TalTechNLP/err-video-news-transcribed
收藏Hugging Face2026-03-31 更新2026-04-05 收录
下载链接:
https://hf-mirror.com/datasets/TalTechNLP/err-video-news-transcribed
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-sa-4.0
task_categories:
- automatic-speech-recognition
language:
- et
---
# Transcribed ERR Video News Dataset
This dataset contains transcriptions of video news stories from Estonian National Brroacasting (https://www.err.ee/). There are around 40K stories with a total duration of around 4000 hours.
Transcriptions are generated automatically using speech recognition (gemini-3-flash-preview). Contextual biasing was used to improve ASR quality, using the textual news story about the same topic.
The WER of the transcriptions is around 5% on the average.
The dataset has been heavily filtered to contain only those stories where the corresponding video contains mostly Estonian speech. That is, news pieces that contain a lot of non-Estonian speech and/or music have been removed.
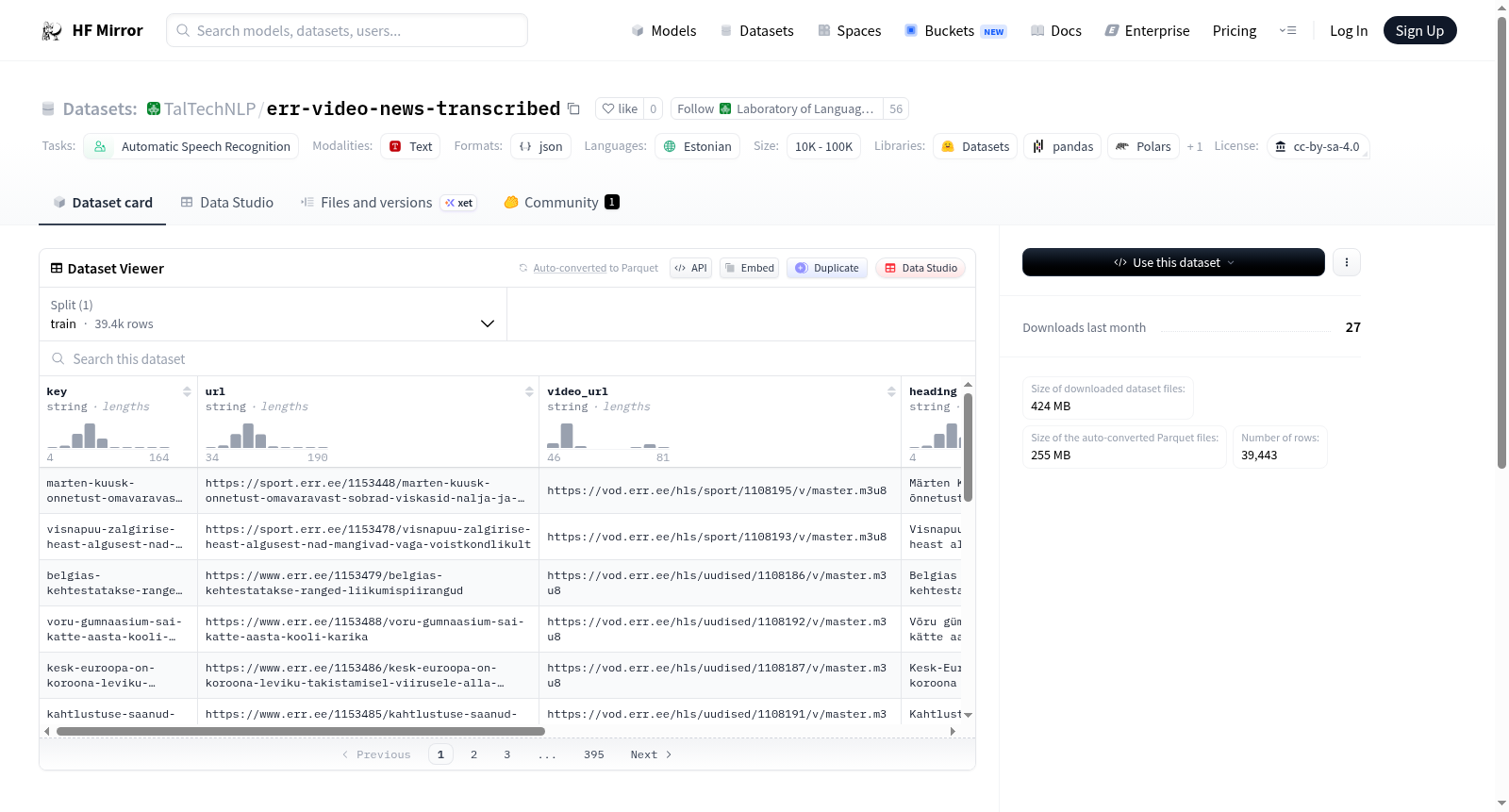
For each story, the dataset provides heading, leadin text and the main body of the textual news story, as well as the transcript of the video news story.
In addition, there is also the "subtitles" field, that contains the same text as in the "transcript" field, but segmented into VTT-formatted subtitles,
where each subtitle block represents one sentence. Sentence/subtitle start and end times are obtained using forced alignment.
In order to avoid copyright problems, audio/video data is not included in the dataset. However, links to web pages where the original video can be scraped is provided for each story.
Contact tanel.alumae@taltech.ee if you need help with downloading the audio.
提供机构:
TalTechNLP
搜集汇总
数据集介绍
构建方式
在爱沙尼亚语语音识别研究领域,数据资源的构建往往面临语言材料稀缺的挑战。本数据集以爱沙尼亚国家广播公司的视频新闻为原始素材,通过自动化流程生成文本转录。具体而言,利用先进的语音识别模型对约四万条新闻视频进行自动转写,并结合对应主题的文本新闻内容进行上下文偏置处理,以提升识别准确率。为确保语言纯净度,数据集经过严格筛选,剔除了包含大量非爱沙尼亚语对话或音乐片段的新闻条目,最终形成了总计约四千小时的语音转录文本集合。
特点
该数据集的核心特征在于其高质量、大规模的爱沙尼亚语语音-文本对齐资源。转录文本的平均词错误率控制在5%左右,展现了较高的自动转写可靠性。每条数据记录不仅包含视频新闻的完整转录文本,还提供了新闻标题、导语和正文等丰富的元信息。尤为突出的是,数据集额外提供了按句子分割、并带有精确起止时间戳的VTT格式字幕文件,这些时间信息通过强制对齐技术获得,为语音分割、句子边界检测等细粒度研究提供了便利。尽管未包含原始音视频文件,但每条数据均附有可获取原始媒体的网页链接。
使用方法
本数据集主要服务于自动语音识别模型的训练与评估,尤其适用于资源相对稀缺的爱沙尼亚语相关研究。研究人员可直接利用其高质量的转录文本与对应的时间对齐信息,进行端到端语音识别系统的开发,或用于构建语音活动检测、句子切分等下游任务的基准测试。对于希望获取原始音频的研究者,可通过数据集提供的网页链接自行爬取,或联系维护者获取协助。数据集的结构化设计也使其适用于多模态学习、新闻内容分析等更广泛的应用场景。
背景与挑战
背景概述
随着自动语音识别技术的快速发展,高质量、大规模语音数据集的构建成为推动该领域进步的关键。在此背景下,爱沙尼亚塔尔图大学的研究团队于近期创建了名为“err-video-news-transcribed”的数据集,该数据集源自爱沙尼亚国家广播公司的视频新闻内容。该数据集的核心研究问题聚焦于如何利用先进的语音识别模型,结合上下文偏置技术,从真实世界的新闻视频中自动生成高准确度的转录文本,从而为爱沙尼亚语的语音处理研究提供宝贵的资源。其约4000小时的转录内容,不仅丰富了低资源语言的语料库,也为新闻内容分析、多模态学习等研究方向开辟了新的可能性,对促进波罗的海区域的语言技术发展具有显著影响力。
当前挑战
该数据集旨在解决爱沙尼亚语自动语音识别任务中的核心挑战,即如何在真实、嘈杂的新闻视频环境下,实现高精度的语音到文本转换。具体而言,挑战体现在对非纯净语音片段的处理上,例如新闻中夹杂的外语对话或背景音乐,这些因素会显著降低识别模型的性能。在构建过程中,研究团队面临的主要挑战包括数据清洗与过滤的复杂性,需要从海量视频中筛选出以爱沙尼亚语为主的片段;同时,在缺乏原始音视频数据的情况下,仅依靠文本转录与外部链接来构建可用的数据集,这为数据的完整性验证与后续的音频获取带来了额外的技术障碍。
常用场景
经典使用场景
在自动语音识别领域,该数据集为爱沙尼亚语语音处理研究提供了宝贵的资源。研究者常利用其大规模转录视频新闻内容,训练和评估端到端语音识别模型,特别是在处理新闻广播这类正式、结构清晰的语音场景时,数据集的高质量转录能有效提升模型在真实环境下的识别准确率。
衍生相关工作
围绕该数据集,已衍生出多项经典研究工作,包括基于语境偏置的语音识别改进、低资源语言端到端模型训练,以及多模态新闻内容分析。这些工作不仅提升了爱沙尼亚语ASR性能,还为其他小语种提供了可迁移的技术框架,促进了语音处理领域的多样化发展。
数据集最近研究
最新研究方向
在自动语音识别领域,基于大规模转录数据的研究正日益聚焦于低资源语言的性能提升。ERR视频新闻转录数据集作为爱沙尼亚语的重要语料库,其前沿探索主要集中在利用上下文偏置技术优化ASR系统,通过结合同主题文本新闻来增强语音识别的准确性。当前热点事件涉及多模态学习与跨语言迁移,研究者借助该数据集的视频链接与文本对齐信息,开发鲁棒性更强的端到端模型,以应对新闻场景中语音与背景音乐的复杂干扰。这些进展不仅推动了波罗的海地区语言技术的本土化应用,也为小语种数字内容的可访问性提供了关键支持,具有显著的学术与实用价值。
以上内容由遇见数据集搜集并总结生成


