quotidiana
收藏Hugging Face2025-10-27 更新2025-10-28 收录
下载链接:
https://huggingface.co/datasets/ZurichNLP/quotidiana
下载链接
链接失效反馈官方服务:
资源简介:
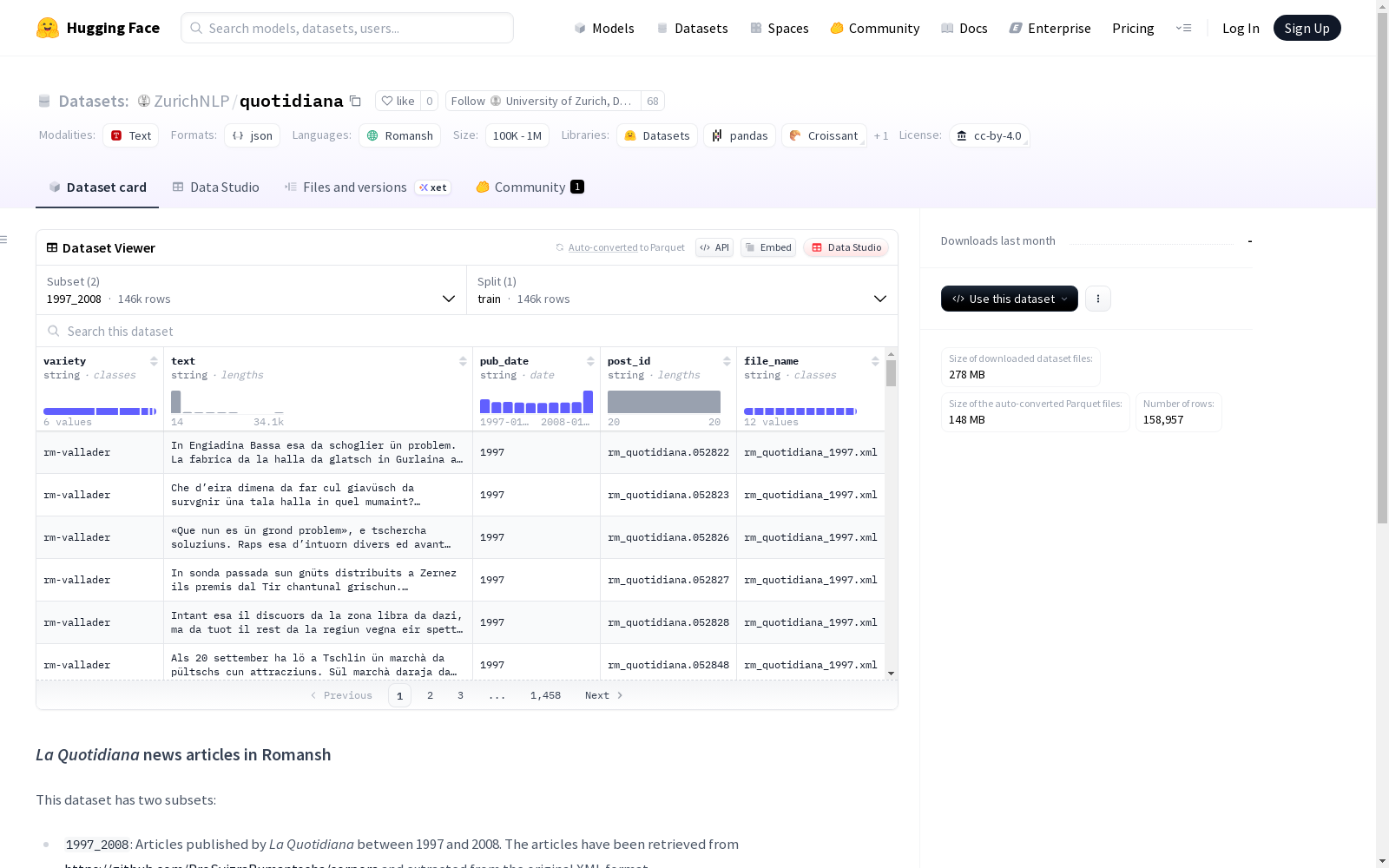
该数据集包含两个子集:1997_2008和2021_2025。1997_2008子集包含1997年至2008年间《La Quotidiana》发表的罗曼什语文章,这些文章从ProSvizraRumantscha的corpora中检索并从原始XML格式中提取。2021_2025子集包含2021年至2025年间《La Quotidiana》发表的文章,这些文章从WXR WordPress导出文件中提取。数据集中的文章包括不同的罗曼什语变体:Rumantsch Grischun、Sursilvan、Sutsilvan、Surmiran、Puter和Vallader。1997_2008子集的变体是通过在2021_2025配置上训练的支持向量机分类器自动标注的。2021_2025子集的变体是基于《La Quotidiana》编辑的手动处理。数据集遵循CC BY 4.0许可发布。
创建时间:
2025-10-27
原始信息汇总
数据集概述
基本信息
- 数据集名称: La Quotidiana news articles in Romansh
- 许可证: CC BY 4.0
- 语言: 罗曼什语 (rm)
数据子集
1997_2008
- 时间范围: 1997年至2008年
- 数据来源: 从原始XML格式提取,源自https://github.com/ProSvizraRumantscha/corpora
- 文件格式: JSONL
2021_2025
- 时间范围: 2021年至2025年
- 数据来源: 从WXR WordPress导出文件提取
- 文件格式: JSONL
语言变体标注
包含的罗曼什语变体
- Rumantsch Grischun (rm-rumgr)
- Sursilvan (rm-sursilv)
- Sutsilvan (rm-sutsilv)
- Surmiran (rm-surmiran)
- Puter (rm-puter)
- Vallader (rm-vallader)
标注方法
- 1997_2008子集: 使用在2021_2025配置等数据上训练的SVM分类器进行自动标注
- 2021_2025子集: 基于La Quotidiana编辑的手动处理
版权信息
- 版权方: La Quotidiana
- 许可证链接: https://creativecommons.org/licenses/by/4.0/
搜集汇总
数据集介绍
构建方式
在罗曼什语新闻语料库的构建过程中,quotidiana数据集采用双时段采集策略。1997至2008年间的语料源自GitHub开源项目,通过XML格式解析技术实现原始文档的结构化提取;2021至2025年间的语料则基于WordPress平台的WXR导出文件进行数据采集。这种多源异构数据的整合方式,既保留了历史语料的文献价值,又确保了当代语料的时效性。
特点
该数据集最显著的特征在于其语言变体的精细标注体系。完整覆盖罗曼什语的六大方言变体:格劳宾登罗曼什语、苏尔塞尔瓦语、苏茨塞尔瓦语、苏尔米兰语、普特语和瓦拉德尔语。特别值得注意的是,早期语料采用基于支持向量机的自动分类技术,而近期语料则依托《La Quotidiana》编辑团队的人工标注,形成了混合标注范式。这种设计为语言变体研究提供了珍贵的对比样本。
使用方法
研究者可通过HuggingFace平台直接加载两个独立配置的数据子集。1997_2008配置适用于历时语言变迁研究,2021_2025配置则更适合当代语言现象分析。使用时应特别注意不同子集的标注方法论差异:早期子集依赖自动分类结果,近期子集则采用人工标注标准。所有语料均遵循CC BY 4.0许可协议,支持学术研究与非商业用途的灵活使用。
背景与挑战
背景概述
在罗曼什语这一濒危语言资源保护领域,quotidiana数据集由瑞士罗曼什语促进组织(Pro Svizra Rumantscha)于2023年构建完成,其核心价值在于系统收录了《La Quotidiana》报社1997-2008与2021-2025两个时期发行的新闻文本。该数据集通过精确标注格劳宾登罗曼什语、苏塞尔瓦语等六种方言变体,为研究罗曼什语历时演变与方言接触提供了珍贵语料,对濒危语言数字化存档及计算语言学模型开发具有里程碑意义。
当前挑战
该数据集面临方言自动分类的技术挑战,早期文本需通过基于SVM分类器的跨时期迁移学习实现方言标注,而不同方言间词汇与语法结构的相似性增加了分类误差风险。在数据构建层面,原始XML与WordPress导出格式的异构性要求设计多模态解析方案,同时确保手工标注与自动标注体系在六种方言变体中的标注一致性,这对语言资源建设的标准化提出了更高要求。
常用场景
经典使用场景
在罗曼什语语言资源稀缺的背景下,quotidiana数据集为计算语言学领域提供了珍贵的历时性文本资源。该数据集通过收录1997至2025年间《La Quotidiana》新闻文章,构建了覆盖六大方言变体的平行语料库,特别适用于低资源语言模型的跨方言迁移学习研究。研究者可借助其标注体系开展方言分类器训练,探索多方言文本的表示学习与语义对齐机制。
解决学术问题
该数据集有效缓解了罗曼什语在自然语言处理研究中的资源匮乏困境。通过提供机器与人工双重标注的方言变体标签,为语言变异研究提供了量化分析基础,助力解决低资源语言模型泛化能力不足的核心难题。其跨二十余年的文本跨度更支持语言演变研究,对濒危语言数字化保护具有重要文献价值。
衍生相关工作
围绕该数据集已衍生出多项标志性研究,包括基于SVM的罗曼什语方言自动分类器构建、跨方言神经机器翻译系统的性能优化等。瑞士语言技术团队进一步开发了融合该语料的预训练模型RomontschBERT,相关成果为其他濒危语言资源建设提供了可复用的技术范式,推动少数民族语言计算研究进入新阶段。
以上内容由遇见数据集搜集并总结生成


