Dolci-DPO-Model-Response-Pool
收藏Hugging Face2025-12-12 更新2025-12-14 收录
下载链接:
https://huggingface.co/datasets/allenai/Dolci-DPO-Model-Response-Pool
下载链接
链接失效反馈官方服务:
资源简介:
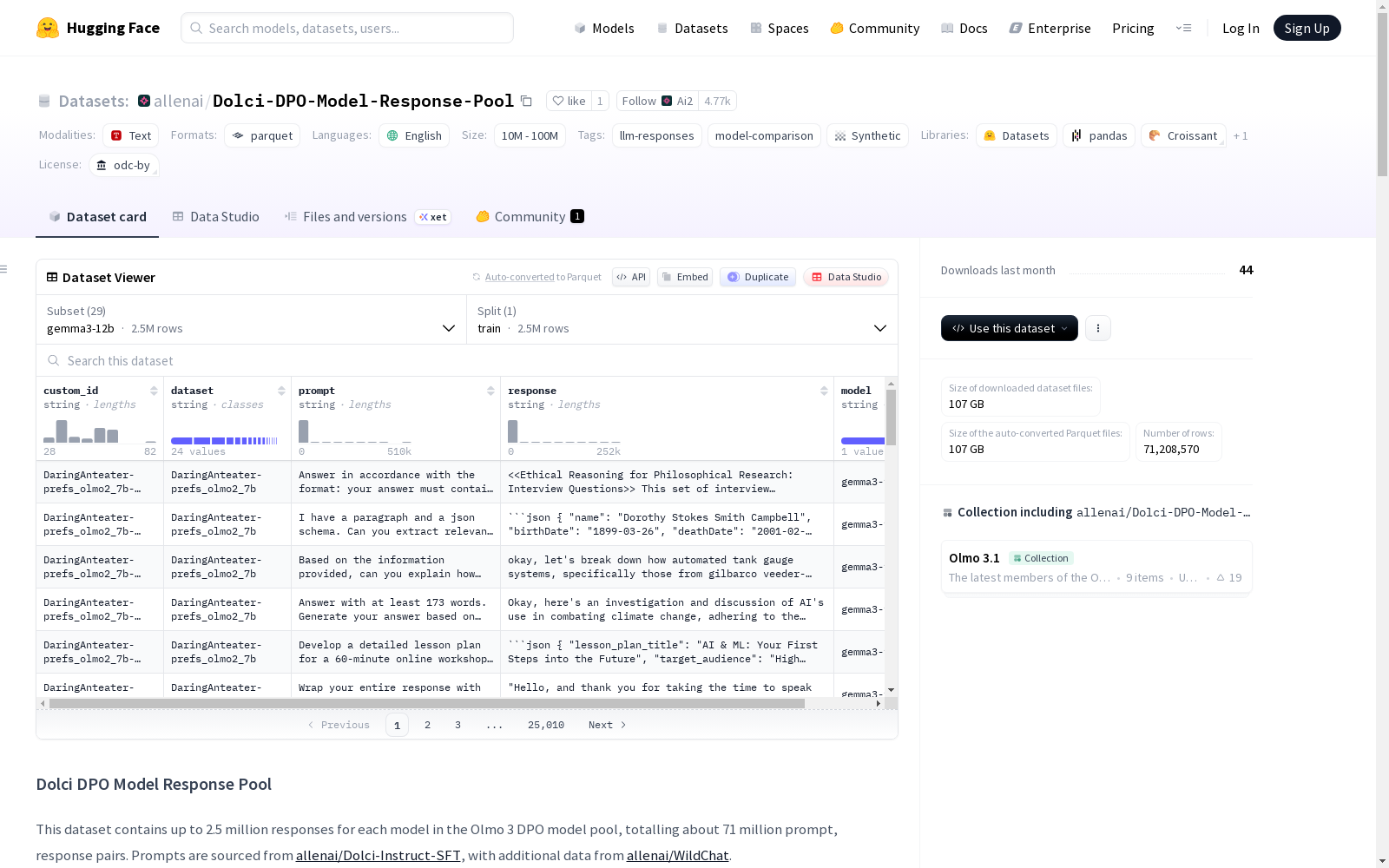
该数据集名为Dolci DPO模型响应池,包含Olmo 3 DPO模型池中每个模型多达250万条响应,总计约7100万条提示-响应对。提示来源于allenai/Dolci-Instruct-SFT和allenai/WildChat数据集。数据集结构包括多个配置,每个模型有独立的配置和响应数据。数据集的架构包括唯一标识符、来源数据集、输入提示、模型响应和模型名称等字段。此外,还提供了跨模型比较的方法和覆盖统计信息,显示不同模型的响应数量。数据集采用ODC-BY许可证,适用于研究和教育用途。
提供机构:
Allen Institute for AI
创建时间:
2025-12-10
原始信息汇总
Dolci DPO Model Response Pool 数据集概述
数据集基本信息
- 数据集名称:Dolci DPO Model Response Pool
- 发布机构:Allen Institute for AI (AllenAI)
- 许可证:ODC-BY
- 主要语言:英语 (en)
- 数据规模:100B < n < 1T
- 标签:llm-responses, model-comparison, synthetic
- 数据格式:Parquet
数据集内容与结构
该数据集包含用于Olmo 3 DPO模型池中每个模型的响应,每个模型最多包含250万个响应,总计约7100万个提示-响应对。
数据来源
- 提示主要来源于数据集:
allenai/Dolci-Instruct-SFT - 额外数据来源于数据集:
allenai/WildChat
配置与模型
数据集包含29个不同的模型配置,每个模型对应一个独立的配置。默认配置为 gemma3-4b。
可用模型系列与配置
| 模型系列 | 配置名称 |
|---|---|
| Gemma 3 | gemma3-4b, gemma3-12b, gemma3-27b |
| GPT | gpt-20b, gpt-120b, gpt-4.1-2025-04-14 |
| Mistral | mistral-24b |
| OLMo 2 | olmo2-1b, olmo2-7b, olmo2-13b, olmo2-32b |
| Phi 4 | phi4-mini-instruct |
| Qwen 3 (无推理) | qwen3-no_reasoning-0.6b, qwen3-no_reasoning-1.7b, qwen3-no_reasoning-4b, qwen3-no_reasoning-8b, qwen3-no_reasoning-14b, qwen3-no_reasoning-30b-3a, qwen3-no_reasoning-32b |
| Qwen 3 (推理) | qwen3-reasoning-1.7b, qwen3-reasoning-4b, qwen3-reasoning-8b, qwen3-reasoning-14b, qwen3-reasoning-30b-3a, qwen3-reasoning-32b |
| Qwen 3 Coder | qwen3-coder-no_reasoning-30b-3a |
| QwQ | qwq-32b |
| Yi 1.5 | yi-9b, yi-34b |
数据模式
每个配置包含以下字段:
| 字段 | 类型 | 描述 |
|---|---|---|
custom_id |
string |
提示的唯一标识符(跨模型共享) |
dataset |
string |
提示的来源数据集 |
prompt |
string |
输入的提示 |
response |
string |
模型的响应 |
model |
string |
模型名称 |
数据覆盖统计
并非每个模型都对每个提示生成了响应。数据集包含总计 2,500,999 个唯一提示。
各模型响应数量概览
| 模型 | 响应数量 |
|---|---|
gpt-4.1-2025-04-14 |
2,500,999 |
qwen3-coder-no_reasoning-30b-3a |
2,500,999 |
qwen3-no_reasoning-30b-3a |
2,500,999 |
qwen3-no_reasoning-4b |
2,500,999 |
qwen3-reasoning-30b-3a |
2,500,999 |
qwen3-reasoning-4b |
2,500,999 |
phi4-mini-instruct |
2,500,997 |
gemma3-12b |
2,500,980 |
qwen3-no_reasoning-0.6b |
2,500,075 |
qwen3-no_reasoning-14b |
2,500,075 |
qwen3-no_reasoning-32b |
2,500,075 |
mistral-24b |
2,499,303 |
qwen3-no_reasoning-1.7b |
2,499,075 |
qwen3-no_reasoning-8b |
2,499,075 |
gpt-120b |
2,498,450 |
gpt-20b |
2,495,496 |
yi-34b |
2,492,148 |
yi-9b |
2,492,148 |
olmo2-13b |
2,486,926 |
olmo2-1b |
2,486,926 |
olmo2-32b |
2,486,926 |
olmo2-7b |
2,486,926 |
qwen3-reasoning-32b |
2,460,620 |
qwq-32b |
2,453,635 |
gemma3-4b |
2,451,039 |
gemma3-27b |
2,406,872 |
qwen3-reasoning-1.7b |
2,278,035 |
qwen3-reasoning-8b |
2,233,012 |
qwen3-reasoning-14b |
1,993,762 |
使用许可与声明
- 本数据集根据 ODC-BY 许可证授权。
- 旨在根据 Ai2 的《负责任使用指南》(https://allenai.org/responsible-use) 用于研究和教育目的。
- 每个模型对其输出都有各自的使用条款。在将本数据集的部分内容用于下游训练时,请用户参考每个模型的许可证和条款。
引用
- 技术报告:https://allenai.org/olmo3.pdf
- 正式引用信息即将发布。
搜集汇总
数据集介绍
构建方式
在大型语言模型偏好优化领域,构建高质量且规模庞大的响应池是推动模型对齐研究的关键。Dolci-DPO-Model-Response-Pool数据集通过系统化的方式汇集了来自多个前沿语言模型的合成响应。其构建过程以AllenAI的Dolci-Instruct-SFT和WildChat数据集作为提示来源,确保了指令的多样性与真实性。针对每个模型配置,研究团队生成了多达250万条响应,最终整合了约7100万个提示-响应对,形成了一个覆盖29个不同模型、总计近250万独特提示的庞大语料库,为跨模型比较与分析奠定了坚实基础。
特点
该数据集的核心特点在于其广泛的模型覆盖与精细的配置划分。它囊括了Gemma 3、GPT系列、Mistral、OLMo 2、Phi 4、Qwen 3(含推理与非推理变体)、QwQ以及Yi 1.5等多个主流模型家族,共计29种具体配置,涵盖了从0.6B到120B的参数规模。数据集结构清晰,每个模型拥有独立的配置,数据以Parquet格式存储,便于高效加载与处理。字段设计简洁明了,包含唯一标识符、提示来源、原始提示、模型响应及模型名称,为研究者提供了标准化的数据接口。尤为重要的是,它支持基于相同提示的跨模型响应直接对比,为模型行为分析与性能评估提供了前所未有的便利。
使用方法
为充分利用该数据集进行学术研究,用户可通过Hugging Face的`datasets`库便捷加载。数据集支持按模型配置进行灵活调用,既可单独加载某一特定模型的全部响应,也可并行加载多个模型以构建对比集合。通过建立以`custom_id`为键的查找表,研究者能够轻松提取同一提示下不同模型的响应,实现精准的横向比较。这种设计使得该数据集天然适用于直接偏好优化、响应质量评估、模型行为分析以及指令跟随能力研究等多个方向。在使用时,需注意遵守ODC-BY许可协议,并关注各源模型自身的输出使用条款,确保研究的合规性与伦理性。
背景与挑战
背景概述
在大型语言模型(LLM)的优化与对齐研究中,直接偏好优化(DPO)作为一种无需强化学习的高效微调方法,已成为提升模型与人类价值观对齐能力的关键技术。Dolci-DPO-Model-Response-Pool数据集由艾伦人工智能研究所(Allen Institute for AI)于近期构建,旨在为DPO训练提供大规模、多样化的模型响应池。该数据集汇集了来自Gemma 3、GPT系列、Qwen 3、OLMo 2等29个不同架构与规模的先进语言模型,针对超过250万个提示生成的约7100万条响应,其提示源自Dolci-Instruct-SFT与WildChat等高质量指令数据集。该资源的核心研究问题在于通过跨模型响应比较,系统评估不同模型在指令遵循、推理能力等方面的表现差异,从而为模型选择、偏好数据构建及对齐算法开发提供实证基础,对推动语言模型安全、可控发展具有显著影响力。
当前挑战
该数据集致力于解决语言模型对齐与优化中的关键挑战,即如何高效获取大规模、高质量的偏好数据以训练鲁棒的DPO模型。首要挑战在于模型响应的质量与一致性评估,不同模型在相同提示下可能产生语义正确但风格迥异、甚至包含隐性偏见的响应,这为偏好标注与模型比较带来了复杂性。其次,构建过程中面临多模型协同与数据管理的难题,需协调数十个模型的推理流程,确保响应覆盖的广泛性与数据格式的统一,同时处理各模型自身许可协议的合规性问题。此外,数据集的规模与多样性要求对计算资源与存储架构提出了极高需求,如何在保证数据完整性的前提下实现高效存取与跨模型对比分析,亦是实际构建中的技术瓶颈。
常用场景
经典使用场景
在大型语言模型(LLM)的评估与比较研究中,Dolci-DPO-Model-Response-Pool数据集提供了一个标准化的基准平台。该数据集汇集了来自Gemma、GPT、Qwen等主流模型家族对同一批指令提示的响应,使得研究者能够系统性地分析不同模型在文本生成质量、风格一致性与逻辑连贯性等方面的表现。通过跨模型对比,该数据集常被用于深入探究模型架构、参数量以及训练策略对生成结果的影响,为模型性能的量化评估奠定了数据基础。
解决学术问题
该数据集有效解决了大语言模型领域内模型响应质量缺乏统一、可复现比较基准的学术难题。通过提供大规模、多模型并行的响应数据,它支持对模型对齐技术、偏好优化(DPO)效果以及指令跟随能力的实证研究。其意义在于促进了模型评估从单一指标向多维度、细粒度分析的转变,为理解模型行为差异提供了丰富的实证材料,推动了模型可解释性与鲁棒性研究的深入发展。
衍生相关工作
围绕该数据集,已衍生出多项经典研究工作,主要集中在模型响应自动评估、偏好学习以及多模型集成等领域。例如,基于其跨模型响应对比,研究者开发了新的评估指标以量化生成文本的多样性与忠实度。同时,该数据集也被用于训练响应排序模型或构建强化学习中的奖励模型,进一步推动了基于人类反馈的优化方法发展。这些工作显著拓展了大语言模型评估与对齐技术的研究边界。
以上内容由遇见数据集搜集并总结生成


