Genesis_Dataset
收藏魔搭社区2025-11-26 更新2025-06-07 收录
下载链接:
https://modelscope.cn/datasets/zRzRzRzRzRzRzR/Genesis_Dataset
下载链接
链接失效反馈官方服务:
资源简介:
# Genesis: Multimodal Multi-Party Dataset for Emotional Causal Analysis
> Code: [GitHub](https://github.com/zRzRzRzRzRzRzR/Genesis)<br>
> Paper: [arXiv (Comming Soon)]()
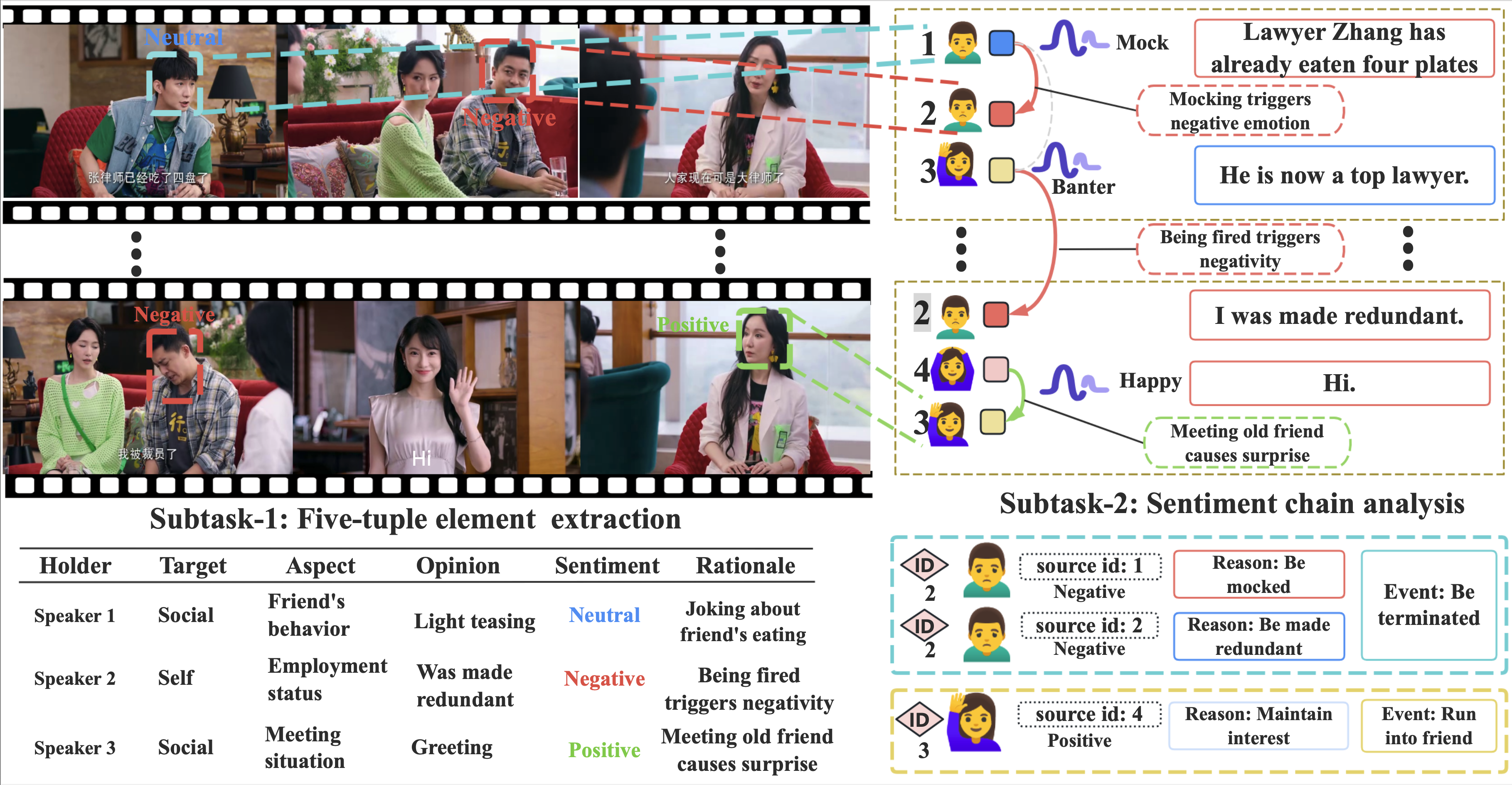
Genesis contains 1,000 dialogues (average 208 turns each) across diverse real-life settings (debate, family, education,
social). We use a two-layer annotation system to capture both immediate emotional triggers and long-term causal chains,
including cross-modal inconsistencies and long-distance emotional dependencies.
We benchmark 20 popular multimodal models and find they struggle with long-term emotional reasoning. To address this, we
propose Empathica, a new evaluation baseline using a Recognition-Memory-Attribution framework that outperforms both
text-based and multimodal models.
## Dataset Information
### Format
The dataset contains two folders: `texts` and `videos`.The `texts` folder stores subtitle files along with emotion
five-tuples for each sentence.The `videos` folder stores the corresponding video files.Each video corresponds to one
subtitle file, with the naming format `chat_*.json` and `chat_*.mp4`.Each sentence in the subtitle file follows the
format below:
```json
[
{
"sentence": "本场的辩题是,如果注定无法成功,该不该继续努力?",
"Holder": "2",
"Target": "",
"Aspect": "",
"Opinion": "",
"Sentiment": "",
"Rationale": "",
"time": "00:00"
}
]
```
### Structure
The data is stored in two folders, with 200 files each for videos and text respectively.
The directory structure is as follows:
```plaintext
.
├── README.md
├── texts
│ ├── chat_1.json
│ ├── chat_2.json
│ ...
│ └── chat_200.json
└── videos
├── chat_1.mp4
├── chat_2.mp4
...
└── chat_200.mp4
```
## Citation
If you find our work helpful, please consider citing the following paper.
```bibtex
Coming Soon
```
# Genesis:用于情感因果分析的多模态多方对话数据集
> 代码仓库:[GitHub](https://github.com/zRzRzRzRzRzRzR/Genesis)<br>
> 论文:[arXiv(即将上线)]()

本数据集包含1000段对话(平均每段208轮),涵盖辩论、家庭、教育、社交等多种真实生活场景。我们采用双层标注体系,以捕捉即时情感触发因素与长期因果链条,其中包含跨模态不一致性与长距离情感依赖关系。
我们对20款主流多模态模型开展基准测试,发现此类模型在长期情感推理任务中表现欠佳。为此,我们提出Empathica——一种基于**识别-记忆-归因(Recognition-Memory-Attribution)**框架的新型评估基准,其性能优于现有基于文本的模型与多模态模型。
## 数据集信息
### 格式
本数据集包含`texts`与`videos`两个文件夹。其中`texts`文件夹存储字幕文件,以及每一句对应的情感五元组;`videos`文件夹存储对应的视频文件。每段视频对应一份字幕文件,命名格式分别为`chat_*.json`与`chat_*.mp4`。字幕文件中的每一句均遵循如下格式:
json
[
{
"sentence": "本场的辩题是,如果注定无法成功,该不该继续努力?",
"Holder": "2",
"Target": "",
"Aspect": "",
"Opinion": "",
"Sentiment": "",
"Rationale": "",
"time": "00:00"
}
]
### 结构
数据存储于两个文件夹中,视频与文本文件各200份。目录结构如下:
plaintext
.
├── README.md
├── texts
│ ├── chat_1.json
│ ├── chat_2.json
│ ...
│ └── chat_200.json
└── videos
├── chat_1.mp4
├── chat_2.mp4
...
└── chat_200.mp4
## 引用
若您的工作得益于本数据集,请引用如下论文。
bibtex
即将上线
提供机构:
maas
创建时间:
2025-05-31


