Discord-Unveiled-Filtered
收藏Hugging Face2025-08-25 更新2025-08-26 收录
下载链接:
https://huggingface.co/datasets/ManBib/Discord-Unveiled-Filtered
下载链接
链接失效反馈官方服务:
资源简介:
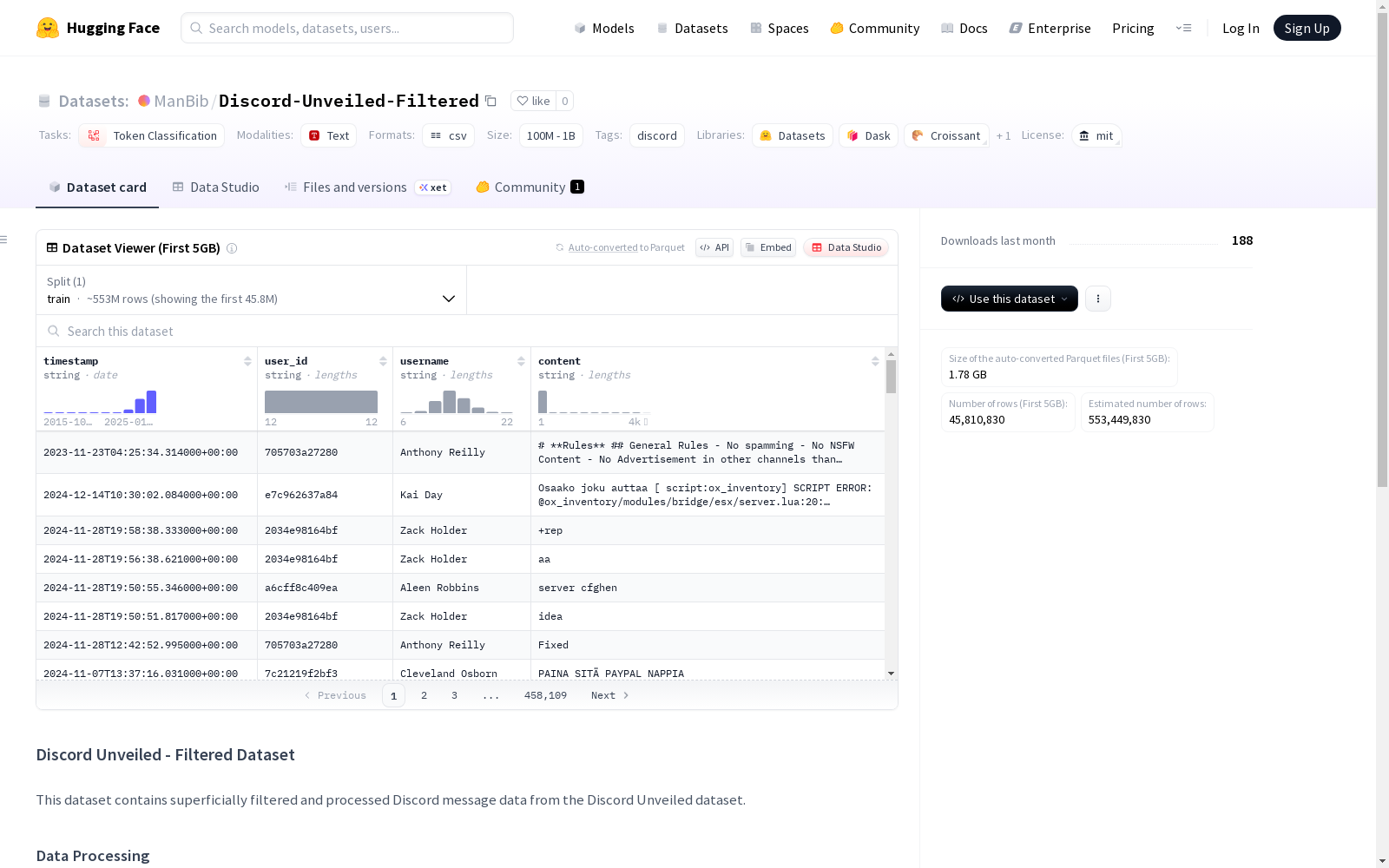
这个数据集包含了来自Discord Unveiled数据集的表面过滤和处理后的Discord消息数据。数据已经过处理,包括将JSON数据转换为CSV格式,移除机器人的消息,过滤掉只包含URLs、提及、频道或Discord表情的消息,以及使用FastText语言识别模型过滤掉非英语消息。CSV文件包含时间戳、用户ID、用户名和清洁过滤后的消息内容字段。需要注意的是,过滤过程并不完美,数据集中可能仍包含一些不相关或非英语的消息。
创建时间:
2025-08-25
原始信息汇总
Discord Unveiled - Filtered Dataset 概述
数据集基本信息
- 许可证: MIT
- 任务类别: 词元分类
- 标签: Discord
- 数据集名称: Discord Unveiled - Filtered Dataset
数据内容
该数据集包含经过初步过滤和处理的Discord消息数据,源自Discord Unveiled数据集。
数据处理方法
数据经过以下处理步骤:
- 将JSON数据转换为CSV格式
- 移除来自机器人的消息
- 过滤掉仅包含URL、提及、频道或Discord表情的消息
- 使用FastText语言识别模型过滤非英语消息
数据字段说明
CSV文件包含以下字段:
timestamp: 消息发送时间戳user_id: 发送用户的IDusername: 发送用户的用户名content: 经过清理和过滤的消息内容
局限性说明
- 过滤过程并非完美,可能存在部分不相关或非英语消息
搜集汇总
数据集介绍
构建方式
在社交媒体数据挖掘领域,Discord-Unveiled-Filtered数据集通过系统化流程构建而成。原始Discord消息数据首先从JSON格式转换为CSV结构,随后采用多重过滤策略:自动剔除机器人发送的消息,移除仅包含URL、提及、频道标识或Discord表情符号的无效内容,并借助FastText语言识别模型筛选出纯英文消息,确保语言一致性。
特点
该数据集的核心特征体现在其精细化的字段设计与质量控制。每条记录包含时间戳、用户ID、用户名及经过清理的文本内容,形成了时空维度与用户行为的多维关联。虽然过滤机制可能存在极小概率的误差残留,但整体数据具备高纯净度,为对话分析、用户行为建模等研究提供了结构化基础。
使用方法
研究者可基于该数据集开展自然语言处理与社交计算实验。直接加载CSV文件后,可利用时间戳字段进行时序分析,结合用户ID追踪个体行为模式,或通过文本内容训练词嵌入模型及情感分类器。需注意潜在的语言识别误差,建议在预处理阶段辅以人工抽样验证以提升研究可靠性。
背景与挑战
背景概述
Discord-Unveiled-Filtered数据集诞生于数字社交平台研究兴起的时代背景下,由匿名研究团队于2023年基于Discord Unveiled原始数据集构建而成。该数据集聚焦于在线社群对话的语义分析与用户行为建模,通过精细化过滤机制提取真实用户生成的英文文本,为计算社会科学和自然语言处理领域提供高质量的对话语料。其创新性在于首次系统性地处理了Discord平台的多模态噪声问题,为虚拟社群动力学研究建立了数据基准。
当前挑战
该数据集核心挑战在于解决多模态社交对话中的语义纯净度问题:原始数据包含机器人消息、纯URL/提及内容、Discord特有表情符号等多源噪声,需设计多层过滤算法确保文本质量。构建过程中面临非英语内容识别准确度挑战,FastText语言识别模型存在误判可能;同时需平衡数据清洗强度与语义完整性,避免过度过滤导致对话上下文断裂。此外,匿名化用户数据时如何保持对话连贯性亦是技术难点。
常用场景
经典使用场景
在自然语言处理领域,Discord-Unveiled-Filtered数据集常被用于社交媒体文本分析研究。该数据集经过精心过滤,剔除了机器人消息和非英语内容,保留了真实用户的对话文本,为学者提供了高质量的Discord平台语言样本。研究者可借此分析网络交流中的语言模式、情感表达及社区互动行为,进而探索虚拟社群的语言特征。
实际应用
在实际应用层面,该数据集可服务于社交媒体内容监控和社区管理。企业可利用其分析用户行为模式,优化在线社区管理策略;开发者可基于该数据训练聊天机器人,提升人机交互的自然度;研究人员还可借助其开展网络语言生态研究,为网络健康环境建设提供数据支持。
衍生相关工作
基于该数据集衍生的经典工作包括社交媒体情感分析模型、网络语言检测算法以及虚拟社区行为研究。这些研究不仅深化了对网络交流模式的理解,还推动了自然语言处理技术在社交媒体领域的应用创新,为后续的网络文本分析工作奠定了重要基础。
以上内容由遇见数据集搜集并总结生成


