French_Youtube_Comments
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://huggingface.co/datasets/GwendalTsang/French_Youtube_Comments
下载链接
链接失效反馈官方服务:
资源简介:
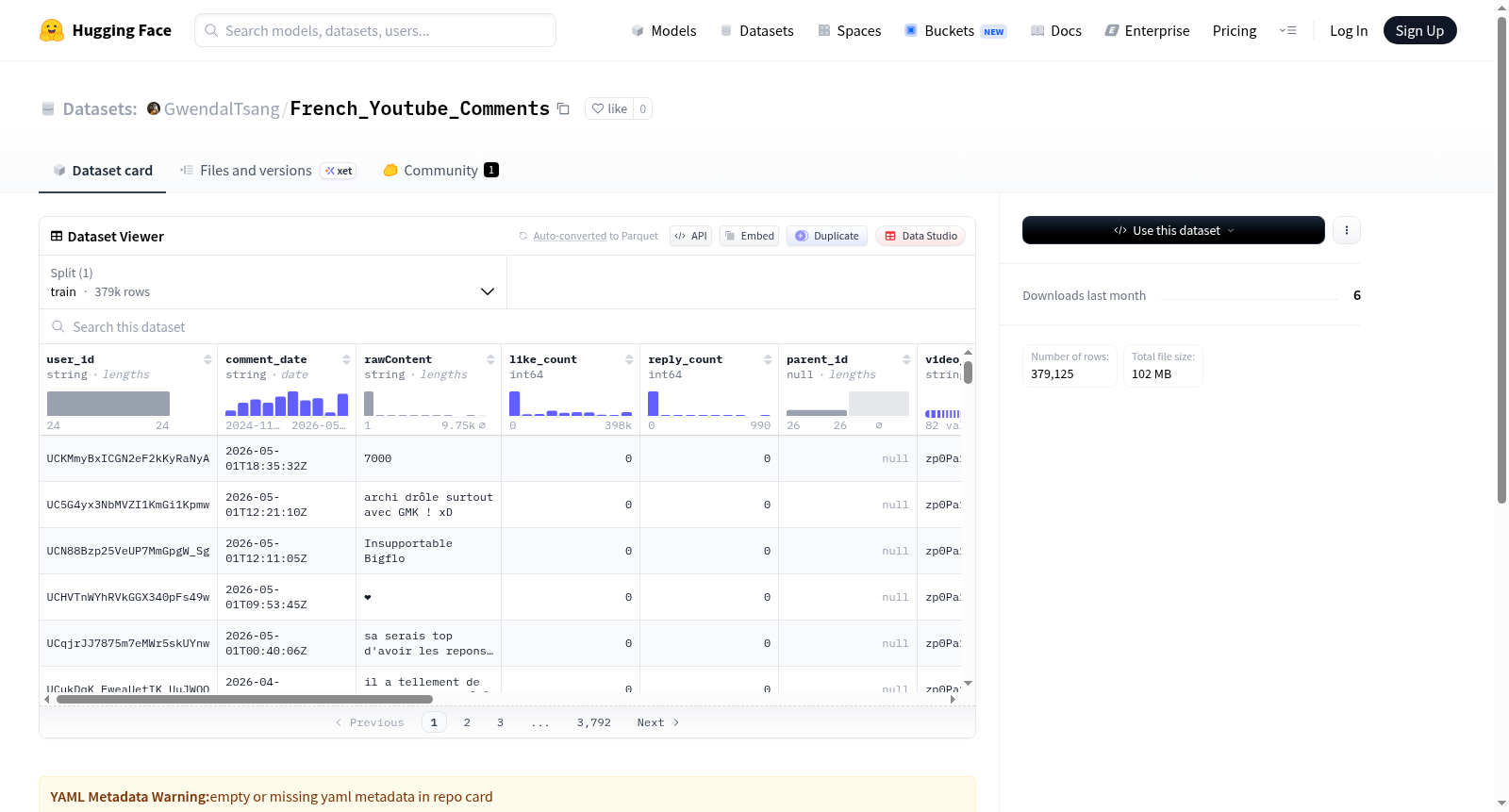
该数据集包含从面向年轻人的大众YouTube频道上抓取的评论。主要包括来自29个Squeezie视频下的187,269条评论,以及来自39个Michou视频下的191,856条评论。数据集目前处于未清理状态,保持从API获取时的原始格式。部分数据中已删除username列,但该列可通过其他方式重建。
创建时间:
2026-05-02
原始信息汇总
数据集概述
该数据集来自 Hugging Face 平台,地址为:https://huggingface.co/datasets/GwendalTsang/French_Youtube_Comments,内容为从面向年轻人的法国主流 YouTube 频道上抓取的评论数据。
主要特点
- 数据来源:来自法国知名 YouTuber Squeezie 和 Michou 的频道。
- 数据规模:
- 包含 Squeezie 的 29 个视频下的 187,269 条评论。
- 包含 Michou 的 39 个视频下的 191,856 条评论(注:Michou 数据量占比较大)。
- 数据状态:未经清洗,直接来自 YouTube API 的原始输出。
- 数据列:部分数据已删除
username列,但可以通过其他方式重建。如果需要获取username,可参考另一个数据集:https://huggingface.co/datasets/GwendalTsang/MichouComments。
注意事项
- 数据集为原始抓取状态,未进行去重、过滤或格式化处理。
- 用户名信息可能需要通过关联其他数据集来恢复。
搜集汇总
数据集介绍
构建方式
French_Youtube_Comments数据集源自对法国知名视频创作者频道的评论抓取,聚焦于面向青年群体的“大众”频道。具体而言,研究团队通过YouTube API采集了Squeezie频道下29个视频的187,269条评论,以及Michou频道下39个视频的191,856条评论,总计约37.9万条原始数据。值得注意的是,该数据集未经过清洗处理,保持了从API直接获取的原始状态,旨在为自然语言处理任务提供真实的网络语言样本。部分数据中已移除‘username’列,但该信息可通过关联其他数据集进行重建。
特点
该数据集的核心特点在于其原始性与规模性。首先,数据采集自法语YouTube领域最具影响力的青年频道,评论内容反映了当代法国青年的语言习惯、网络俚语及互动模式,具有高度的语料现实性。其次,数据集未经任何清洗或预处理,保留了包括拼写错误、表情符号、广告链接在内的完整噪声,为研究非正式网络文本的鲁棒性模型提供了宝贵资源。此外,通过Squeezie与Michou两大频道评论的对比,可支持跨创作者用户群体的语言行为差异分析。
使用方法
该数据集适用于多种法语自然语言处理任务,如情感分析、主题建模、非正式文本分类及网络用语研究。使用时需注意其原始性,建议先进行必要的文本清洗,包括移除HTML标签、统一Unicode字符及过滤冗余噪声。对于需要用户身份信息的任务,可通过Hugging Face上关联的数据集GwendalTsang/MichouComments重建‘username’列,实现用户级行为分析。加载数据集可直接通过Hugging Face的datasets库执行‘load_dataset’命令,并以标准的DataFrame格式进行处理。
背景与挑战
背景概述
在社交媒体与视频平台深度融合的当下,YouTube作为全球最大的视频分享平台,其评论区承载了海量用户交互数据,成为自然语言处理与社会计算研究的重要资源。French_Youtube_Comments数据集由研究者在近期创建,专注于爬取面向法国年轻受众的YouTube频道评论,核心研究问题聚焦于青少年群体在网络空间的语用特征与内容生态。该数据集主要采集自Squeezie与Michou两位高影响力创作者,分别包含187,269条与191,856条评论,覆盖近70个视频的评论流。由于其数据直接来自API,未经过滤或清洗,保留了原始评论环境的真实性与噪声,为研究法语社交媒体语言提供了未受干扰的观测窗口,对理解网络话语的生成机制与用户行为模式具有基础性价值。
当前挑战
该数据集所解决的领域问题集中于法语社交媒体评论的语料构建与分析,其核心挑战在于数据的高度非结构化与噪声干扰。原始评论包含拼写错误、俚语、表情符号及回复嵌套等现象,且缺乏统一的清理规范,增加了下游任务的处理难度。构建过程中,研究者面临隐私保护与数据重建的矛盾:用户名列被部分移除以规避伦理风险,但此操作又使得用户行为轨迹的完整追踪变得不可直接实现;同时,通过外部数据集重建用户ID与姓名的关联可能引入身份泄露隐患。此外,评论主题的单一性(以两位创作者为核心)限制了模型的泛化能力,而数据的时间跨度与视频主题多样性未充分说明,可能导致偏见积累。这些挑战要求研究者在数据利用时平衡噪声容忍度、隐私合规性与分析深度之间的张力。
常用场景
经典使用场景
French_Youtube_Comments数据集聚焦于法国YouTube平台上面向年轻群体的热门频道评论,尤其以Squeezie和Michou两大创作者的视频评论为核心。该数据集包含超过37万条未经清洗的原始评论,广泛用于自然语言处理领域的多模态分析、非正式语言建模及社交媒体话语研究。研究者常利用这些数据训练情感分析模型,捕捉法语网络用语中的俚语、表情符号和反讽表达,或构建青少年文化相关的主题聚类与观点挖掘系统。
解决学术问题
该数据集有效填补了法语非正式社交文本资源的匮乏,解决了学术研究中面向青少年网络语言的语料库构建难题。通过提供海量真实场景下的口语化评论,它推动了跨语言情感分析基准的完善,并助力探索YouTube平台中用户互动的行为模式与舆论形成机制。其未经清洗的特性虽增加预处理挑战,却为鲁棒性算法设计提供了天然试验场,促进了对噪声环境下文本表征能力的深入理解。
衍生相关工作
该数据集催生了多项衍生研究,包括基于多频道评论的法国YouTube创作者影响力对比分析,以及结合用户画像的评论者身份重构技术。关联数据集MichouComments进一步扩展了评论与用户名的映射关系,为隐私保护下的社交网络去匿名化研究提供了基础。后续工作还涉及评论时序演化规律挖掘,以及YouTube平台中年轻用户群体的集体情绪传播建模。
以上内容由遇见数据集搜集并总结生成


