alinia/pii_detection_ner
收藏Hugging Face2026-05-05 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/alinia/pii_detection_ner
下载链接
链接失效反馈官方服务:
资源简介:
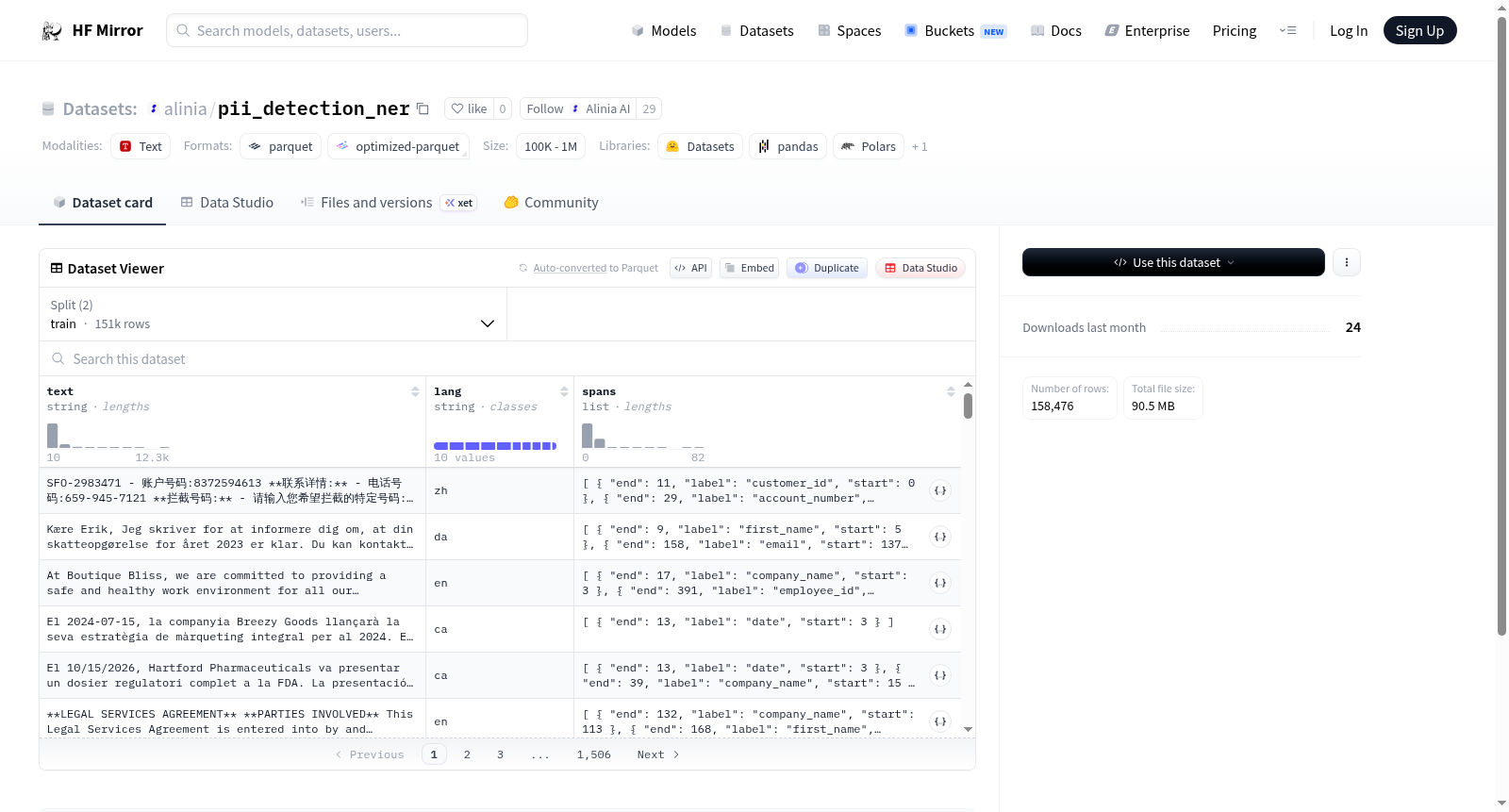
该数据集是一个用于自然语言处理任务的结构化数据集,包含文本、语言和标注范围。具体来说,每个数据样本由text(原始文本字符串)、lang(文本语言代码字符串)和spans(一个列表,每个元素包含start、end和label字段,用于标注文本中的实体或特定范围,如命名实体识别或文本分类)组成。数据集分为train(训练集,包含150,552个示例,大小约152.6 MB)和val(验证集,包含7,924个示例,大小约8.0 MB)两个分割,总下载大小约90.5 MB,总数据集大小约160.7 MB。数据格式支持多语言文本处理,适用于序列标注、信息提取等NLP应用。
This dataset is a structured dataset for natural language processing tasks, containing text, language, and annotated spans. Specifically, each data sample consists of text (raw text string), lang (language code string for the text), and spans (a list where each element includes start, end, and label fields, used to annotate entities or specific ranges in the text, such as for named entity recognition or text classification). The dataset is divided into train (training set, with 150,552 examples, approximately 152.6 MB) and val (validation set, with 7,924 examples, approximately 8.0 MB) splits, with a total download size of about 90.5 MB and a total dataset size of about 160.7 MB. The data format supports multilingual text processing and is suitable for NLP applications like sequence labeling and information extraction.
提供机构:
alinia
搜集汇总
数据集介绍
构建方式
该数据集聚焦于个人信息识别(PII)的命名实体检测任务,通过大规模文本数据构建而成。其核心结构包含原始文本(text)、语种标识(lang)以及标注实体跨度(spans),其中跨度字段详细记录了每个实体的起始位置(start)、终止位置(end)及标签类型(label)。数据划分为训练集(150,552条)与验证集(7,924条),共计超过15万条样本,确保了模型训练与评估的充足素材。
特点
数据集兼具多语种覆盖与细粒度标注两大特性。语种字段为跨语言信息抽取研究提供了基础,而跨度标签(如姓名、地址、证件号等)则实现了对个人敏感信息的精准定位。其规模达1.6亿字节,训练集与验证集的比例约为19:1,既保证了数据多样性,又预留了可靠的性能评估空间。
使用方法
方法上,该数据集适用于序列标注任务的模型训练与评估。用户可通过HuggingFace Datasets库加载配置为'default'的预划分数据,直接获取训练与验证分片。结合span字段的起止坐标,可轻松构建基于Transformer的命名实体识别模型,通过预测文本中每个token的标签来实现对PII信息的自动屏蔽或脱敏处理。
背景与挑战
背景概述
在自然语言处理与隐私保护的交叉领域中,个人可识别信息(PII)的自动检测成为了保障数据安全与合规的关键技术。pii_detection_ner数据集应运而生,由相关研究机构于近年构建,旨在通过命名实体识别(NER)范式解决文本中PII元素的精确识别问题。该数据集包含逾15万条训练样本及近8千条验证样本,覆盖多种语言与标签类型,为机器学习模型提供了大规模、多样化的标注资源。其核心研究问题在于提升PII检测的泛化能力与鲁棒性,从而支撑隐私保护自动化系统的高效运作。作为领域内的重要基准,该数据集推动了PII识别技术的标准化评估,对数据脱敏、合规审查等应用具有深远影响。
当前挑战
当前,pii_detection_ner数据集所面临的挑战主要源于领域问题的复杂性与构建过程的细微性。在领域层面,PII检测的困难在于文本中个人信息的定义与边界往往模糊,例如地址、电话号码等实体可能嵌套或跨句存在,且不同语言文化背景下PII的表示方式差异显著,致使模型泛化性能受限。在构建过程中,数据标注的准确性是一大难题,因为PII实体类别繁多(如姓名、身份证号、邮箱等),标注员需严格遵循自定义标准,同时避免由于标注不一致而引入噪声。此外,大规模多源文本的收集面临隐私合规风险,数据脱敏程度需平衡模型学习与个人权利保护,这些因素共同构成了该数据集实际应用中的核心挑战。
常用场景
经典使用场景
在自然语言处理与数据安全交汇的领域中,pii_detection_ner数据集为命名实体识别任务提供了极具价值的标注资源。该数据集聚焦于个人可识别信息的检测,涵盖文本、语言标签及实体跨度标注,支持对敏感信息的精准定位与分类。研究者常利用该数据集训练模型,以识别文本中诸如姓名、身份证号、电话号码等隐私要素,其细粒度的标注格式为序列标注任务奠定了坚实基础。这一经典应用场景不仅推动了命名实体识别技术在隐私保护方向的发展,更成为评估模型性能的关键基准。
衍生相关工作
基于pii_detection_ner数据集,一系列经典工作应运而生,拓宽了隐私信息检测的技术边界。研究者提出了融合预训练语言模型与条件随机场的混合架构,显著提升了实体边界识别的准确率。另有一些工作探索了对抗训练与数据增强策略,增强了模型对噪声文本的鲁棒性。此外,该数据集激发了跨领域迁移学习的研究,将模型能力拓展至医患对话或金融交易记录等专业场景。这些衍生工作不仅反哺了命名实体识别的基础理论,还催生了隐私合规自动化评估等新兴研究方向,持续推动着数据安全领域的学术进步。
数据集最近研究
最新研究方向
在数据隐私保护与人工智能伦理备受瞩目的当下,pii_detection_ner数据集聚焦于命名实体识别技术对个人身份信息(PII)的精准检测,成为应对数据泄露与隐私风险的关键工具。该数据集涵盖多语种文本与丰富的标注跨度,为研究前沿的细粒度隐私实体识别提供了基准,尤其在大语言模型训练数据清洗、合规审计与匿名化处理等热点应用中发挥着基石作用。其推动的自动PII识别技术正助力企业满足GDPR等法规要求,同时加速了隐私保护从规则驱动向深度学习范式的转型,对构建可信AI系统具有深远意义。
以上内容由遇见数据集搜集并总结生成


