Persian_QA
收藏Hugging Face2024-12-20 更新2024-12-21 收录
下载链接:
https://huggingface.co/datasets/mshojaei77/Persian_QA
下载链接
链接失效反馈官方服务:
资源简介:
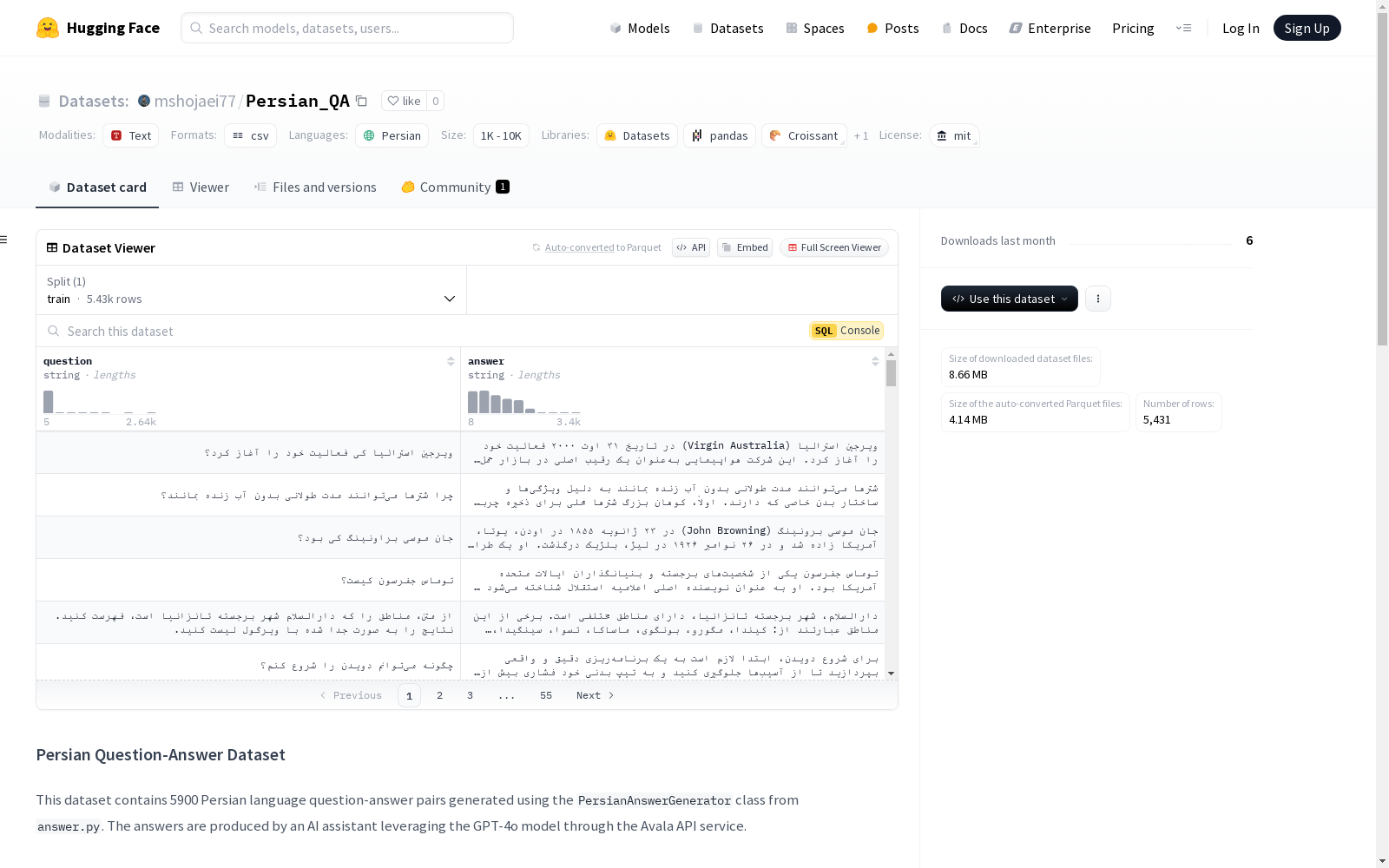
该数据集包含5900对波斯语问答,由AI助手生成,利用GPT-4o模型通过Avala API服务。答案具有标准波斯语掌握、科学准确、清晰易懂、实用例子、结构化、正确标点、诚实承认不确定性、提供可靠来源、根据受众调整、提供长答案摘要等特点。数据集适合训练波斯语模型、开发问答系统、进行自然语言处理任务和教育目的。数据格式为CSV,包含问题和答案两列。
This dataset contains 5,900 Persian question-answer pairs, generated by AI assistants using the GPT-4o model via the Avala API service. The generated answers boast standard Persian language proficiency, scientific accuracy, clarity and comprehensibility, practical examples, structured formatting, correct punctuation, honest acknowledgment of uncertainty, provision of reliable sources, adaptation to the target audience, and inclusion of summaries for lengthy answers. This dataset is suitable for training Persian language models, developing question-answering systems, conducting natural language processing tasks, and educational purposes. The data is stored in CSV format, with two columns: "question" and "answer".
创建时间:
2024-12-17
原始信息汇总
Persian Question-Answer Dataset
数据集描述
该数据集包含5900对波斯语(Farsi)问答对,由PersianAnswerGenerator类从answer.py生成。答案由AI助手通过Avala API服务利用GPT-4o模型生成。
答案特点
- 标准波斯语的完全掌握
- 对问题的准确和科学回答
- 清晰易懂的解释
- 使用实际例子以更好地理解概念
- 结构化的回答,适当的段落划分
- 正确使用波斯语书写标点符号
- 在需要时诚实地承认不确定性
- 提供可靠的进一步学习资源
- 根据受众调整回答水平
- 为长答案提供总结
数据集生成过程
- 数据收集:加载了5900个从lmsys问题翻译过来的波斯语问题。
- 答案生成:通过Avala API与GPT-4o模型交互,生成详细且准确的答案。
- 数据处理:清理和组织生成的答案。
使用场景
该数据集适用于:
- 训练波斯语语言模型
- 开发问答系统
- 执行自然语言处理任务
- 教育目的
数据格式
数据集以CSV格式提供,包含两列:
question:波斯语问题answer:波斯语详细答案
许可证
该数据集在MIT许可证下发布。
搜集汇总
数据集介绍
构建方式
该数据集通过精心设计的流程构建,首先从lmsys问题集中翻译并收集了5900个波斯语问题,随后利用GPT-4o模型通过Avala API服务生成详细且准确的答案。生成的答案经过精细的数据处理,确保其结构化、清晰且符合波斯语的书写规范。
特点
该数据集的显著特点在于其答案的科学性和准确性,不仅完全掌握了标准波斯语,还提供了清晰的解释和实用的例子。此外,答案中包含了适当的段落划分和标点符号使用,确保了文本的可读性和专业性。
使用方法
该数据集适用于多种应用场景,包括训练波斯语语言模型、开发问答系统、执行自然语言处理任务以及教育目的。数据以CSV格式提供,包含两个主要列:‘question’和‘answer’,便于直接导入和使用。
背景与挑战
背景概述
在自然语言处理领域,特别是针对波斯语(Persian)的问答系统研究中,Persian_QA数据集的创建标志着一项重要的进展。该数据集由5900对波斯语问答对组成,这些问答对是通过使用`PersianAnswerGenerator`类从`answer.py`脚本生成的,并借助GPT-4o模型通过Avala API服务提供支持。主要研究人员或机构通过这一数据集,旨在解决波斯语环境中高质量问答系统的构建问题,推动波斯语自然语言处理技术的发展。该数据集不仅涵盖了标准波斯语的全面掌握,还包括了科学准确的回答、清晰的解释以及实用的例子,为波斯语语言模型的训练和问答系统的开发提供了宝贵的资源。
当前挑战
Persian_QA数据集在构建过程中面临了多项挑战。首先,波斯语作为一种复杂的语言,其语法和词汇的多样性增加了数据处理的难度。其次,确保AI生成的答案既准确又符合科学标准,同时还要适应不同受众的理解水平,这对模型的训练和调优提出了高要求。此外,数据集的生成过程中,如何有效地从源数据中提取并翻译问题,以及如何确保答案的连贯性和逻辑性,都是需要克服的技术难题。最后,尽管数据集已经提供了高质量的问答对,但在实际应用中,如何进一步提高模型的泛化能力和适应性,仍然是一个持续的研究挑战。
常用场景
经典使用场景
Persian_QA数据集的经典使用场景主要集中在波斯语自然语言处理领域,尤其是针对波斯语的问答系统开发。通过该数据集,研究者和开发者可以训练波斯语语言模型,构建能够处理波斯语问答任务的智能系统。此外,该数据集还可用于进行波斯语的自然语言处理任务,如文本分类、信息抽取等,从而推动波斯语在人工智能领域的应用。
衍生相关工作
Persian_QA数据集的发布催生了一系列相关研究工作,特别是在波斯语自然语言处理和问答系统领域。研究者们基于该数据集开发了多种波斯语语言模型,并提出了改进问答系统性能的新方法。此外,该数据集还被用于波斯语教育技术的研究,推动了波斯语智能化教学工具的发展。这些衍生工作不仅丰富了波斯语在人工智能领域的应用,还为其他低资源语言的处理提供了借鉴。
数据集最近研究
最新研究方向
在自然语言处理领域,波斯语(Persian)问答数据集(Persian_QA)的最新研究方向主要集中在提升波斯语语言模型的性能与应用。该数据集通过GPT-4o模型生成的5900对波斯语问答对,不仅涵盖了标准波斯语的全面掌握,还提供了科学、准确且结构化的回答,使其在训练波斯语问答系统和进行自然语言处理任务中具有显著优势。近年来,随着多语言模型和跨语言学习技术的快速发展,Persian_QA数据集的研究逐渐聚焦于如何有效整合波斯语与其他语言资源,以增强模型的跨语言理解和生成能力。此外,该数据集在教育领域的应用也备受关注,尤其是在波斯语教学和学习资源的开发中,其提供的详细解释和实用示例为教育技术的创新提供了新的可能性。
以上内容由遇见数据集搜集并总结生成


