reddit-comments-uwaterloo
收藏Hugging Face2024-09-04 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/alvanlii/reddit-comments-uwaterloo
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含从2015年至2024年r/uwaterloo子版块的提交内容。每年数据包括id、分数、永久链接、深度、链接ID、父ID、发布者、内容、UTC日期、标签、新状态、更新状态和索引级别等特征。数据集通过PRAW和Reddit API创建,并遵循Reddit的许可条款。用户可以通过提交拉取请求并添加其ID到filter_ids.json文件中选择退出。
创建时间:
2024-08-30
原始信息汇总
数据集概述
该数据集包含来自 r/uwaterloo 的评论数据,利用 PRAW 和 Reddit API 进行下载。
数据集配置
数据集按年份分为多个配置,每个配置包含训练集(train)。
配置详情
-
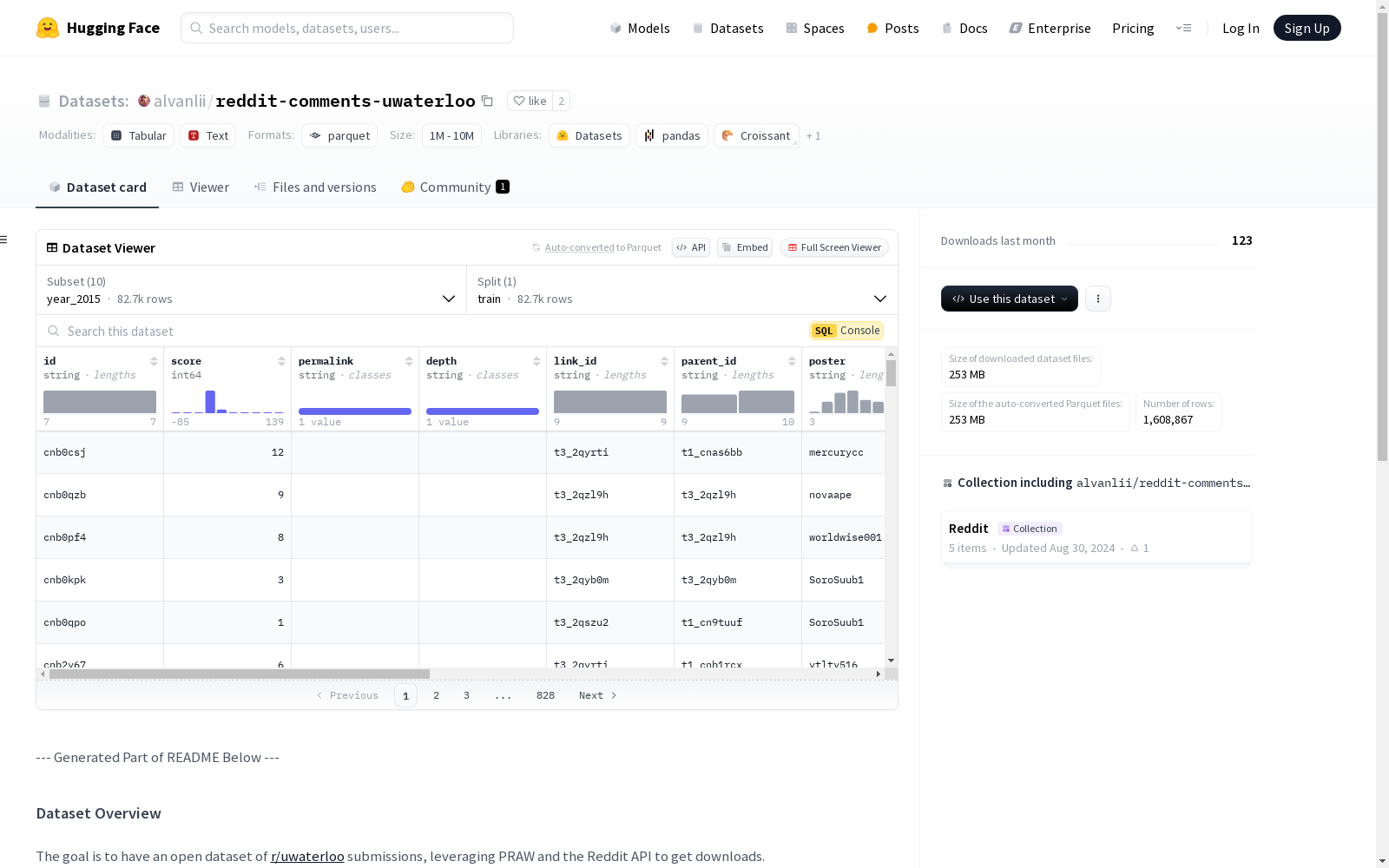
year_2015
- 特征:id, score, permalink, depth, link_id, parent_id, poster, content, date_utc, flair, new, updated, index_level_0
- 训练集:82707 条数据,24597775 字节
- 下载大小:14199076 字节
- 数据集大小:24597775 字节
-
year_2016
- 特征:id, score, permalink, depth, link_id, parent_id, poster, content, date_utc, flair, new, updated, index_level_0
- 训练集:115258 条数据,31725124 字节
- 下载大小:18339731 字节
- 数据集大小:31725124 字节
-
year_2017
- 特征:id, score, permalink, depth, link_id, parent_id, poster, content, date_utc, flair, new, updated, index_level_0
- 训练集:231408 条数据,66619085 字节
- 下载大小:35903130 字节
- 数据集大小:66619085 字节
-
year_2018
- 特征:id, score, permalink, depth, link_id, parent_id, poster, content, date_utc, flair, new, updated, index_level_0
- 训练集:264246 条数据,83970726 字节
- 下载大小:41583278 字节
- 数据集大小:83970726 字节
-
year_2019
- 特征:id, score, permalink, depth, link_id, parent_id, poster, content, date_utc, flair, new, updated, index_level_0
- 训练集:293538 条数据,91572130 字节
- 下载大小:45149003 字节
- 数据集大小:91572130 字节
-
year_2020
- 特征:id, score, permalink, depth, link_id, parent_id, poster, content, date_utc, flair, new, updated, index_level_0
- 训练集:277205 条数据,89261893 字节
- 下载大小:44020462 字节
- 数据集大小:89261893 字节
-
year_2021
- 特征:id, score, permalink, depth, link_id, parent_id, poster, content, date_utc, flair, new, updated, index_level_0
- 训练集:161207 条数据,50670926 字节
- 下载大小:25272190 字节
- 数据集大小:50670926 字节
-
year_2022
- 特征:id, score, permalink, depth, link_id, parent_id, poster, content, date_utc, flair, new, updated, index_level_0
- 训练集:157496 条数据,49411900 字节
- 下载大小:24673180 字节
- 数据集大小:49411900 字节
-
year_2023
- 特征:id, score, permalink, depth, link_id, parent_id, poster, content, date_utc, flair, new, updated, index_level_0
- 训练集:0 条数据,0 字节
- 下载大小:2914 字节
- 数据集大小:0 字节
-
year_2024
- 特征:id, content, score, poster, date_utc, flair, ups, permalink, depth, link_id, parent_id, updated, new
- 训练集:2430 条数据,839364 字节
- 下载大小:408271 字节
- 数据集大小:839364 字节
数据文件路径
- year_2015: year_2015/train-*
- year_2016: year_2016/train-*
- year_2017: year_2017/train-*
- year_2018: year_2018/train-*
- year_2019: year_2019/train-*
- year_2020: year_2020/train-*
- year_2021: year_2021/train-*
- year_2022: year_2022/train-*
- year_2023: year_2023/train-*
- year_2024: year_2024/train-*
搜集汇总
数据集介绍
构建方式
该数据集通过PRAW和Reddit API从[r/uwaterloo](https://www.reddit.com/r/uwaterloo/)子论坛中提取评论数据,并按年份进行划分。每个年份的配置文件包含多个特征字段,如评论ID、评分、发布者、内容、时间戳等。数据以CSV格式存储,并通过HuggingFace平台提供下载。数据集的构建过程确保了数据的完整性和时效性,并通过定期的更新机制保持数据的动态性。
特点
该数据集涵盖了2015年至2024年间的Reddit评论数据,具有丰富的时间跨度和多样的特征字段。每个年份的配置文件均包含详细的元数据,如评论的深度、链接ID、父评论ID等,便于进行多层次的分析。此外,数据集还提供了评论的评分、发布者信息以及时间戳,支持时间序列分析和用户行为研究。数据集的规模逐年递增,反映了Reddit社区的活跃度变化。
使用方法
用户可通过HuggingFace平台下载该数据集,并按年份选择所需的配置文件进行加载。数据集以CSV格式存储,支持使用Pandas等工具进行数据处理和分析。用户可以根据评论的时间戳进行时间序列分析,或结合发布者信息和评分进行用户行为研究。此外,数据集的结构化特征字段便于进行自然语言处理任务,如情感分析或主题建模。数据集的更新机制确保了数据的时效性,用户可通过定期下载获取最新数据。
背景与挑战
背景概述
reddit-comments-uwaterloo数据集由alvanlii团队创建,旨在为研究社区提供一个开放的、基于Reddit平台r/uwaterloo子论坛评论的数据资源。该数据集通过PRAW和Reddit API获取数据,涵盖了从2015年至2024年的评论内容,内容涉及用户ID、评分、评论链接、评论深度、发帖者信息、评论内容、时间戳等多个维度。这一数据集的创建为社交媒体分析、自然语言处理以及社区行为研究提供了丰富的素材,尤其是在高校社区网络行为研究领域具有重要的参考价值。
当前挑战
reddit-comments-uwaterloo数据集在构建和应用过程中面临多重挑战。首先,数据获取依赖于Reddit API,其访问限制和数据更新频率可能影响数据集的完整性和时效性。其次,评论内容中可能存在敏感信息或隐私问题,如何在数据公开与隐私保护之间取得平衡是一个重要问题。此外,评论数据的非结构化特性增加了数据清洗和预处理的难度,尤其是在处理多语言、俚语和网络用语时,语义解析和情感分析的准确性面临挑战。最后,数据集的持续更新和维护需要大量资源,如何确保数据的长期可用性和一致性也是一个亟待解决的问题。
常用场景
经典使用场景
reddit-comments-uwaterloo数据集广泛应用于社交媒体分析领域,特别是在研究Reddit社区中的用户互动和评论行为方面。该数据集包含了从2015年至2024年期间r/uwaterloo子论坛的评论数据,涵盖了用户ID、评论内容、时间戳等关键信息。研究人员可以利用这些数据深入分析用户行为模式、情感倾向以及社区动态变化。
解决学术问题
该数据集为学术界提供了丰富的研究素材,解决了多个关键问题。首先,它帮助研究者理解在线社区中的用户互动机制,特别是在大学相关论坛中的讨论模式。其次,通过分析评论内容和用户评分,研究者可以探讨信息传播的有效性和用户参与度。此外,该数据集还为自然语言处理领域提供了大量真实世界的文本数据,支持情感分析、主题建模等研究。
衍生相关工作
基于reddit-comments-uwaterloo数据集,许多经典研究工作得以展开。例如,有研究利用该数据集开发了先进的自然语言处理模型,用于自动检测和分类在线评论中的情感和主题。另一项研究则聚焦于用户行为分析,揭示了在线社区中的信息传播模式和用户互动规律。这些工作不仅推动了相关领域的研究进展,还为实际应用提供了有力的技术支持。
以上内容由遇见数据集搜集并总结生成


