韩国句子结尾数据集(KoSEnd)
收藏arXiv2025-07-04 更新2025-07-09 收录
下载链接:
https://github.com/seungukyu/KoSEnd
下载链接
链接失效反馈官方服务:
资源简介:
韩国句子结尾数据集(KoSEnd)是一个包含3000个句子的数据集,每个句子都标注了15种句子结尾形式。这些句子从不同的来源收集而来,涵盖了各种语境。该数据集旨在评估大型语言模型(LLMs)对韩语句子的理解能力,特别是对复杂句子结尾的理解。数据集的构建过程包括语料库收集、句子结尾扩展和两阶段标注。研究结果表明,LLMs在处理韩语句子结尾时存在一定的挑战,但通过引入句子结尾可能缺失的概念,模型的性能得到了显著提升。
The Korean Sentence End Dataset (KoSEnd) is a dataset containing 3,000 sentences, each annotated with 15 types of sentence endings. These sentences are collected from diverse sources and cover a wide range of contexts. This dataset is designed to evaluate the ability of Large Language Models (LLMs) to understand Korean sentences, particularly complex sentence endings. The construction process of this dataset includes corpus collection, sentence ending expansion, and two-stage annotation. Research findings indicate that LLMs face certain challenges when processing Korean sentence endings; however, introducing the concept of potentially missing sentence endings leads to a significant improvement in model performance.
提供机构:
中央安大学校,首尔,大韩民国
创建时间:
2025-07-04
搜集汇总
数据集介绍
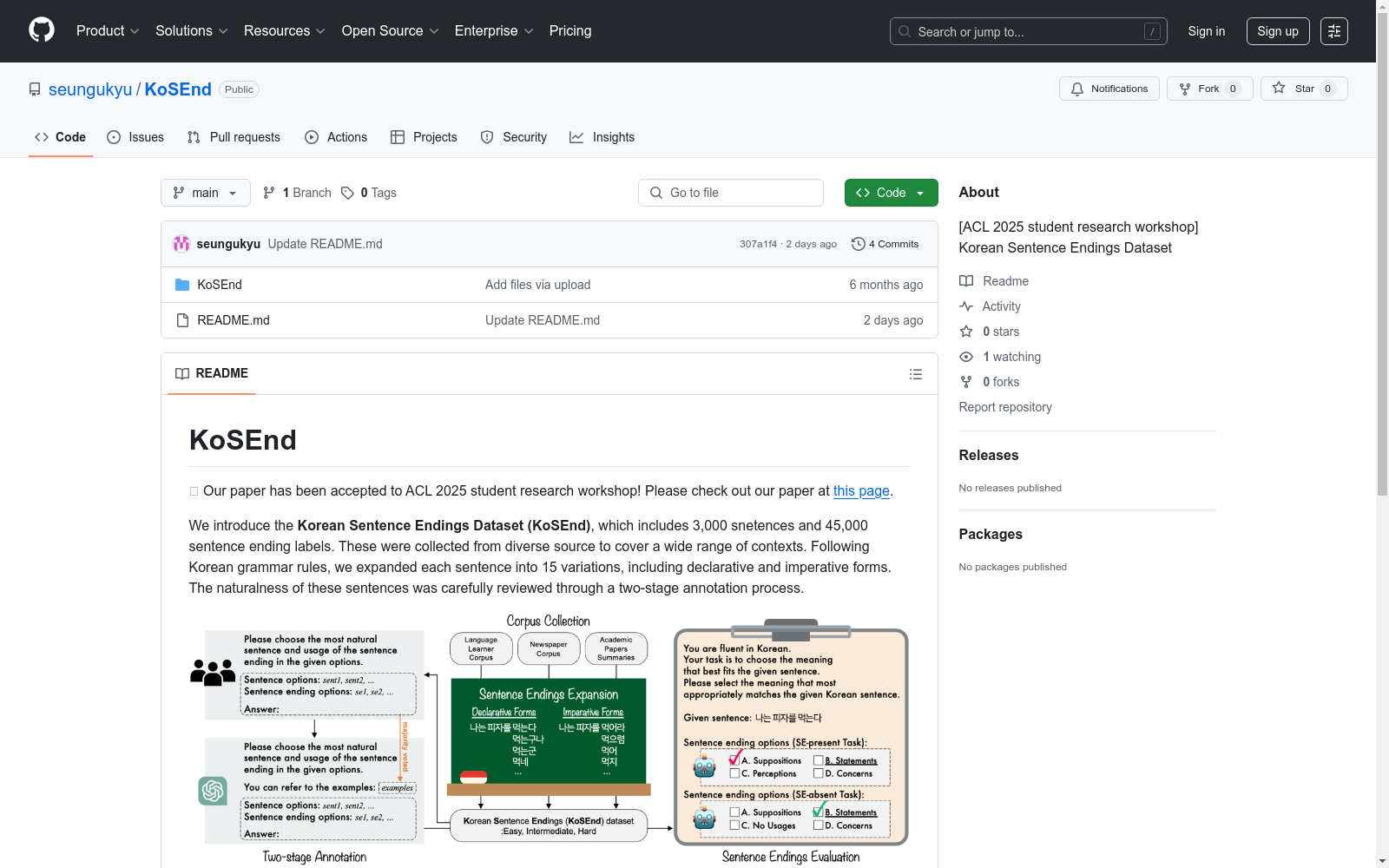
构建方式
韩国句子结尾数据集(KoSEnd)的构建过程体现了对韩语复杂句尾结构的系统性捕捉。研究团队从语言学习者语料库、新闻报纸语料库和学术论文摘要三个不同难度的来源收集了3,000个基础句子,通过语言学规则将每个句子扩展为15种可能的句尾形式(9种陈述式与6种命令式)。为确保标注质量,采用了两阶段标注策略:首先由韩语母语者对300个样本进行人工标注以建立基准,随后基于大语言模型(GPT-4-turbo)进行自动化标注,并通过循环排列(cyclic permutation)技术消除选项顺序偏差,最终形成包含45,000个标注实例的高质量数据集。
特点
该数据集的核心价值在于其语言学深度与评估维度设计。作为首个系统化涵盖韩语15种句尾形态的资源,KoSEnd不仅包含基础陈述与命令式变体,更通过三层次难度划分(初级、中级、高级)反映不同语境复杂度。其独特之处在于标注了句尾使用的自然性而非简单正确性,允许存在多个合理选项或无合适句尾的情况,从而精准捕捉韩语中依赖语境的微妙表达差异。数据统计显示,命令式句尾的标注不一致率(最高52.48%)显著高于陈述式,印证了韩语敬语体系和语用规则带来的特殊挑战。
使用方法
KoSEnd数据集支持两种标准化评估任务:SE-always(假设句尾必然存在)和SE-absent(允许句尾缺失)。使用时需将测试句子与所有可能的句尾变体组合,要求模型选择最自然的选项。研究证实,明确提示句尾可能缺失(SE-absent)能使模型准确率平均提升4.76-7.33%,这一发现为韩语语言模型优化提供了重要方向。评估过程推荐采用循环排列法消除选项顺序干扰,并通过贪心解码(temperature=0)确保结果稳定性。该数据集特别适用于分析模型对韩语形态学特性的理解能力,包括参数规模效应(如70B模型仅比7B模型提升19-35%)和语言微调价值(韩语指令微调模型表现最佳)。
背景与挑战
背景概述
韩国句子结尾数据集(KoSEnd)由韩国中央大学的研究团队于2025年创建,旨在评估大型语言模型(LLMs)对韩语复杂句子结尾的理解能力。韩语作为一种黏着语,其句子结尾形式多样且语义微妙,细微的变化可能导致整体含义的显著差异。该数据集包含3000个句子,每个句子标注了15种句子结尾形式的自然性,覆盖了从语言学习者语料到学术论文摘要的多层次语境。KoSEnd的推出填补了低资源黏着语在自然语言处理评估中的空白,为韩语语言学研究和模型优化提供了重要基准。
当前挑战
KoSEnd数据集面临的核心挑战体现在两个方面:领域问题层面,韩语句子结尾的复杂形态和语境依赖性使得模型难以准确捕捉其语义和语用差异,尤其在命令式结尾中表现更为显著;构建过程中,数据标注面临天然语言主观性带来的高分歧率,不同难度层级的标注一致性差异显著(如学术语料的Krippendorff's α值降至0.3),迫使研究团队采用基于LLM的两阶段标注方案。此外,模型评估显示参数规模与性能提升不成正比,70B参数模型的命令式结尾理解准确率仍不足50%,且选项顺序敏感性暴露出模型鲁棒性缺陷。
常用场景
经典使用场景
韩国句子结尾数据集(KoSEnd)在自然语言处理领域中被广泛用于评估大型语言模型(LLMs)对韩语句子结尾的理解能力。韩语作为一种黏着语,其复杂的句子结尾形式对语言模型提出了独特的挑战。KoSEnd数据集通过提供多样化的句子结尾形式及其上下文标注,为研究者提供了一个标准化的评估平台。该数据集尤其适用于测试模型在韩语语法结构中的表现,特别是在处理不同语境下的句子结尾变化时。
实际应用
在实际应用中,KoSEnd数据集被用于优化韩语机器翻译、文本生成和对话系统。例如,在机器翻译中,模型需要准确理解句子结尾的语义和情感差异,以避免翻译中的歧义。此外,该数据集还可用于教育技术领域,帮助开发韩语学习工具,提升学习者对复杂句子结构的掌握能力。
衍生相关工作
KoSEnd数据集衍生了一系列相关研究,特别是在韩语自然语言处理领域。基于该数据集,研究者开发了多个针对韩语语法结构的评估基准,如KorNLI和KorSTS。此外,该数据集还启发了对多语言模型中语言偏差的研究,推动了跨语言模型在低资源语言中的性能优化。
以上内容由遇见数据集搜集并总结生成


