FLEURS-R
收藏arXiv2024-08-12 更新2024-08-14 收录
下载链接:
https://huggingface.co/datasets/google/fleurs-r
下载链接
链接失效反馈资源简介:
FLEURS-R数据集是由谷歌DeepMind创建的多语言语音语料库,包含102种语言的高质量并行语音和文本数据。该数据集通过应用先进的语音恢复技术,显著提升了音频的清晰度和保真度,特别适用于低资源语言的语音生成任务。数据集的创建过程中,采用了创新的语音处理管道和模型,确保了语音内容的完整性和自然性。FLEURS-R数据集主要应用于推动多语言和跨语言的语音技术研究,特别是在文本到语音和语音到语音翻译等领域。
The FLEURS-R dataset is a multilingual speech corpus developed by Google DeepMind, which encompasses high-quality parallel speech and text data across 102 languages. By leveraging advanced speech restoration technologies, this dataset notably enhances audio clarity and fidelity, making it exceptionally well-suited for speech generation tasks in low-resource languages. During its construction, an innovative speech processing pipeline and models were employed to guarantee the integrity and naturalness of the speech content. Primarily, the FLEURS-R dataset is utilized to advance research in multilingual and cross-lingual speech technologies, especially in domains such as text-to-speech and speech-to-speech translation.
提供机构:
谷歌DeepMind
创建时间:
2024-08-12
AI搜集汇总
数据集介绍
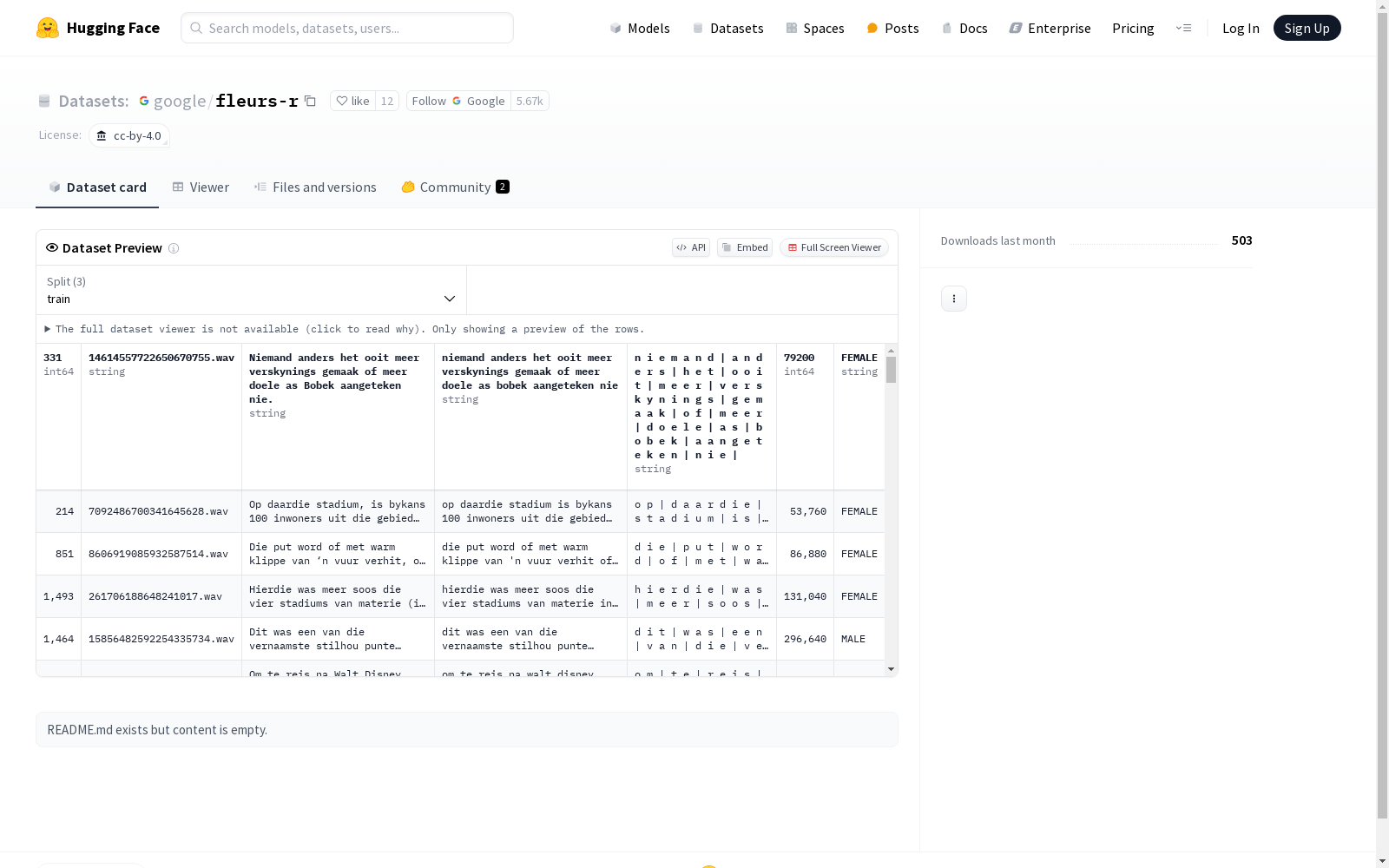
构建方式
FLEURS-R数据集的构建基于FLEURS多语言语音语料库,通过应用语音恢复模型Miipher对其进行处理,以提升音频质量和保真度。Miipher模型通过提取噪声语音的声学特征,并使用DF-Conformer将其转换为干净的声学特征,最终通过WaveFit神经声码器生成高质量的语音波形。为了适应多语言特性,Miipher模型的声学特征提取器从w2v-BERT替换为Universal Speech Model (USM),该模型预训练于包含300多种语言的1200万小时语音数据上。FLEURS-R数据集的采样率从16 kHz提升至24 kHz,同时保留了原始语料库的语义内容和N-way并行特性。
特点
FLEURS-R数据集的主要特点在于其高质量的多语言语音数据,涵盖102种语言,其中80%为低资源语言。该数据集通过语音恢复技术显著提升了音频的自然度和清晰度,减少了噪声和混响,使其更适合于语音生成任务,如文本到语音(TTS)、语音到语音翻译(S2ST)和语音转换(VC)。此外,FLEURS-R保持了与原始FLEURS语料库相同的N-way并行结构,确保了在多语言和低资源环境下的广泛适用性。
使用方法
FLEURS-R数据集可广泛应用于多语言语音生成任务,包括但不限于文本到语音合成、语音翻译和语音转换。研究者可以通过Hugging Face平台获取该数据集,并用于训练和评估多语言TTS模型。由于数据集的高质量音频和多语言特性,模型在低资源语言上的表现有望得到显著提升。此外,FLEURS-R还可用于研究语音恢复技术的效果,以及在不同语言和语音条件下的模型泛化能力。
背景与挑战
背景概述
FLEURS-R数据集是由Google DeepMind团队于近期推出的多语言语音语料库,旨在推动低资源语言的语音生成技术研究。该数据集是FLEURS语料库的增强版本,通过应用语音恢复模型Miipher,显著提升了音频质量,采样率从16 kHz提高到24 kHz,同时保留了原始语料库的N-way并行结构,涵盖102种语言,其中80%为低资源语言。FLEURS-R的发布旨在促进多语言、跨语言以及低资源环境下的语音生成任务研究,如文本到语音(TTS)、语音到语音翻译(S2ST)和语音转换(VC)。该数据集的推出对多语言语音生成领域具有重要意义,尤其是在提升低资源语言的语音合成质量方面。
当前挑战
FLEURS-R数据集的构建面临多重挑战。首先,语音恢复模型Miipher最初仅支持英语,因此在处理多语言数据时,研究人员需要对模型进行调整,引入通用语音模型(USM)以适应多语言特征提取。其次,尽管语音恢复技术显著提升了音频质量,但在处理过程中仍可能引入信号处理伪影,需通过自动语音识别(ASR)过滤来确保数据质量。此外,多语言环境下的语音生成任务面临语言多样性和低资源语言的复杂性,如何在保持语义内容的同时提升语音自然度,是该数据集面临的主要挑战。最后,如何在多语言环境下进行大规模主观评估,尤其是针对低资源语言,也是一个亟待解决的问题。
常用场景
经典使用场景
FLEURS-R数据集的经典使用场景主要集中在多语言语音生成任务中,尤其是低资源语言的文本到语音(TTS)生成。该数据集通过应用语音恢复模型Miipher,显著提升了原始FLEURS数据集的音频质量,使其在TTS、语音到语音翻译(S2ST)以及语音转换(VC)等任务中表现更为出色。其N-way并行语音和文本结构,使得模型能够在多语言环境下进行高效的语音生成,尤其是在低资源语言的语音合成中展现出显著优势。
实际应用
FLEURS-R数据集在实际应用中具有广泛的前景,尤其是在多语言语音合成、语音翻译和语音转换等领域。例如,在多语言智能助手、语音翻译软件以及跨语言语音通信系统中,FLEURS-R的高质量语音数据可以显著提升用户体验。此外,该数据集还适用于开发零样本和少样本学习的多语言TTS系统,使得在资源匮乏的语言环境中也能实现高质量的语音合成。这些应用场景不仅提升了语音技术的普及性,还为全球范围内的多语言交流提供了技术支持。
衍生相关工作
FLEURS-R数据集的发布催生了一系列相关的经典工作,尤其是在多语言语音生成和语音恢复领域。例如,基于FLEURS-R的TTS模型研究展示了如何在多语言环境下实现高质量的语音合成,尤其是在低资源语言中的应用。此外,语音恢复模型Miipher的改进版本也在该数据集的基础上得到了进一步优化,提升了其在多语言环境中的适用性。这些衍生工作不仅推动了语音生成技术的进步,还为多语言语音处理领域的研究提供了新的方向和灵感。
以上内容由AI搜集并总结生成


