CLEVER
收藏arXiv2025-05-20 更新2025-05-22 收录
下载链接:
https://huggingface.co/datasets/amitayusht/clever
下载链接
链接失效反馈官方服务:
资源简介:
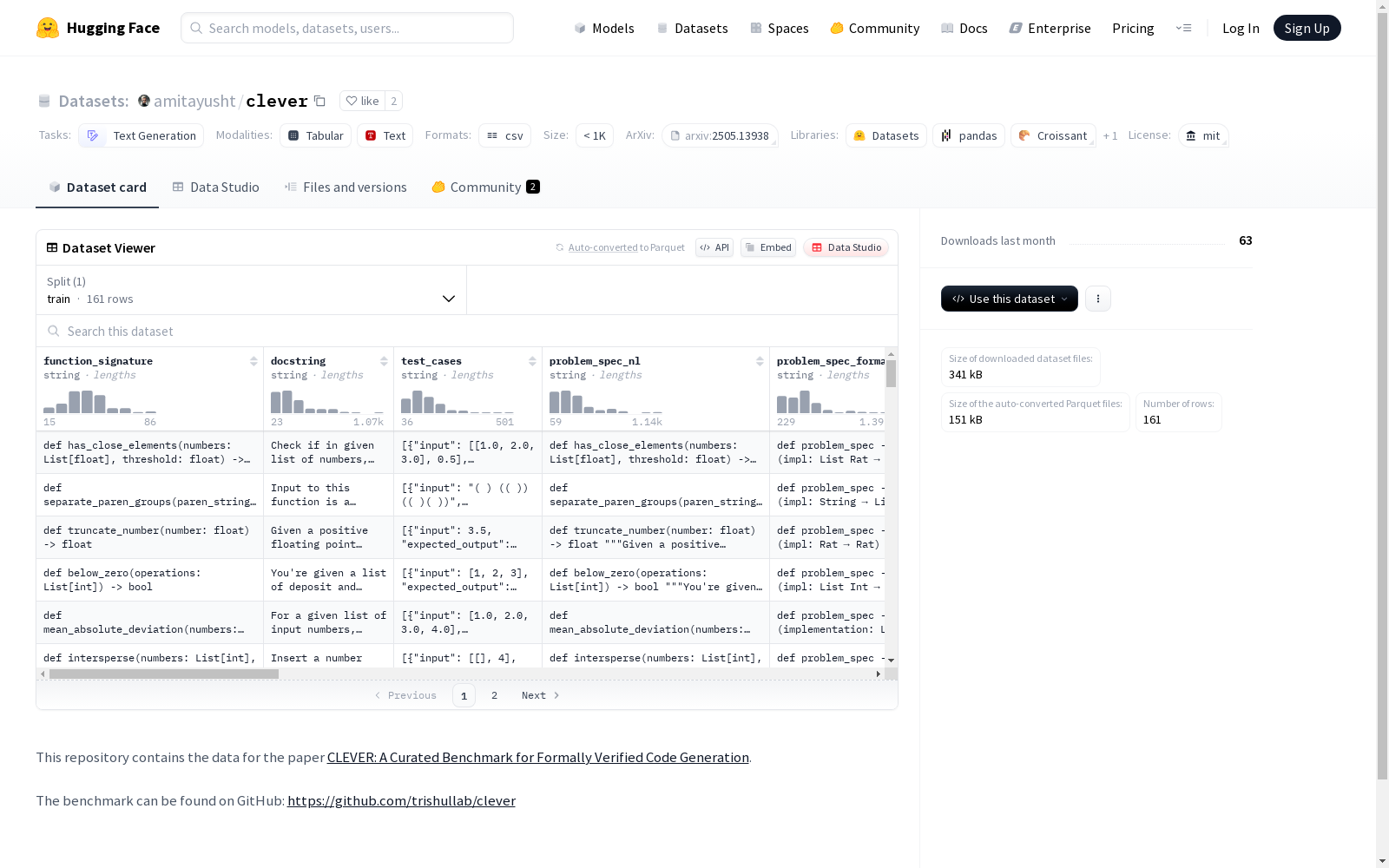
CLEVER是一个高质量的精选基准,包含161个编程任务,用于在Lean中生成端到端验证代码。每个问题都包括生成与保留的真实规范匹配的规范的任务,以及生成证明满足此规范的Lean实现的任务。与以前的基准不同,CLEVER避免了测试用例监督、LLM生成的注释以及可能泄露实现逻辑或允许空解决方案的规范。所有输出都使用Lean的类型检查器进行后验验证,以确保机器可检查的正确性。CLEVER用于评估基于最先进语言模型的几个少样本和代理方法。这些方法都难以实现完全验证,从而确立了它在程序合成和形式推理方面的挑战性前沿基准。我们的基准可以在GitHub和HuggingFace上找到。所有我们的评估代码也在线可用。
CLEVER is a high-quality curated benchmark comprising 161 programming tasks for generating end-to-end verified code in the Lean theorem prover. Each problem includes two core tasks: generating a specification that matches the preserved ground-truth specification, and generating a Lean implementation that is formally proven to satisfy this specification. Unlike prior benchmarks, CLEVER avoids test case supervision, LLM-generated annotations, and specifications that could leak implementation logic or allow for trivial or vacuous solutions. All outputs are verified post-hoc using Lean's type checker to ensure machine-checkable correctness. CLEVER is employed to evaluate several few-shot and AI Agent methods based on state-of-the-art language models. All of these methods struggle to achieve full verification, establishing CLEVER as a challenging cutting-edge benchmark for program synthesis and formal reasoning. Our benchmark is available on both GitHub and HuggingFace, and all of our evaluation code is also publicly accessible online.
提供机构:
德克萨斯大学奥斯汀分校, 加州理工学院
创建时间:
2025-05-20
搜集汇总
数据集介绍
构建方式
CLEVER数据集的构建基于HUMANEVAL基准,通过精心筛选和调整161个编程问题,以适应Lean 4的形式化验证环境。每个问题包含自然语言描述、人工编写的正式规范、Lean函数签名以及用于规范等价性和实现正确性的定理。所有规范均以不可计算的逻辑命题形式编写,确保模型无法从规范语法中复制实现逻辑。构建过程中,每个问题的规范平均耗时25分钟,并经过15分钟的同行评审,部分复杂问题甚至需要超过1小时。
特点
CLEVER数据集的特点在于其严格的验证流程和非计算性规范设计。数据集通过两阶段评估(规范认证和实现认证)确保生成的代码不仅在语法上正确,而且在语义上符合规范。非计算性规范的使用防止了模型通过简单的模式匹配或复制规范逻辑来“作弊”,从而强制模型进行深层次的逻辑推理。此外,数据集还提供了少量手工编写的示例问题,用于支持少样本学习和上下文学习。
使用方法
使用CLEVER数据集时,模型首先根据自然语言描述生成正式的Lean规范,并证明其与隐藏的真实规范语义等价。随后,模型需生成符合规范的Lean实现,并证明其正确性。评估采用严格的验证标准,仅当所有阶段的证明均通过Lean的类型检查器验证时,才视为成功。数据集支持细粒度的诊断,可独立分析模型在规范生成、等价性证明、实现生成和正确性证明各阶段的失败情况。
背景与挑战
背景概述
CLEVER(Curated Lean Verified Code Generation Benchmark)是由德克萨斯大学奥斯汀分校、加州理工学院和亚马逊的研究团队于2025年提出的高质量基准测试集,专注于端到端形式化验证的代码生成。该数据集包含161个编程问题,旨在评估模型在生成符合形式化规范的Lean代码方面的能力。CLEVER的创建背景源于交互式定理证明(ITP)技术在软件开发中的高成本问题,如seL4微内核的验证耗费了超过20人年的工作量。该数据集通过严格的两阶段验证流程(规范认证与实现认证),避免了测试用例监督和规范泄露实现逻辑等缺陷,为程序合成和形式推理领域设立了新的挑战标准。
当前挑战
CLEVER面临的挑战主要体现在两个方面:领域问题层面,现有语言模型在生成可通过Lean类型检查器验证的完整规范与代码方面表现不佳(最高仅能解决1/161问题),凸显了形式推理与程序合成的技术瓶颈;构建过程层面,非可计算规范的编写需人工确保语义完整性且避免实现泄露(平均每个问题耗时25分钟),多项式求根等问题还涉及未解决的数学难题(如终止性证明),而Lean 4语言限制导致原HUMANEVAL数据集中3个问题无法形式化。此外,规范与实现证明的分离诊断机制要求模型同时具备深层逻辑推理和符号操作能力,这对现有神经符号方法提出了更高要求。
常用场景
经典使用场景
CLEVER数据集专为端到端形式化验证代码生成任务设计,其核心应用场景在于评估大语言模型在Lean定理证明器环境下生成符合形式化规范的代码能力。数据集通过161个编程问题构建了双阶段验证框架:首先生成与自然语言描述语义等价的Lean规范,随后生成可验证满足该规范的实现代码。这种设计特别适用于研究程序综合与形式化推理的交叉领域,例如验证编译器优化、安全关键系统开发等高可靠性需求场景。
衍生相关工作
CLEVER催生了多个重要研究方向:COPRA神经符号证明搜索代理通过结合LLM与策略引擎提升验证成功率;AlphaVerus基于该基准开发了自改进的Verus代码生成框架;FVAPPS等后续工作借鉴其非可计算规范设计理念改进自动标注质量。数据集还启发了LeanDojo定理证明环境、PutnamBench数学竞赛验证基准等衍生项目,推动形成神经形式化方法研究生态。
数据集最近研究
最新研究方向
近年来,CLEVER数据集在形式化验证代码生成领域引起了广泛关注。该数据集通过精心设计的161个编程任务,为验证代码生成模型的能力提供了严格的评估标准。研究热点主要集中在如何利用先进的少样本学习和代理方法,基于最先进的语言模型,生成符合形式化规范的代码。CLEVER的独特之处在于其避免了测试用例监督和LLM生成的注释,确保了规范与实现逻辑的严格分离。这一特性使其成为程序合成和形式推理领域的前沿基准,为提升AI在形式化验证中的应用提供了重要参考。
相关研究论文
- 1CLEVER: A Curated Benchmark for Formally Verified Code Generation德克萨斯大学奥斯汀分校, 加州理工学院 · 2025年
以上内容由遇见数据集搜集并总结生成


