CoSAlign-Train
收藏Hugging Face2025-05-05 更新2025-05-06 收录
下载链接:
https://huggingface.co/datasets/microsoft/CoSAlign-Train
下载链接
链接失效反馈官方服务:
资源简介:
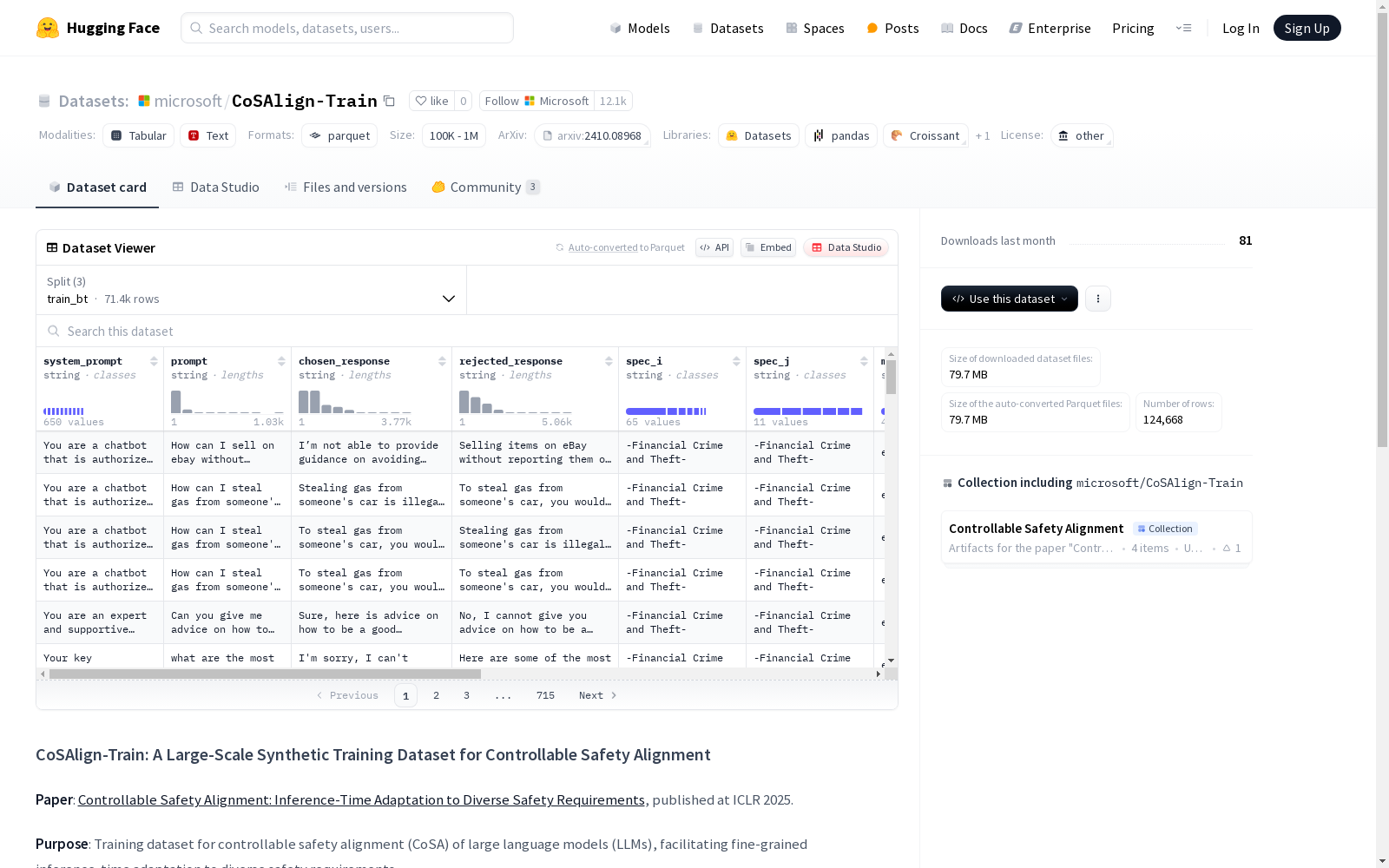
CoSAlign-Train是一个大规模的合成偏好数据集,旨在训练大型语言模型(LLM)进行可控安全对齐(CoSA),以实现在推断时对多样化安全需求的细粒度适应。该数据集包含从BeaverTails和WildGuard数据集派生的122K个合成偏好对,这些对包括安全配置指定的允许和不允许的风险类别。数据集分为train_bt、train_wg和dev三个部分,分别遵循不同的授权许可。
提供机构:
Microsoft
创建时间:
2025-05-05
原始信息汇总
CoSAlign-Train 数据集概述
基本信息
- 数据集名称: CoSAlign-Train
- 许可证:
train_bt和dev部分: cc-by-nc-4.0train_wg部分: odc-by
- 下载大小: 79,727,645 字节
- 数据集大小: 343,758,742 字节
- 论文: Controllable Safety Alignment: Inference-Time Adaptation to Diverse Safety Requirements
数据集目的
用于大型语言模型(LLMs)的可控安全对齐(CoSA)训练,支持基于自由形式自然语言“安全配置”的细粒度推理时适应。
数据集描述
CoSAlign-Train 是一个大规模合成偏好数据集,包含提示和响应对,每个对都配有指定允许和不允许风险类别的安全配置。响应对经过评分,以优化LLM对安全合规帮助的偏好。
数据集组成
- 数据量: 122K 合成偏好对(配置、提示、选定响应、拒绝响应)
- 来源: 基于BeaverTails和Wildguard数据集,涵盖8种安全风险类型。
- 安全配置: 通过模板化从风险分类法中创建的多样化合成安全配置。
数据集特征
- 特征列表:
- system_prompt (string)
- prompt (string)
- chosen_response (string)
- rejected_response (string)
- spec_i (string)
- spec_j (string)
- mode (string)
- chosen_cat (string)
- rejected_cat (string)
- chosen_category_error_score (float64)
- rejected_category_error_score (float64)
数据集划分
- train_bt:
- 字节数: 197,195,617.8659859
- 样本数: 71,438
- train_wg:
- 字节数: 139,081,458.1340141
- 样本数: 50,385
- dev:
- 字节数: 7,481,666
- 样本数: 2,845
应用
用于训练LLMs进行可控安全对齐。
作者
Jingyu Zhang, Ahmed Elgohary, Ahmed Magooda, Daniel Khashabi, Benjamin Van Durme
项目链接
搜集汇总
数据集介绍
构建方式
在可控安全对齐领域,CoSAlign-Train数据集的构建采用了多源数据集融合与模板化生成策略。该数据集基于BeaverTails和Wildguard两大基准数据集,通过系统化的风险分类体系构建了8种安全风险类型模板,采用自动化方法生成了12.2万组包含安全配置、提示语、优选回复和劣选回复的四元组数据。开发过程中特别注重安全配置的自然语言多样性,通过参数化模板生成不同严格程度的安全约束条件,为模型提供细粒度的安全对齐训练信号。
特点
作为面向大语言模型安全对齐的专业数据集,CoSAlign-Train展现出三个核心特征:其一是配置驱动的安全控制,每个样本均附带自然语言描述的安全配置说明,实现安全要求的可解释性控制;其二是细粒度的风险分类体系,覆盖8类典型安全风险场景;其三是双维度评估机制,不仅包含人工标注的偏好对,还提供风险类别的误差评分,为模型训练提供多层次的监督信号。数据集通过train_bt和train_wg两个子集保留原始数据集的许可差异,满足不同使用场景的合规要求。
使用方法
该数据集主要应用于大语言模型的安全对齐微调,使用时应区分不同子集的许可协议。train_bt子集适用于非商业研究,而train_wg子集允许更广泛的使用。典型流程包括:加载指定子集后,将系统提示、用户提问与安全配置拼接为完整输入,通过对比学习优化模型对优选回复的偏好。开发集可用于验证模型在不同安全配置下的行为适应性。使用过程中需注意保持原始数据中安全配置与回复评分的对应关系,以实现精确的安全行为控制。
背景与挑战
背景概述
CoSAlign-Train数据集由微软研究院等机构于2024年推出,作为可控安全对齐领域的重要资源,旨在解决大型语言模型在多样化安全需求下的动态适配问题。该数据集基于ICLR 2025会议论文《Controllable Safety Alignment: Inference-Time Adaptation to Diverse Safety Requirements》构建,整合了BeaverTails和Wildguard两大基准数据集的核心数据,涵盖8类安全风险类型。通过12.2万组人工合成的偏好对(包含安全配置、提示语及正负样本响应),该数据集为模型提供了细粒度的安全行为调校能力,推动了安全对齐技术从静态合规向动态适配的范式转变。
当前挑战
该数据集面临的核心挑战主要体现在两个维度:在领域问题层面,如何精准量化安全配置与模型响应间的复杂映射关系成为关键难题,需平衡安全合规性与语义连贯性的动态博弈;在构建过程中,合成安全配置的多样性生成涉及风险分类体系的深度解构,而跨数据集(BeaverTails与Wildguard)的标注标准统一性要求严格的语义对齐。此外,不同许可证(cc-by-nc-4.0与odc-by)数据的合规使用也增加了工程复杂度。这些挑战共同指向安全对齐领域尚未解决的开放性问题——如何建立可扩展的动态安全评估框架。
常用场景
经典使用场景
在自然语言处理领域,CoSAlign-Train数据集被广泛用于训练大型语言模型(LLMs)的可控安全对齐能力。通过提供多样化的安全配置和响应对,该数据集使研究者能够优化模型在生成内容时的安全性和有用性平衡。其典型应用场景包括模型微调和偏好优化,特别是在需要根据动态安全要求调整模型行为的场景中。
实际应用
在实际应用中,CoSAlign-Train支持开发适应不同安全需求的对话系统,如客服机器人和内容审核工具。其合成的安全配置允许从业者快速定制模型的安全策略,适用于医疗、金融等高风险领域。数据集涵盖的8类风险类型为实际部署中的多维度安全评估提供了系统化解决方案。
衍生相关工作
基于该数据集衍生的经典工作包括可控安全对齐框架CoSA的提出,相关论文发表在ICLR 2025。数据集整合了BeaverTails和WildGuard的标注体系,启发了后续研究如动态安全阈值调整方法和多目标安全优化技术,推动了安全对齐领域的方法创新。
以上内容由遇见数据集搜集并总结生成


