empa-aurora-2025
收藏Hugging Face2026-05-12 更新2026-05-15 收录
下载链接:
https://huggingface.co/datasets/bsebench-org/empa-aurora-2025
下载链接
链接失效反馈官方服务:
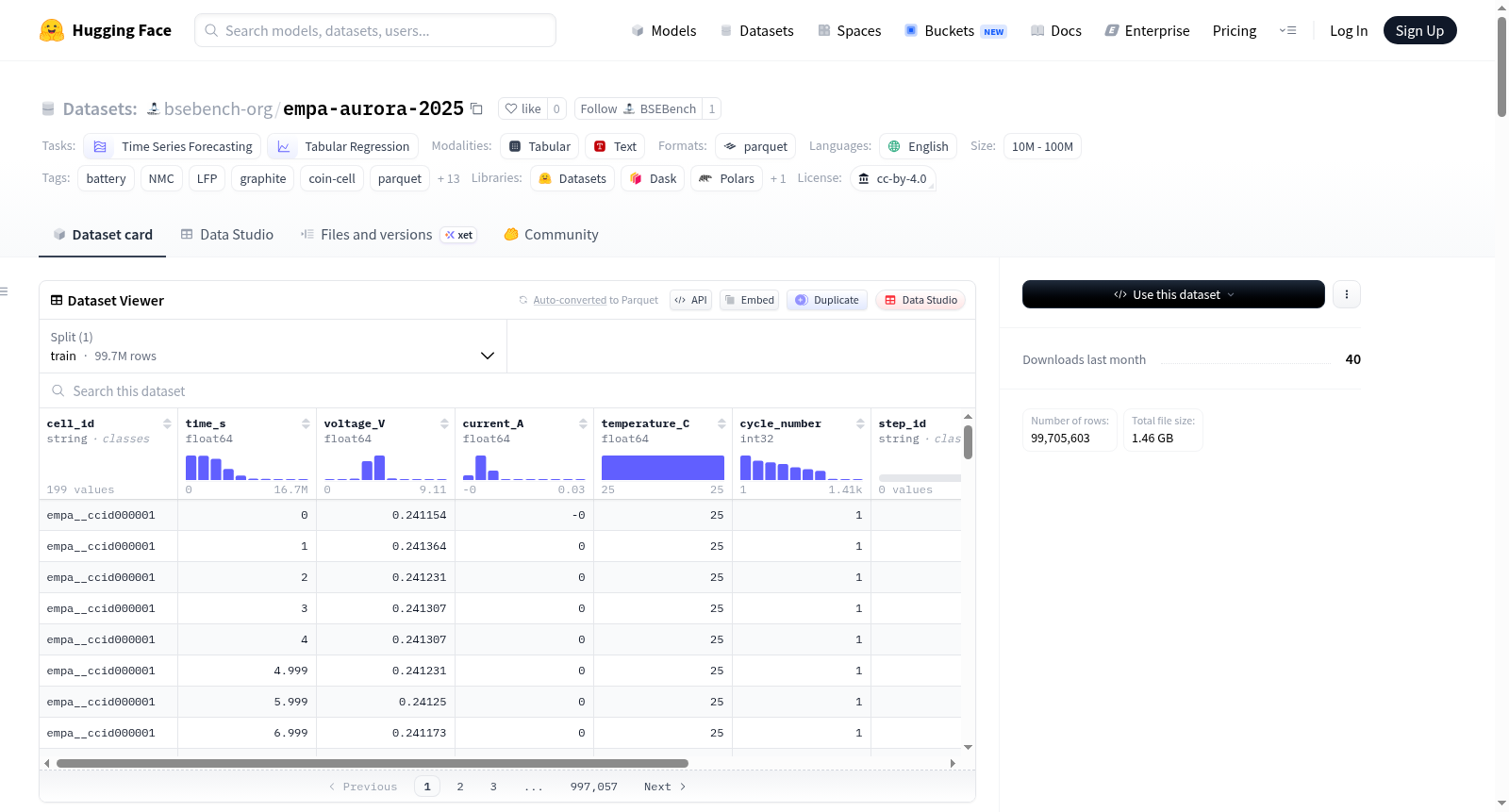
资源简介:
Empa Aurora 2025数据集是Empa、ETH Zürich、EPFL和SINTEF Aurora 2025纽扣电池循环数据集的Tier 2规范化视图,采用BSEBench-canonical Parquet模式(BPX-1.1符号约定,BattINFO对齐的列名)。该数据集包含199个电池单元的时间序列数据,原始数据已采用LF Energy Battery Data Alliance的电池数据格式(BDF)。数据集的目标是提供跨数据集统一的规范化视图,便于电池状态估计滤波器的基准测试。数据集包含10个核心列:cell_id(电池标识符)、time_s(时间,秒)、voltage_V(电压,伏特)、current_A(电流,安培,采用BPX-1.1符号约定:充电为正,放电为负)、temperature_C(温度,摄氏度)、cycle_number(循环编号)、step_id(步骤标识符)、capacity_Ah(容量,安时)、soc_truth(真实荷电状态,0-1)、soh_truth(真实健康状态,0-1)。数据集还包含每个电池的元数据侧车文件,包括化学系列、标称容量等。数据集适用于时间序列预测和表格回归任务,特别是电池状态估计(如SOC和SOH)的基准测试。数据集采用Creative Commons Attribution 4.0 International (CC-BY-4.0)许可。
The Empa Aurora 2025 dataset is a Tier 2 canonical view of the Empa, ETH Zürich, EPFL, and SINTEF Aurora 2025 coin cell cycling dataset, using the BSEBench-canonical Parquet schema (BPX-1.1 sign convention, BattINFO-aligned column names). It contains time-series data from 199 battery cells, with raw data formatted according to the LF Energy Battery Data Alliances Battery Data Format (BDF). The dataset aims to provide a unified canonical view across datasets for benchmarking battery state estimation filters. It includes 10 core columns: cell_id (cell identifier), time_s (time in seconds), voltage_V (voltage in volts), current_A (current in amperes, following BPX-1.1 sign convention: positive for charging, negative for discharging), temperature_C (temperature in degrees Celsius), cycle_number (cycle number), step_id (step identifier), capacity_Ah (capacity in ampere-hours), soc_truth (true state of charge, 0-1), soh_truth (true state of health, 0-1). The dataset also includes metadata sidecar files for each cell, covering chemical series, nominal capacity, etc. It is suitable for time-series forecasting and tabular regression tasks, particularly for benchmarking battery state estimation (e.g., SOC and SOH). The dataset is licensed under Creative Commons Attribution 4.0 International (CC-BY-4.0).
创建时间:
2026-04-29
搜集汇总
数据集介绍
构建方式
empa-aurora-2025数据集源自瑞士联邦材料科学与技术实验室(Empa)、苏黎世联邦理工学院(ETH Zürich)、洛桑联邦理工学院(EPFL)及SINTEF联合发布的Aurora 2025纽扣电池循环数据集,原始数据以LF Energy电池数据联盟制定的电池数据格式(BDF)存储。BSEBench项目进一步对该数据集进行了标准化处理,遵循BPX-1.1符号约定与BattINFO本体对齐的列命名规范,生成了第二层级(Tier 2)的规范视图。构建过程主要涉及模式重命名与数据协调,尤其在容量列(将多个容量指标统一为带符号的瞬时容量)、温度列(从五个表面温度传感器中选用首要传感器数据)及符号约定(通过实证检查确定源数据电流正负含义,翻转至充电为正、放电为负的标准)三个方面进行了关键性整合。最终输出为符合bsebench_specs v0.2.0 TimeSeriesSchema的Parquet文件,每个电池对应一个文件或全部199个电池合并为一个长格式文件。
特点
该数据集的核心特点在于其高度标准化与跨数据集兼容性。所有电池的循环数据均统一为10列标准模式,包括cell_id、time_s、voltage_V、current_A、temperature_C、cycle_number、step_id、capacity_Ah、soc_truth及soh_truth,其中soc_truth和soh_truth为BDF源数据所不具备的推导真值列,分别基于累积吞吐量与逐周期放电容量的计算生成。数据集严格遵循BPX-1.1符号规范,确保电流符号在充放电场景下具有一致物理含义。温度列通过降维处理仅保留首个非空传感器数据,降低了下游滤波算法的复杂度。此外,每个电池的元数据(如化学体系、标称容量、电解质类型)以侧车列形式展开,并提供独立的cells.parquet文件以便灵活查询完整溯源图。整个第二层级数据集已通过TimeSeriesSchema验证,用户可直接接入滤波器流水线而无需额外的空值防御逻辑。
使用方法
使用该数据集时,用户可通过Hugging Face Hub的snapshot_download函数下载整个数据集仓库,然后利用Pandas库读取Parquet文件。主数据文件cycling.parquet以长格式存储全部199个电池的时序循环数据,可直接加载为DataFrame进行多维筛选与分析。例如,通过读取单元格元数据文件cells.parquet,用户可按化学体系(如LFP_graphite)筛选目标电池ID,进而从主表中提取对应子集用于后续建模或评估。数据集内建的soc_truth与soh_truth列免去了用户自行推导荷电状态与健康状态的工作量,使得该数据集成为电池状态估计算法基准测试的理想输入。如需获取原始位精确的RO-Crate数据,可转向第一层级(Tier 1)镜像仓库bsebench-org/empa-aurora-2025-raw。引用时需注明原始论文与Zenodo数据记录,若使用BSEBench工具链则建议同时引用BSEBench相关文献。
背景与挑战
背景概述
Empa Aurora 2025数据集由瑞士联邦材料科学实验室(Empa)、苏黎世联邦理工学院(ETH Zürich)、洛桑联邦理工学院(EPFL)及SINTEF于2025年7月联合发布,隶属于LF能源电池数据联盟的电池数据格式(BDF)生态体系。该数据集聚焦于锂离子扣式电池的循环老化测试,涵盖199个电芯的连续充放电时序数据,涉及NMC、LFP及石墨等多种化学体系。其核心研究问题在于通过高精度自动化机器人平台(Aurora)生成标准化电池老化数据,以支撑荷电状态(SoC)与健康状态(SoH)估计算法的基准测试。作为BSEBench(电池状态估计滤波器基准)的二级标准化视图,该数据集通过统一列名与符号约定实现跨数据集兼容,对推动电池管理算法在工业级场景中的可重复验证具有里程碑意义。
当前挑战
该数据集的核心挑战在于解决电池状态估计领域的通用性问题:当前工业界缺乏统一符号约定与标准化时序模式,导致滤波器算法难以跨数据集迁移验证。构建过程中面临三大技术难点:其一,源数据BDF格式未明确定义电流符号与充放电方向的关系,需通过经验性校验强制对齐至BPX-1.1规范(充电为正、放电为负);其二,多温度传感器(T1至T5)降维为单一温度列时,需定义非空回退逻辑以避免信息丢失;其三,容量列存在五种不同语义的并行定义(如瞬时充放电容量、累积容量等),必须选择与电流积分一致的有符号即时容量作为标准列。此外,SoC与SoH真值的推导需依赖精确的周期容量核算与累积通量计算,对数据完整性与时序连续性提出严苛要求。
常用场景
经典使用场景
在电池健康管理与状态估计领域,Empa Aurora 2025数据集为锂离子电池的充放电循环性能分析提供了标准化的时序基准。该数据集覆盖了199枚扣式电池的完整循环历程,囊括NMC、LFP等多种主流正极化学体系。其经典使用场景包括开发与验证基于电压、电流、温度等时序信号的电池荷电状态(SoC)与健康状态(SOH)联合估计模型,尤其是在卡尔曼滤波、粒子滤波等状态空间估计器的性能对比中,该数据集以其高时间分辨率和多参数同步记录特性,成为不可多得的理想测试平台。
衍生相关工作
该数据集的发布催生了多项具有里程碑意义的衍生工作。BSEBench基准测试框架依托该数据集的Tier-2规范视图,构建了首个面向电池状态滤波器性能对比的开源评测套件,涵盖多个经典卡尔曼滤波变体与深度学习基线。此外,研究人员在其基础上发展了面向不同电化学体系的跨化学体系迁移学习策略,并提出了针对该数据集容量列多种语义选择方案的系统性分析,这些工作共同推动了电池数据标准化协议(如BPX-1.1与BDF)在机器学习社区中的广泛采纳与深化应用。
数据集最近研究
最新研究方向
面向电池健康状态估计的时序数据标准化与基准测试
以上内容由遇见数据集搜集并总结生成


