scikit-learn/breast-cancer-wisconsin
收藏Hugging Face2022-06-20 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/scikit-learn/breast-cancer-wisconsin
下载链接
链接失效反馈官方服务:
资源简介:
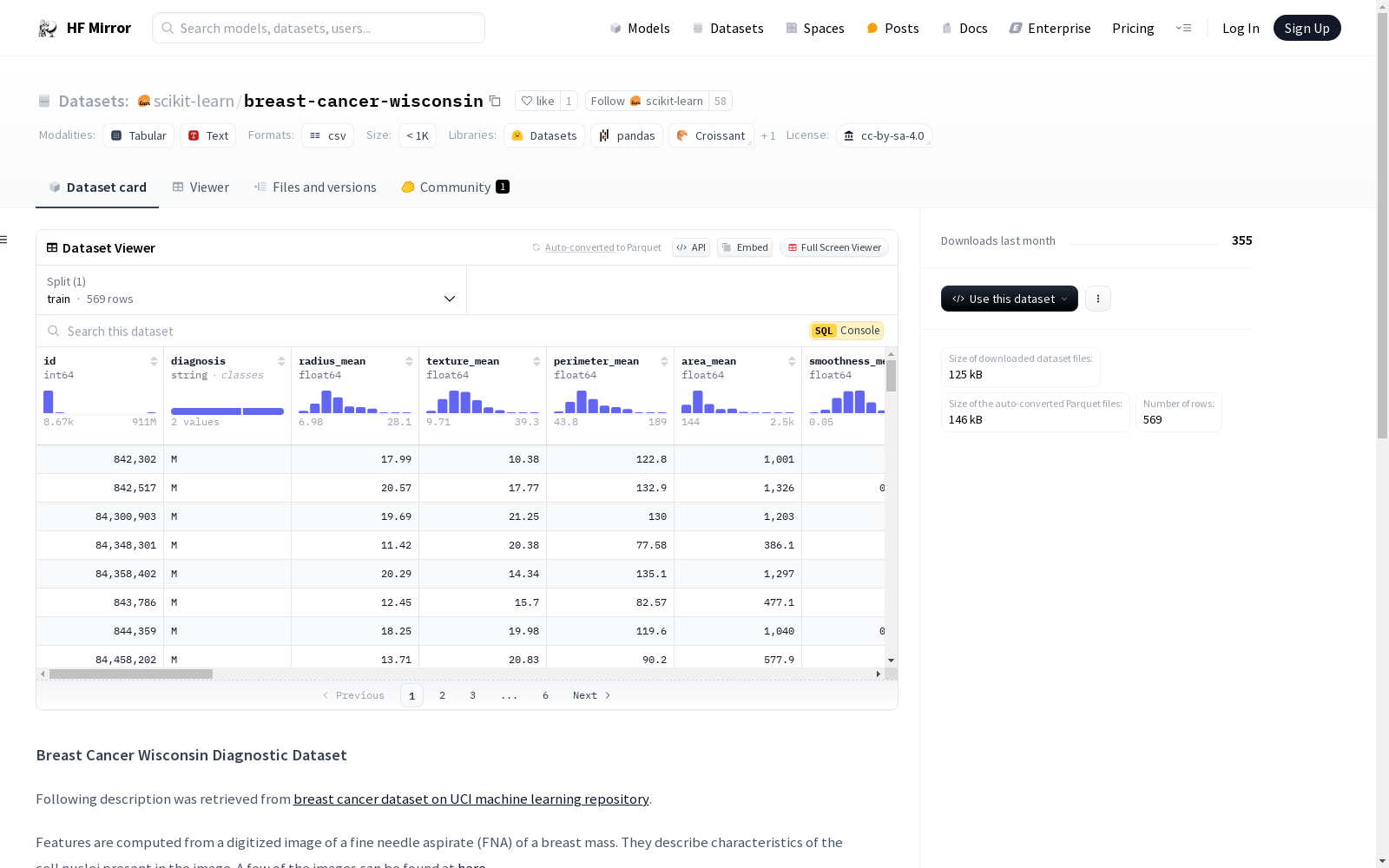
Breast Cancer Wisconsin Diagnostic Dataset(威斯康星州乳腺癌诊断数据集)的特征是从乳腺肿块的细针穿刺(FNA)数字化图像中计算得出的,描述了图像中细胞核的特征。数据集包含ID号、诊断结果(恶性或良性)以及每个细胞核的十个实值特征,如半径、纹理、周长、面积、平滑度、紧密度、凹度、凹点、对称性和分形维度。分离平面是通过使用多表面方法树(MSM-T)分类方法获得的,该方法使用线性规划构建决策树。相关特征是通过在1-4个特征和1-3个分离平面的空间中进行穷举搜索选择的。
Features of the Breast Cancer Wisconsin Diagnostic Dataset are calculated from digitized fine-needle aspiration (FNA) images of breast masses, which characterize the cell nuclei in the images. The dataset includes ID numbers, diagnosis results (malignant or benign), and ten real-valued features for each cell nucleus, such as radius, texture, perimeter, area, smoothness, compactness, concavity, concave points, symmetry, and fractal dimension. The separation planes were derived using the Multi-Surface Method Tree (MSM-T) classification approach, which constructs decision trees via linear programming. Relevant features were selected through an exhaustive search over the space of 1 to 4 features and 1 to 3 separation planes.
提供机构:
scikit-learn
原始信息汇总
Breast Cancer Wisconsin Diagnostic Dataset
描述
特征是从乳腺肿块的细针穿刺(FNA)图像中计算得出的。这些特征描述了图像中细胞核的特征。部分图像可以在这里找到。
分离平面是通过使用多表面方法树(MSM-T)获得的,这是一种使用线性规划构建决策树的分类方法。相关特征是通过在1-4个特征和1-3个分离平面的空间中进行穷举搜索选择的。
属性信息
- ID number:标识号码
- Diagnosis:诊断结果(M = 恶性,B = 良性)
每个细胞核计算出十个实值特征:
- radius:半径(从中心到周边点的平均距离)
- texture:纹理(灰度值的标准偏差)
- perimeter:周长
- area:面积
- smoothness:平滑度(半径长度的局部变化)
- compactness:紧密度(周长^2 / 面积 - 1.0)
- concavity:凹度(轮廓凹部分的严重程度)
- concave points:凹点(轮廓凹部分的数量)
- symmetry:对称性
- fractal dimension:分形维数(“海岸线近似” - 1)
搜集汇总
数据集介绍
构建方式
该数据集源自威斯康星大学麦迪逊分校的乳腺癌诊断数据,通过数字化乳腺细针穿刺(FNA)图像构建而成。特征提取过程涉及对细胞核图像的分析,涵盖了从图像中计算出的十项实值特征,包括半径、纹理、周长、面积等。这些特征通过多表面方法-树(MSM-T)进行分类,并利用线性规划构建决策树,以选择最具区分性的特征组合。
特点
该数据集的显著特点在于其特征的多样性和精确性,涵盖了从细胞核图像中提取的十项关键特征,这些特征能够有效描述细胞核的形态学特性。此外,数据集中的诊断标签明确区分了恶性(M)和良性(B)病例,为分类任务提供了清晰的目标变量。
使用方法
该数据集适用于多种机器学习任务,尤其是分类问题,可用于训练和验证乳腺癌诊断模型。用户可以通过加载数据集并提取特征和标签,利用这些数据进行模型训练。常见的使用场景包括但不限于支持向量机、决策树、随机森林等分类算法的实现与优化。
背景与挑战
背景概述
乳腺癌是全球女性中最常见的恶性肿瘤之一,其早期诊断对提高患者生存率至关重要。Breast Cancer Wisconsin Diagnostic Dataset由美国威斯康星大学麦迪逊分校的研究团队创建,旨在通过细针穿刺(FNA)图像的数字化分析,提供一种有效的乳腺癌诊断工具。该数据集的核心研究问题是通过计算细胞核的特征,如半径、纹理、周长等,来区分恶性与良性肿瘤。该数据集的构建基于Multisurface Method-Tree(MSM-T)分类方法,并结合线性规划技术,以实现对两类线性不可分集合的鲁棒区分。该数据集的发布对机器学习在医学图像分析领域的应用具有重要推动作用,为乳腺癌的自动化诊断提供了宝贵的数据资源。
当前挑战
Breast Cancer Wisconsin Diagnostic Dataset在构建过程中面临多项挑战。首先,数据集的特征提取依赖于细针穿刺图像的数字化处理,这一过程需要高精度的图像分析技术,以确保特征的准确性和可靠性。其次,数据集的分类任务涉及复杂的线性规划问题,如何在有限的特征空间内选择最优的分离平面,是该数据集面临的主要技术挑战。此外,数据集的样本量相对有限,如何在少量样本中实现高精度的分类,也是该数据集在实际应用中需要克服的难题。最后,数据集的特征选择和分类模型的构建需要结合医学领域的专业知识,以确保模型的临床适用性和诊断准确性。
常用场景
经典使用场景
乳腺癌威斯康星诊断数据集(Breast Cancer Wisconsin Diagnostic Dataset)在医学图像分析领域具有广泛的应用。该数据集通过数字化乳腺细针穿刺(FNA)图像,提取了细胞核的多种特征,如半径、纹理、周长等。这些特征为机器学习模型提供了丰富的输入信息,使得模型能够有效地进行乳腺癌的良恶性分类。经典的使用场景包括构建分类模型,通过训练数据集来预测乳腺肿瘤的恶性或良性状态,从而辅助医生进行诊断决策。
解决学术问题
该数据集解决了医学图像分析中的一个关键问题,即如何通过计算机辅助诊断(CAD)系统提高乳腺癌的早期检测和诊断准确性。通过提供详细的细胞核特征,该数据集为研究者提供了一个标准化的基准,用于评估和比较不同分类算法的性能。这不仅推动了机器学习在医学领域的应用,还为开发更精确、更可靠的诊断工具提供了理论和实践基础。
衍生相关工作
基于乳腺癌威斯康星诊断数据集,研究者们开发了多种先进的分类算法和特征选择方法。例如,一些研究工作探索了如何通过深度学习技术从原始图像中自动提取特征,以提高分类的准确性。此外,该数据集还激发了关于特征选择和模型解释性的研究,旨在提高模型的透明度和可解释性,从而增强其在临床实践中的接受度。这些衍生工作不仅丰富了机器学习理论,还为医学影像分析领域带来了新的技术突破。
以上内容由遇见数据集搜集并总结生成


