知与高效计算重点实验室, 北京航空航天大学虚拟现实技术与系统国家重点实验室 · 2025年
以上内容由遇见数据集搜集并总结生成


