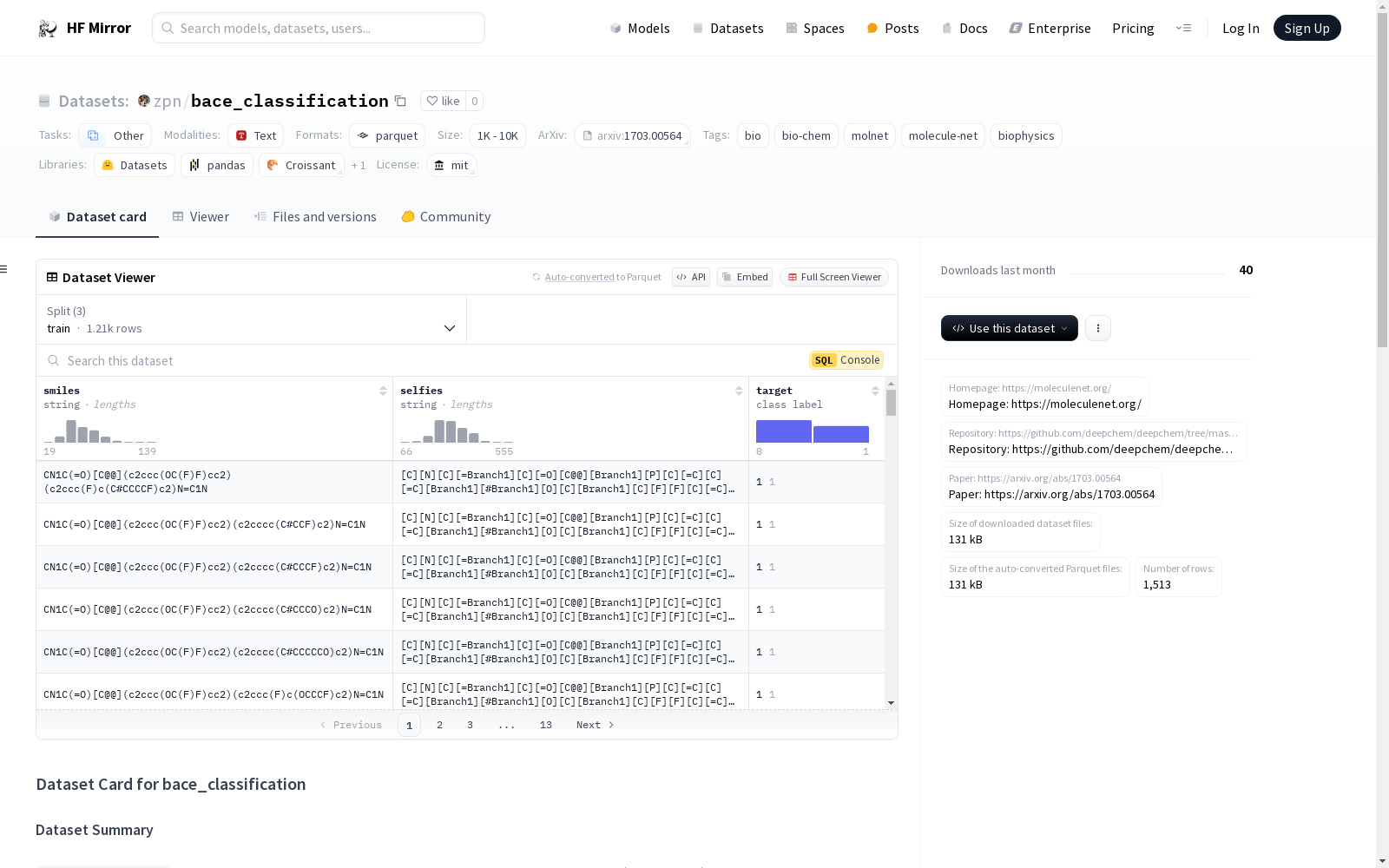
zpn/bace_classification
收藏数据集卡片 for bace_classification
数据集描述
数据集摘要
bace_classification 是 MoleculeNet 包含的数据集之一。该数据集包含一组人β-分泌酶1(BACE-1)抑制剂的定性(二元标签)结合结果。
数据集结构
数据字段
每个分割包含:
数据分割
数据集采用 scaffold split 方法分为 80/10/10 的训练/验证/测试集。
源数据
初始数据收集和规范化
数据最初由斯坦福大学的 Pande 组生成。
许可信息
该数据集最初在 MIT 许可证下发布。
引用信息
@misc{https://doi.org/10.48550/arxiv.1703.00564, doi = {10.48550/ARXIV.1703.00564},
url = {https://arxiv.org/abs/1703.00564},
author = {Wu, Zhenqin and Ramsundar, Bharath and Feinberg, Evan N. and Gomes, Joseph and Geniesse, Caleb and Pappu, Aneesh S. and Leswing, Karl and Pande, Vijay},
keywords = {Machine Learning (cs.LG), Chemical Physics (physics.chem-ph), Machine Learning (stat.ML), FOS: Computer and information sciences, FOS: Computer and information sciences, FOS: Physical sciences, FOS: Physical sciences},
title = {MoleculeNet: A Benchmark for Molecular Machine Learning},
publisher = {arXiv},
year = {2017},
copyright = {arXiv.org perpetual, non-exclusive license} }
贡献
感谢 @zanussbaum 添加此数据集。