FINear-final
收藏Hugging Face2025-02-10 更新2025-02-10 收录
下载链接:
https://huggingface.co/datasets/jerry128/FINear-final
下载链接
链接失效反馈官方服务:
资源简介:
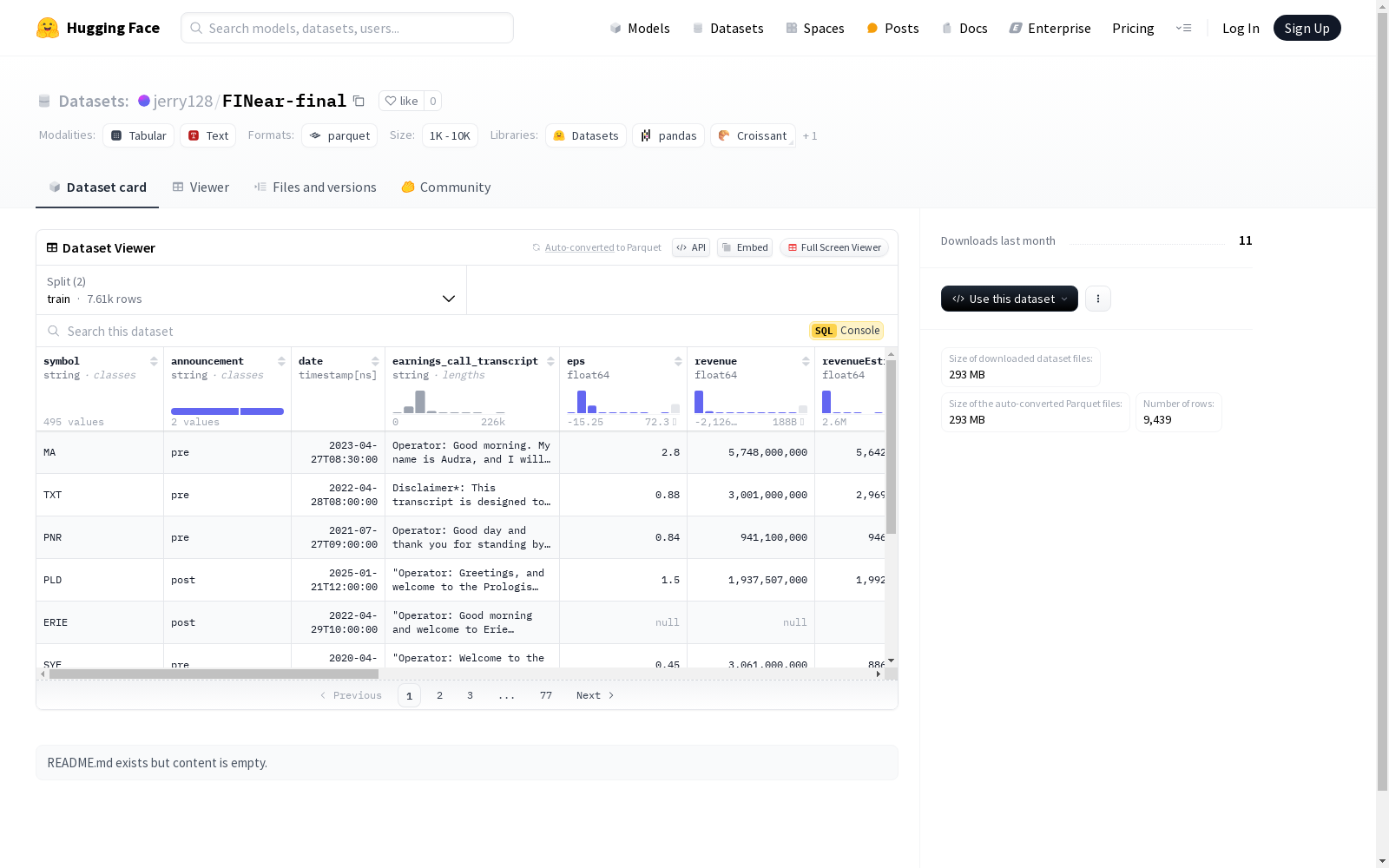
该数据集包含了股票相关的信息,如股票代码、公告、日期、财报电话会议记录、每股收益、收入、预估收入、预估每股收益、收盘价、开盘价、股票名称、季度、季度财报总结、市场预期等。数据集分为训练集和测试集,可用于机器学习模型的训练和评估。
This dataset contains stock-related information, including stock ticker symbols, announcements, dates, earnings call transcripts, earnings per share (EPS), revenue, revenue estimates, EPS estimates, closing prices, opening prices, stock names, quarters, quarterly earnings summaries, market expectations, etc. The dataset is divided into a training set and a test set, which can be used for training and evaluating machine learning models.
创建时间:
2025-02-08
原始信息汇总
数据集概述
数据集名称
Jerry128/FINear-final
数据集特征
- symbol: 字符串类型,表示股票代码
- announcement: 字符串类型,表示公告内容
- date: 时间戳类型(纳秒),表示日期
- earnings_call_transcript: 字符串类型,表示财报电话会议记录
- eps: 浮点数类型,表示每股收益
- revenue: 浮点数类型,表示收入
- revenueEstimated: 浮点数类型,表示预计收入
- epsEstimated: 浮点数类型,表示预计每股收益
- closing_price: 浮点数类型,表示收盘价
- opening_price: 浮点数类型,表示开盘价
- stock_name: 字符串类型,表示股票名称
- quarter: 整数类型,表示季度
- qwen_summarized_earnings_transcript: 字符串类型,表示财报电话会议摘要
- qwen_pre_market_expectations: 字符串类型,表示市场预期
- expectations: 字符串类型,表示预期
数据集划分
- 训练集:
- 文件大小:458,503,833 字节
- 示例数量:7,605
- 测试集:
- 文件大小:107,418,723 字节
- 示例数量:1,834
数据集大小
- 下载大小:293,362,343 字节
- 总大小:565,922,556 字节
配置
- 默认配置:
- 训练集: data/train-*
- 测试集: data/test-*
搜集汇总
数据集介绍
构建方式
FINear-final数据集的构建主要围绕财务报告及市场预期相关数据展开。该数据集整合了股票的财务指标、股价信息、财报摘要、市场预期等多维度信息,通过从金融机构及公开市场中收集相关数据,经过清洗、整理后,形成了包含多个字段的综合数据集。
使用方法
使用该数据集时,用户可以根据HuggingFace提供的路径访问训练集和测试集。数据集以CSV或类似格式存储,可以直接加载到数据分析或机器学习框架中。用户可以依据具体的研究需求,对数据集中的字段进行筛选、整合和分析,进而开展相应的金融分析和模型构建工作。
背景与挑战
背景概述
FINear-final数据集,诞生于金融信息研究领域,其创建旨在为投资者提供精确的财务预测模型。该数据集由一系列研究人员合作开发,汇集了股票市场的多维数据,包括股票代码、公告、日期、财报电话会议记录、每股收益、收入及其预估、收盘价和开盘价等详细信息。自推出以来,该数据集以其全面性和时效性,为金融分析、量化投资策略的制定等领域提供了强有力的数据支撑,对相关领域的研究产生了显著影响。
当前挑战
尽管FINear-final数据集为金融信息分析提供了丰富的资源,但其在构建和应用过程中也面临着诸多挑战。首先,数据集的构建需要处理大量非结构化文本数据,如财报电话会议记录的文本摘要,这要求高精度自然语言处理技术的应用。其次,预测模型的准确性依赖于数据的时效性和完整性,而市场信息的多变性和数据的不完整性为模型的构建带来了难题。再者,如何有效利用该数据集进行特征工程,提取对预测有重要影响的特征,是当前研究的一个重要挑战。
常用场景
经典使用场景
在金融文本挖掘领域,FINear-final数据集的典型应用场景在于,通过对财务报告、市场预期等文本信息的分析,构建预测模型,以预测股票市场的收益与价格波动。
解决学术问题
该数据集解决了金融领域中如何准确提取和利用财务报告、市场预期等非结构化文本信息的问题,为股票收益预测、市场情绪分析等学术研究提供了可靠的数据基础。
实际应用
在实际应用中,FINear-final数据集被广泛应用于金融分析、投资决策、风险管理等领域,有助于金融机构提高决策的科学性和有效性。
数据集最近研究
最新研究方向
在金融数据分析领域,FINear-final数据集以其详尽的财务报告和股市动态信息,成为研究焦点。近期研究集中于利用该数据集进行股价预测模型的构建与优化,通过分析财务报表、市场预期与实际收益之间的关系,探索更为精确的预测算法。此外,该数据集还被用于研究市场情绪对股价波动的影响,以及结合自然语言处理技术,从 earnings call 转录中提取关键信息,以辅助投资决策。这些研究不仅推动了金融科技的发展,也为投资者提供了更为科学的决策依据。
以上内容由遇见数据集搜集并总结生成


