Crab-RAG
收藏Crab RAG: Synthetic RAG Dataset
概述
该数据集是通过内部AI模型合成生成的,用于模拟各种信息检索和响应生成任务。它包括文档、实体、指令和响应,专为RAG(检索增强生成)系统设计。
数据集详情
数据集描述
Crab RAG数据集是一个合成集合,旨在促进信息检索和问答系统的发展和测试。数据集包括基于文档的查询、响应生成和实体识别任务。每个条目包含多个带有元数据的文档、用户指令和模型生成的响应,适用于RAG、问答和摘要任务。为了确保合成生成与现实之间的平衡,我们在整个数据集中使用了种子真实世界示例,以保持模型的接地性。
- 创建者: 内部AI模型
- 语言: 英语
- 许可证: MIT许可证
用途
直接使用
该数据集适用于开发和测试信息检索、问答、文本生成和摘要领域的模型。它还可用于基准测试检索增强生成系统和实体识别模型。
超出范围的使用
超出范围的使用包括在需要真实世界数据验证的实际应用中,合成数据可能无法提供准确或可靠的结果。
数据集结构
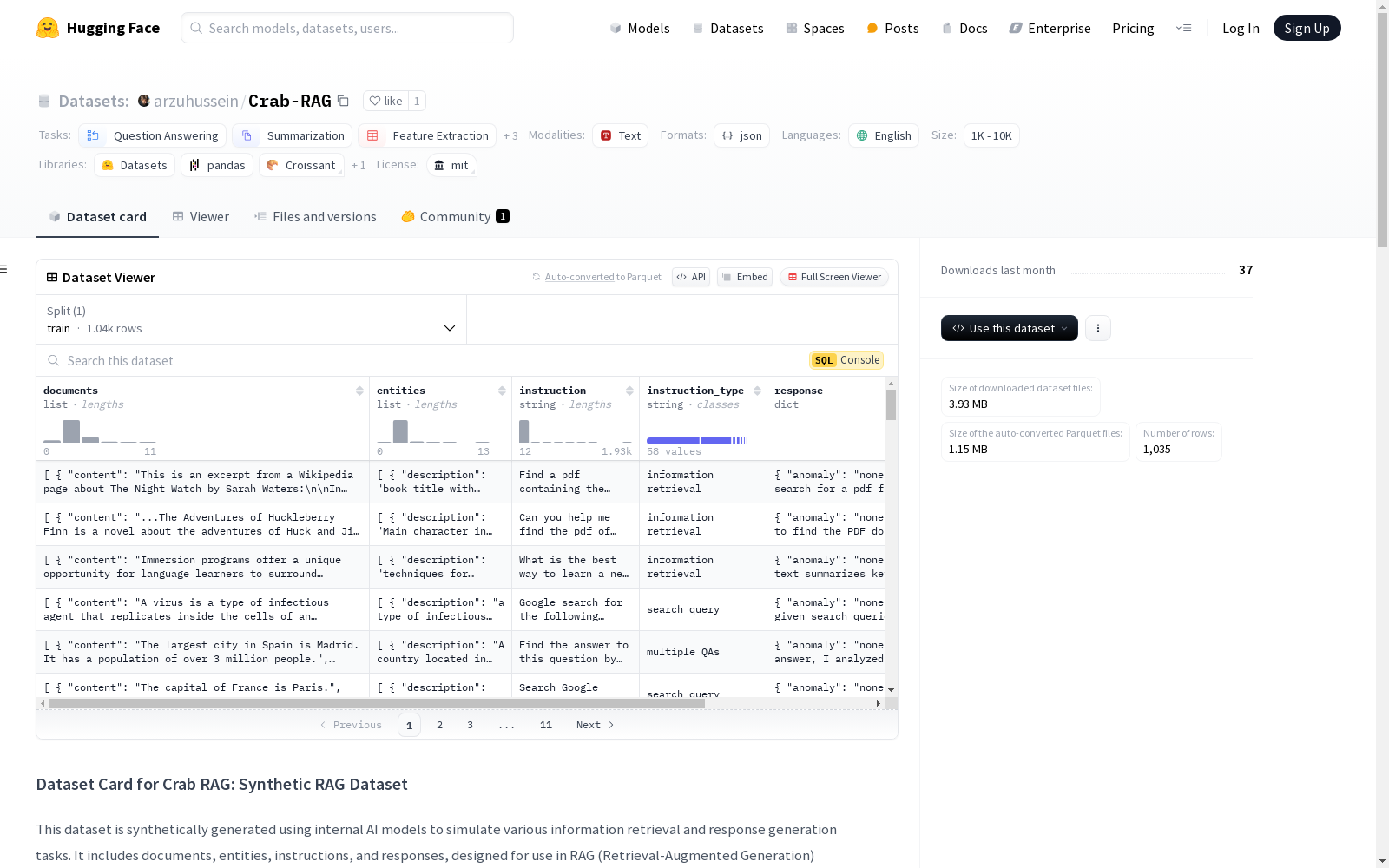
数据集包含以下关键字段:
- documents: 包含内容、元数据和唯一文档ID。
- entities: 从文档中提取的相关实体,包括描述和相关性评分。
- instruction: 用户提供的查询或模型处理的任务。
- response: 模型生成的答案、解释、满意度评分和情感分析。
数据集创建
创建动机
该数据集的创建是为了在合成环境中探索信息检索和基于文档的问答。通过生成多样化的指令和响应,它允许开发者在受控环境中测试和微调模型。
源数据
虽然大部分数据是合成的,但我们在数据集中引入了种子真实世界示例,以提高模型的真实性并保持与实际用例的更紧密对齐。
数据收集和处理
数据是通过为模型创建提示和任务来模拟真实世界场景,然后生成相应的文档、实体和响应来程序化生成的。此过程确保了指令和响应的多样性,有助于概括各种用例。
源数据生产者
数据完全由AI系统创建,没有人类交互或涉及的任何人口统计信息。真实世界示例被有选择地引入以增强数据集的真实性。
注释
数据集是合成生成的,不需要外部注释者。
个人和敏感信息
该数据集不包含任何个人、敏感或私人信息,因为所有数据都是由模型生成的。
偏差、风险和局限性
由于数据集是合成生成的,它可能无法完全反映现实世界的复杂性和偏差。响应可能缺乏现实世界数据可能表现出的细微差别和准确性。
建议
用户应意识到此合成数据集可能不代表现实世界的数据模式,在需要高精度或现实世界验证的应用中应谨慎使用。