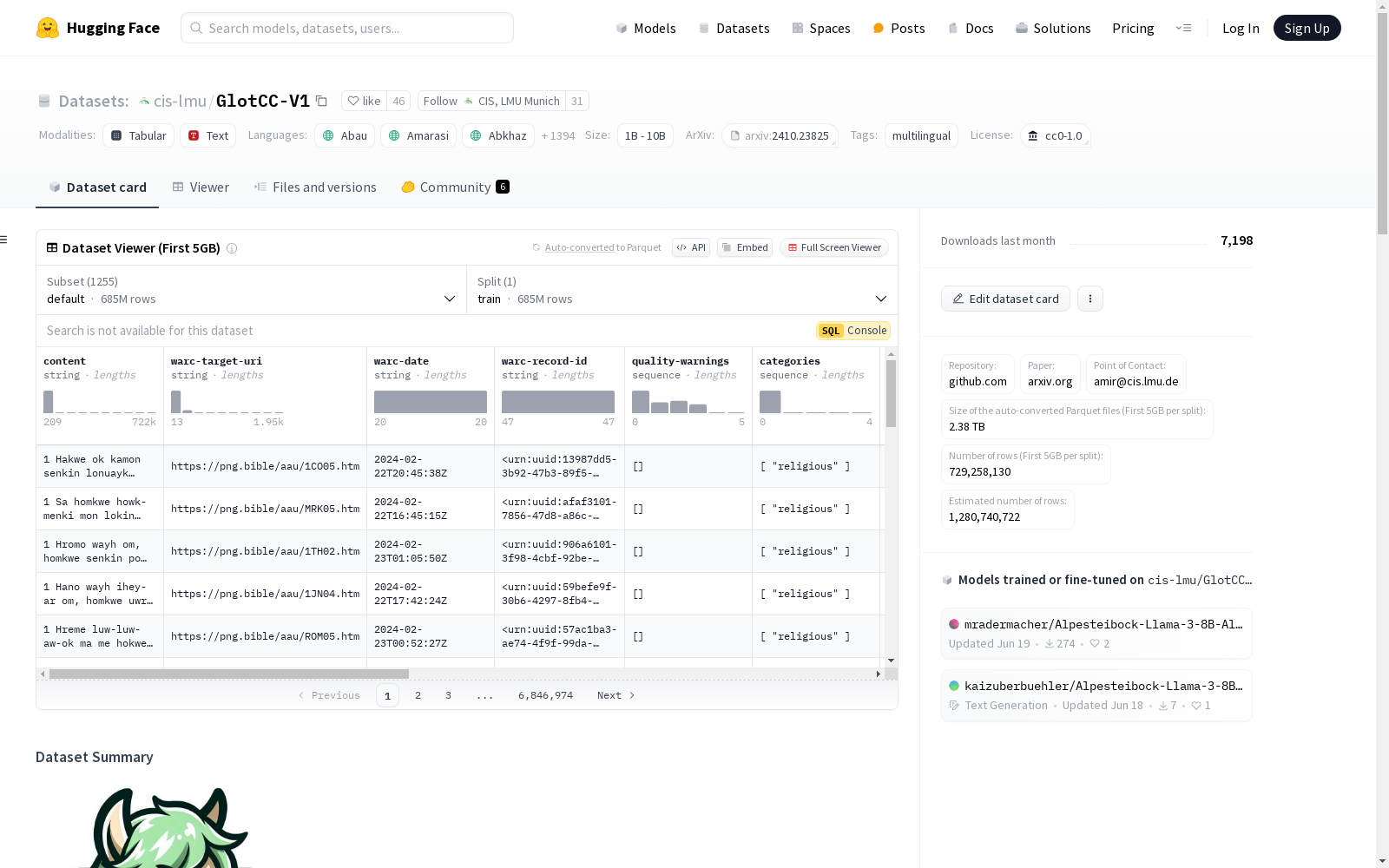
GlotCC
收藏GlotCC-v1 数据集概述
基本信息
- 数据集名称: GlotCC-v1
- 许可证: CC0-1.0
配置信息
数据集包含多个配置,每个配置对应不同的语言和脚本。以下是各配置的详细信息:
默认配置
- 配置名称: default
- 数据文件路径:
v1.0/*/*.parquet - 数据分割: train
语言配置
以下是各语言配置的详细信息:
-
英语 (Latin 脚本)
- 配置名称: eng-Latn
- 数据文件路径:
v1.0/eng-Latn/*.parquet - 数据分割: train
-
俄语 (Cyrillic 脚本)
- 配置名称: rus-Cyrl
- 数据文件路径:
v1.0/rus-Cyrl/*.parquet - 数据分割: train
-
法语 (Latin 脚本)
- 配置名称: fra-Latn
- 数据文件路径:
v1.0/fra-Latn/*.parquet - 数据分割: train
-
西班牙语 (Latin 脚本)
- 配置名称: spa-Latn
- 数据文件路径:
v1.0/spa-Latn/*.parquet - 数据分割: train
-
德语 (Latin 脚本)
- 配置名称: deu-Latn
- 数据文件路径:
v1.0/deu-Latn/*.parquet - 数据分割: train
-
波兰语 (Latin 脚本)
- 配置名称: pol-Latn
- 数据文件路径:
v1.0/pol-Latn/*.parquet - 数据分割: train
-
越南语 (Latin 脚本)
- 配置名称: vie-Latn
- 数据文件路径:
v1.0/vie-Latn/*.parquet - 数据分割: train
-
意大利语 (Latin 脚本)
- 配置名称: ita-Latn
- 数据文件路径:
v1.0/ita-Latn/*.parquet - 数据分割: train
-
荷兰语 (Latin 脚本)
- 配置名称: nld-Latn
- 数据文件路径:
v1.0/nld-Latn/*.parquet - 数据分割: train
-
葡萄牙语 (Latin 脚本)
- 配置名称: por-Latn
- 数据文件路径:
v1.0/por-Latn/*.parquet - 数据分割: train
-
捷克语 (Latin 脚本)
- 配置名称: ces-Latn
- 数据文件路径:
v1.0/ces-Latn/*.parquet - 数据分割: train
-
波斯语 (Arabic 脚本)
- 配置名称: fas-Arab
- 数据文件路径:
v1.0/fas-Arab/*.parquet - 数据分割: train
-
土耳其语 (Latin 脚本)
- 配置名称: tur-Latn
- 数据文件路径:
v1.0/tur-Latn/*.parquet - 数据分割: train
-
泰语 (Thai 脚本)
- 配置名称: tha-Thai
- 数据文件路径:
v1.0/tha-Thai/*.parquet - 数据分割: train
-
印尼语 (Latin 脚本)
- 配置名称: ind-Latn
- 数据文件路径:
v1.0/ind-Latn/*.parquet - 数据分割: train
-
中文 (Han 脚本)
- 配置名称: cmn-Hani
- 数据文件路径:
v1.0/cmn-Hani/*.parquet - 数据分割: train
-
匈牙利语 (Latin 脚本)
- 配置名称: hun-Latn
- 数据文件路径:
v1.0/hun-Latn/*.parquet - 数据分割: train
-
希腊语 (Greek 脚本)
- 配置名称: ell-Grek
- 数据文件路径:
v1.0/ell-Grek/*.parquet - 数据分割: train
-
瑞典语 (Latin 脚本)
- 配置名称: swe-Latn
- 数据文件路径:
v1.0/swe-Latn/*.parquet - 数据分割: train
-
罗马尼亚语 (Latin 脚本)
- 配置名称: ron-Latn
- 数据文件路径:
v1.0/ron-Latn/*.parquet - 数据分割: train
-
韩语 (Hangul 脚本)
- 配置名称: kor-Hang
- 数据文件路径:
v1.0/kor-Hang/*.parquet - 数据分割: train
-
乌克兰语 (Cyrillic 脚本)
- 配置名称: ukr-Cyrl
- 数据文件路径:
v1.0/ukr-Cyrl/*.parquet - 数据分割: train
-
阿拉伯语 (Arabic 脚本)
- 配置名称: arb-Arab
- 数据文件路径:
v1.0/arb-Arab/*.parquet - 数据分割: train
-
芬兰语 (Latin 脚本)
- 配置名称: fin-Latn
- 数据文件路径:
v1.0/fin-Latn/*.parquet - 数据分割: train
-
斯洛伐克语 (Latin 脚本)
- 配置名称: slk-Latn
- 数据文件路径:
v1.0/slk-Latn/*.parquet - 数据分割: train
-
保加利亚语 (Cyrillic 脚本)
- 配置名称: bul-Cyrl
- 数据文件路径:
v1.0/bul-Cyrl/*.parquet - 数据分割: train
-
丹麦语 (Latin 脚本)
- 配置名称: dan-Latn
- 数据文件路径:
v1.0/dan-Latn/*.parquet - 数据分割: train
-
希伯来语 (Hebrew 脚本)
- 配置名称: heb-Hebr
- 数据文件路径:
v1.0/heb-Hebr/*.parquet - 数据分割: train
-
挪威语 (Bokmål, Latin 脚本)
- 配置名称: nob-Latn
- 数据文件路径:
v1.0/nob-Latn/*.parquet - 数据分割: train
-
加泰罗尼亚语 (Latin 脚本)
- 配置名称: cat-Latn
- 数据文件路径:
v1.0/cat-Latn/*.parquet - 数据分割: train
-
立陶宛语 (Latin 脚本)
- 配置名称: lit-Latn
- 数据文件路径:
v1.0/lit-Latn/*.parquet - 数据分割: train
-
孟加拉语 (Bengali 脚本)
- 配置名称: ben-Beng
- 数据文件路径:
v1.0/ben-Beng/*.parquet - 数据分割: train
-
斯洛文尼亚语 (Latin 脚本)
- 配置名称: slv-Latn
- 数据文件路径:
v1.0/slv-Latn/*.parquet - 数据分割: train
-
阿塞拜疆语 (Latin 脚本)
- 配置名称: azj-Latn
- 数据文件路径:
v1.0/azj-Latn/*.parquet - 数据分割: train
-
爱沙尼亚语 (Latin 脚本)
- 配置名称: ekk-Latn
- 数据文件路径:
v1.0/ekk-Latn/*.parquet - 数据分割: train
-
拉脱维亚语 (Latin 脚本)
- 配置名称: lvs-Latn
- 数据文件路径:
v1.0/lvs-Latn/*.parquet - 数据分割: train
-
克罗地亚语 (Latin 脚本)
- 配置名称: hrv-Latn
- 数据文件路径:
v1.0/hrv-Latn/*.parquet - 数据分割: train
-
日语 (Japanese 脚本)
- 配置名称: jpn-Jpan
- 数据文件路径:
v1.0/jpn-Jpan/*.parquet - 数据分割: train
-
泰米尔语 (Tamil 脚本)
- 配置名称: tam-Taml
- 数据文件路径:
v1.0/tam-Taml/*.parquet - 数据分割: train
-
塞尔维亚语 (Cyrillic 脚本)
- 配置名称: srp-Cyrl
- 数据文件路径:
v1.0/srp-Cyrl/*.parquet - 数据分割: train
-
尼泊尔语 (Devanagari 脚本)
- 配置名称: npi-Deva
- 数据文件路径:
v1.0/npi-Deva/*.parquet - 数据分割: train
-
格鲁吉亚语 (Georgian 脚本)
- 配置名称: kat-Geor
- 数据文件路径:
v1.0/kat-Geor/*.parquet - 数据分割: train
-
印地语 (Devanagari 脚本)
- 配置名称: hin-Deva
- 数据文件路径:
v1.0/hin-Deva/*.parquet - 数据分割: train
-
亚美尼亚语 (Armenian 脚本)
- 配置名称: hye-Armn
- 数据文件路径:
v1.0/hye-Armn/*.parquet - 数据分割: train
-
马来语 (Latin 脚本)
- 配置名称: zsm-Latn
- 数据文件路径:
v1.0/zsm-Latn/*.parquet - 数据分割: train
-
阿尔巴尼亚语 (Latin 脚本)
- 配置名称: als-Latn
- 数据文件路径:
v1.0/als-Latn/*.parquet - 数据分割: train
-
马其顿语 (Cyrillic 脚本)
- 配置名称: mkd-Cyrl
- 数据文件路径:
v1.0/mkd-Cyrl/*.parquet - 数据分割: train
-
马拉雅拉姆语 (Malayalam 脚本)
- 配置名称: mal-Mlym
- 数据文件路径:
v1.0/mal-Mlym/*.parquet - 数据分割: train
-
库尔德语 (Latin 脚本)
- 配置名称: kiu-Latn
- 数据文件路径:
v1.0/kiu-Latn/*.parquet - 数据分割: train
-
乌尔都语 (Arabic 脚本)
- 配置名称: urd-Arab
- 数据文件路径:
v1.0/urd-Arab/*.parquet - 数据分割: train
-
缅甸语 (Myanmar 脚本)
- 配置名称: mya-Mymr
- 数据文件路径:
v1.0/mya-Mymr/*.parquet - 数据分割: train
-
加利西亚语 (Latin 脚本)
- 配置名称: glg-Latn
- 数据文件路径:
v1.0/glg-Latn/*.parquet - 数据分割: train
-
冰岛语 (Latin 脚本)
- 配置名称: isl-Latn
- 数据文件路径:
v1.0/isl-Latn/*.parquet - 数据分割: train
-
马拉地语 (Devanagari 脚本)
- 配置名称: mar-Deva
- 数据文件路径:
v1.0/mar-Deva/*.parquet - 数据分割: train
-
巴斯克语 (Latin 脚本)
- 配置名称: eus-Latn
- 数据文件路径:
v1.0/eus-Latn/*.parquet - 数据分割: train
-
哈萨克语 (Cyrillic 脚本)
- 配置名称: kaz-Cyrl
- 数据文件路径:
v1.0/kaz-Cyrl/*.parquet - 数据分割: train
-
泰卢固语 (Telugu 脚本)
- 配置名称: tel-Telu
- 数据文件路径:
v1.0/tel-Telu/*.parquet - 数据分割: train
-
拉丁语 (Latin 脚本)
- 配置名称: lat-Latn
- 数据文件路径:
v1.0/lat-Latn/*.parquet - 数据分割: train
-
哈萨克语 (Cyrillic 脚本)
- 配置名称: khk-Cyrl
- 数据文件路径:
v1.0/khk-Cyrl/*.parquet - 数据分割: train
-
高棉语 (Khmer 脚本)
- 配置名称: khm-Khmr
- 数据文件路径:
v1.0/khm-Khmr/*.parquet - 数据分割: train
-
白俄罗斯语 (Cyrillic 脚本)
- 配置名称: bel-Cyrl
- 数据文件路径:
v1.0/bel-Cyrl/*.parquet - 数据分割: train
-
卡纳达语 (Kannada 脚本)
- 配置名称: kan-Knda
- 数据文件路径:
v1.0/kan-Knda/*.parquet - 数据分割: train
-
波斯尼亚语 (Latin 脚本)
- 配置名称: bos-Latn
- 数据文件路径:
v1.0/bos-Latn/*.parquet - 数据分割: train
-
古吉拉特语 (Gujarati 脚本)
- 配置名称: guj-Gujr
- 数据文件路径:
v1.0/guj-Gujr/*.parquet - 数据分割: train
-
僧伽罗语 (Sinhala 脚本)
- 配置名称: sin-Sinh
- 数据文件路径:
v1.0/sin-Sinh/*.parquet - 数据分割: train
-
乌兹别克语 (Latin 脚本)
- 配置名称: uzn-Latn
- 数据文件路径:
v1.0/uzn-Latn/*.parquet - 数据分割: train
-
乌兹别克语 (Cyrillic 脚本)
- 配置名称: uzn-Cyrl
- 数据文件路径:
v1.0/uzn-Cyrl/*.parquet - 数据分割: train
-
菲律宾语 (Latin 脚本)
- 配置名称: fil-Latn
- 数据文件路径:
v1.0/fil-Latn/*.parquet - 数据分割: train
-
旁遮普语 (Gurmukhi 脚本)
- 配置名称: pan-Guru
- 数据文件路径:
v1.0/pan-Guru/*.parquet - 数据分割: train
-
挪威语 (Nynorsk, Latin 脚本)
- 配置名称: nno-Latn
- **数据文件路径