SVIRO
收藏arXiv2020-01-10 更新2024-06-21 收录
下载链接:
https://sviro.kl.dfki.de
下载链接
链接失效反馈官方服务:
资源简介:
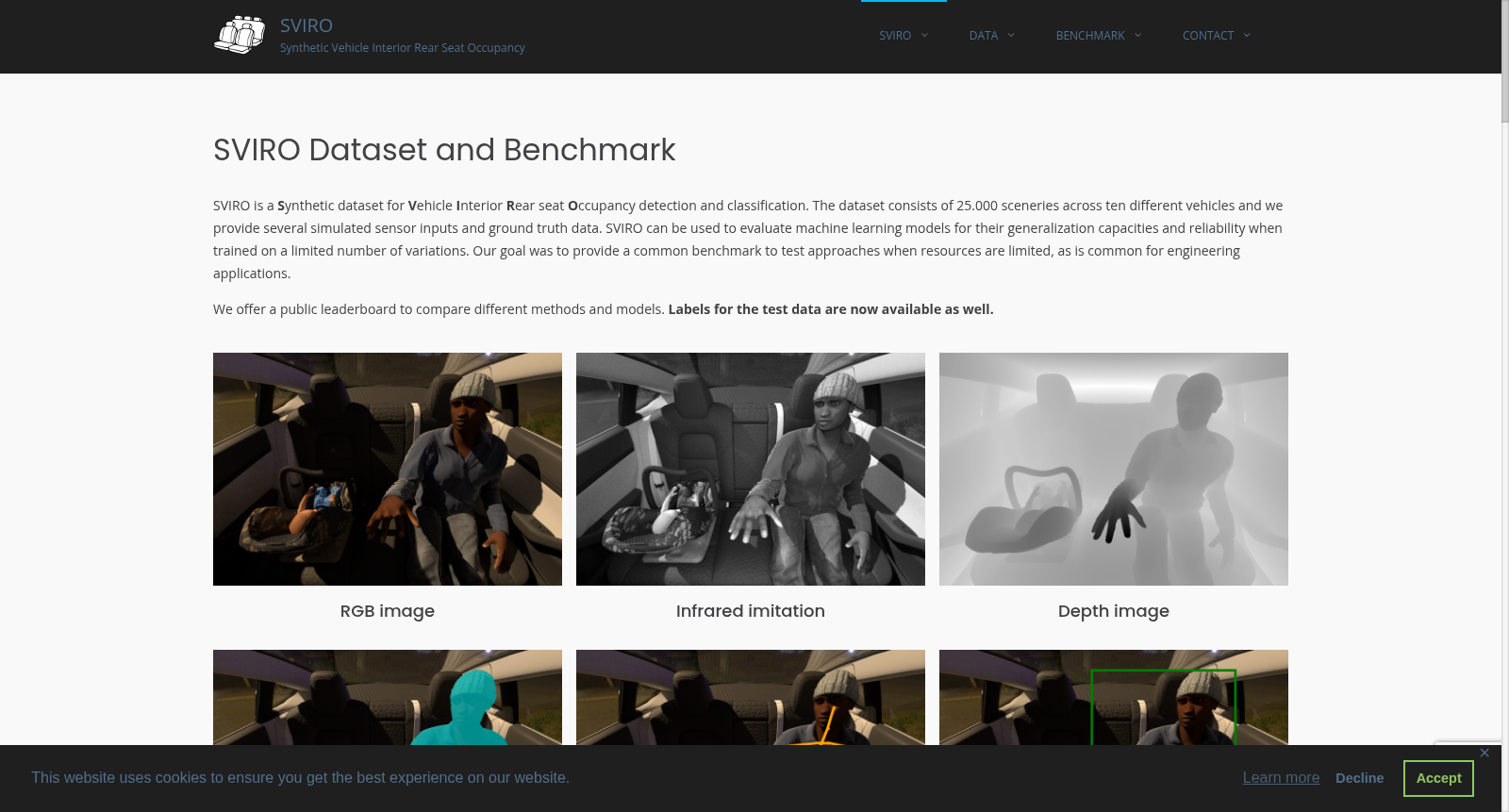
SVIRO数据集由德国人工智能研究中心创建,专注于车辆内部后座乘客的检测与分类。该数据集包含10种不同车辆内部场景,共计25000条数据,涵盖了对象检测、实例分割、姿态估计和深度图像等多种数据类型。数据集的创建过程中使用了Blender等3D图形软件,模拟真实环境中的光照和材质。SVIRO数据集的应用领域主要集中在自动驾驶和车辆安全系统,旨在通过机器学习模型提高对后座乘客状态的识别准确性和可靠性。
The SVIRO dataset was created by the German Research Centre for Artificial Intelligence, focusing on the detection and classification of rear-seat passengers inside vehicles. It includes 10 distinct vehicle interior scenarios, with a total of 25,000 data entries, covering multiple data modalities such as object detection, instance segmentation, pose estimation, and depth images. During the dataset's construction, 3D graphics software including Blender was utilized to simulate real-world lighting and materials. The SVIRO dataset is primarily applied in autonomous driving and vehicle safety systems, with the goal of enhancing the accuracy and reliability of rear-seat passenger state recognition through machine learning models.
提供机构:
德国人工智能研究中心
创建时间:
2020-01-10
搜集汇总
数据集介绍
构建方式
在车辆内部感知领域,SVIRO数据集通过合成方法构建,以应对真实数据采集的复杂性。该数据集利用Blender开源软件创建三维场景,结合高动态范围图像模拟光照,并采用真实市场中的儿童安全座椅三维模型。人类模型通过MakeHuman随机生成,并赋予多样化姿态与服饰。数据集涵盖十款不同车型的后排座位场景,通过固定纹理与背景的分割,确保训练集与测试集在对象、座椅及环境上互不重叠,从而构建出具有可控变异性的合成数据环境。
特点
SVIRO数据集的特点在于其专注于有限变异条件下的机器学习模型泛化能力评估。与常见高变异背景的数据集不同,SVIRO通过统一背景与稀疏类别表征,模拟工程实践中资源受限的场景。数据集提供多模态标注,包括边界框、实例分割掩码、人体姿态关键点及深度图像,并特别模拟了主动红外相机系统以应对暗光环境。其设计使得模型需在已知车辆内训练后,泛化至全新车型与未知对象,为领域适应与模型鲁棒性研究提供了独特平台。
使用方法
该数据集适用于多种计算机视觉任务,包括分类、目标检测、实例分割及姿态估计。用户可利用提供的RGB图像、灰度红外模拟图像及深度数据进行模型训练与测试。数据集已按车型与对象分割为训练集与测试集,支持跨车辆泛化评估。研究人员可基于固定纹理版本或结合随机化背景的增强版本进行实验,以探究模型在有限变异下的性能。此外,数据集的合成特性允许生成特定条件下的图像,便于进行可控环境下的理论分析与方法验证。
背景与挑战
背景概述
随着自动驾驶技术的迅猛发展,车内感知系统逐渐成为计算机视觉领域的研究热点,尤其在乘员检测与分类任务中展现出重要应用价值。SVIRO数据集由卢森堡IEE公司、德国人工智能研究中心及凯泽斯劳滕大学等机构的研究团队于2020年联合创建,旨在解决车辆后座乘员状态识别中的模型泛化与可靠性问题。该数据集通过合成十款不同车型的内饰场景,提供了丰富的标注数据,包括边界框、实例分割掩码、姿态估计关键点及深度图像,为评估机器学习模型在有限样本变异下的适应能力奠定了基准。其核心研究聚焦于提升模型在真实车载环境中的鲁棒性,对推动智能座舱安全系统的发展具有显著影响力。
当前挑战
SVIRO数据集致力于应对车辆内部乘员检测与分类任务中的双重挑战。在领域问题层面,现有模型在训练数据变异有限时,难以泛化至未见过的车型内饰、儿童座椅类型及光照条件,导致在真实应用中分类与分割性能显著下降。构建过程中,研究团队面临合成数据与真实场景间的域差异难题,需平衡视觉复杂性与计算可处理性,同时确保纹理、背景及对象模型的多样性以模拟真实环境。此外,数据生成需克服多模态标注的一致性整合,以及合成红外图像与真实传感数据间的仿真差距,这些挑战共同凸显了该数据集在推动域适应与模型鲁棒性研究方面的独特价值。
常用场景
经典使用场景
在车辆内部感知领域,SVIRO数据集为评估机器学习模型在有限变体训练条件下的泛化能力提供了基准平台。该数据集通过合成十种不同车型的后座场景,模拟了真实应用中背景纹理固定、类内变体稀疏的挑战性环境。研究者可利用其提供的边界框、实例分割掩码、关键点及深度图像,系统分析模型在跨车辆环境迁移时的鲁棒性,尤其适用于探究模型对未知座椅纹理、乘客姿态及光照条件的适应机制。
实际应用
该数据集直接服务于汽车工业中的智能座舱安全系统开发。例如,通过后座乘员检测与分类,可优化安全气囊触发策略、提醒安全带系扣或防止儿童滞留车内。其合成的红外仿真相机图像契合车载主动红外传感系统的实际需求,助力模型在低光照条件下的稳定性验证。此外,数据集支持跨车型快速部署,降低车企针对不同内饰重复采集数据的成本,为自动驾驶中人机交接场景的座舱环境理解提供了可扩展的仿真测试环境。
衍生相关工作
SVIRO启发了多项围绕合成数据与域适应的后续研究。例如,基于其构建的基准被用于探索解耦表征学习在车辆内部场景分解中的有效性,或结合域随机化技术提升模型对未知内饰的泛化能力。部分工作将其与真实红外图像进行跨域对比,验证合成到真实迁移的可行性。同时,该数据集为《MONET: Unsupervised Scene Decomposition and Representation》等场景解构研究提供了更接近实际应用的复杂环境,推动了合成数据在安全关键系统中的方法论创新。
以上内容由遇见数据集搜集并总结生成


