FastText: Common Crawl
收藏fasttext.cc2024-10-31 收录
下载链接:
https://fasttext.cc/docs/en/crawl-vectors.html
下载链接
链接失效反馈官方服务:
资源简介:
FastText: Common Crawl 数据集是由Facebook AI Research团队发布的,包含从Common Crawl网络爬虫中提取的大规模文本数据。该数据集用于训练FastText模型,旨在支持词向量和文本分类任务。
FastText: Common Crawl Dataset is released by the Facebook AI Research (FAIR) team. It contains large-scale text data extracted from the Common Crawl web crawler corpus. This dataset is designed for training FastText models, with the objective of supporting word vector learning and text classification tasks.
提供机构:
fasttext.cc
搜集汇总
数据集介绍
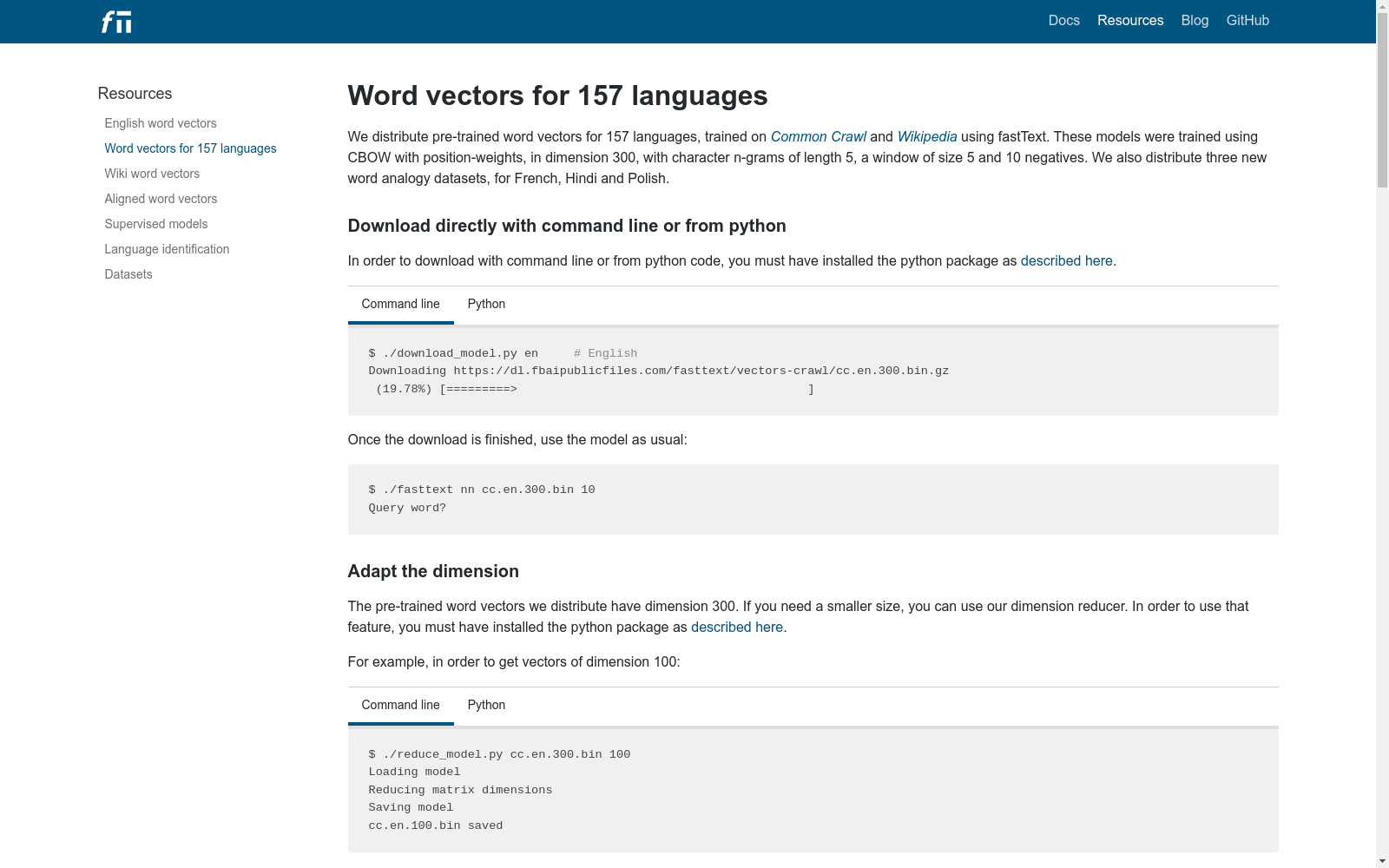
构建方式
FastText: Common Crawl数据集的构建基于大规模的网页抓取数据,即Common Crawl项目。该数据集通过从数十亿网页中提取文本内容,并应用自然语言处理技术进行清洗和预处理,最终生成一个包含丰富词汇和语义信息的文本数据库。构建过程中,采用了高效的分布式计算框架,确保数据处理的规模和速度,同时通过多层次的过滤机制,剔除噪声和无关信息,以保证数据质量。
使用方法
FastText: Common Crawl数据集适用于多种自然语言处理任务,包括但不限于文本分类、情感分析、机器翻译和信息检索。研究人员可以通过下载预处理的数据集文件,或直接访问在线API接口,获取所需的数据资源。在使用过程中,建议结合具体的应用场景,选择合适的模型和算法进行训练和评估,以充分发挥数据集的潜力。同时,考虑到数据集的规模,建议使用高性能计算资源以提高处理效率。
背景与挑战
背景概述
FastText: Common Crawl数据集由Facebook AI Research团队于2016年创建,旨在解决大规模文本数据的词向量表示问题。该数据集基于Common Crawl项目,通过爬取数十亿网页的文本数据,构建了一个包含数百万词汇的词向量模型。主要研究人员包括Piotr Bojanowski和Edouard Grave等,他们的研究重点在于如何高效地从海量非结构化文本中提取有意义的特征,以提升自然语言处理任务的性能。FastText: Common Crawl的发布对词嵌入领域产生了深远影响,为后续研究提供了丰富的资源和基准。
当前挑战
FastText: Common Crawl数据集在构建过程中面临诸多挑战。首先,数据来源的多样性和噪声问题使得数据预处理变得复杂,需要高效的清洗和过滤机制。其次,如何在保持计算效率的同时,确保词向量的质量和表达能力,是一个关键的技术难题。此外,数据集的规模庞大,对存储和计算资源提出了高要求,如何在有限的资源下进行有效的模型训练和优化,也是研究人员需要克服的挑战。最后,数据集的广泛应用也带来了隐私和伦理问题,如何在利用数据的同时保护用户隐私,是当前亟待解决的问题。
发展历史
创建时间与更新
FastText: Common Crawl数据集由Facebook AI Research团队于2016年创建,旨在利用大规模的Common Crawl数据进行词向量训练。该数据集自创建以来,经历了多次更新,以适应不断变化的语言使用和数据需求。
重要里程碑
FastText: Common Crawl数据集的一个重要里程碑是其在2017年发布的版本,该版本引入了子词信息,显著提升了低频词和罕见词的表示能力。此外,2018年,该数据集被广泛应用于多语言词向量训练,进一步推动了跨语言自然语言处理技术的发展。这些里程碑不仅提升了数据集的实用性,还为后续研究提供了坚实的基础。
当前发展情况
当前,FastText: Common Crawl数据集已成为自然语言处理领域的重要资源,广泛应用于文本分类、情感分析和机器翻译等任务。其持续的更新和优化,确保了数据集在处理现代语言现象时的有效性。此外,该数据集的开源性质促进了全球研究者的合作,推动了相关技术的快速发展。FastText: Common Crawl不仅在学术界产生了深远影响,也在工业界得到了广泛应用,为语言模型的训练和评估提供了宝贵的数据支持。
发展历程
- FastText: Common Crawl数据集首次发布,由Facebook AI Research团队开发,旨在提供大规模的文本数据用于训练词向量模型。
- FastText: Common Crawl数据集首次应用于自然语言处理任务,特别是在词嵌入和文本分类领域,展示了其在大规模数据处理中的有效性。
- FastText: Common Crawl数据集被广泛应用于多个研究项目和工业应用中,成为自然语言处理领域的重要资源之一。
- FastText: Common Crawl数据集的更新版本发布,进一步优化了数据质量和模型训练效果,提升了其在实际应用中的表现。
- FastText: Common Crawl数据集在多个国际会议和期刊上被引用和讨论,展示了其在推动自然语言处理技术发展中的重要作用。
常用场景
经典使用场景
在自然语言处理领域,FastText: Common Crawl数据集被广泛用于词向量训练。其经典使用场景包括但不限于文本分类、情感分析和命名实体识别。通过利用大规模的网页数据,该数据集能够生成高质量的词向量,从而提升模型在处理复杂语言任务时的表现。
解决学术问题
FastText: Common Crawl数据集解决了传统词向量模型在处理稀有词和短语时的局限性。通过引入子词信息,该数据集能够更准确地表示词汇的语义,从而在学术研究中显著提升了模型的泛化能力和鲁棒性。这一创新为自然语言处理领域的研究提供了新的视角和工具。
实际应用
在实际应用中,FastText: Common Crawl数据集被广泛应用于搜索引擎优化、社交媒体分析和客户服务自动化等领域。例如,搜索引擎公司利用该数据集训练的词向量模型,能够更精准地理解用户的查询意图,从而提供更相关的搜索结果。此外,社交媒体平台通过分析用户生成的内容,可以更有效地进行情感分析和趋势预测。
数据集最近研究
最新研究方向
在自然语言处理领域,FastText: Common Crawl数据集的最新研究方向主要集中在提升文本表示的效率与准确性。研究者们致力于通过优化词嵌入算法,以更好地捕捉大规模语料库中的语义信息。此外,该数据集还被广泛应用于跨语言文本分类和情感分析任务中,通过多语言模型的构建,实现了不同语言间信息的有效传递与融合。这些研究不仅推动了自然语言处理技术的发展,也为全球范围内的信息处理提供了更为强大的工具。
相关研究论文
- 1Enriching Word Vectors with Subword InformationFacebook AI Research · 2017年
- 2Bag of Tricks for Efficient Text ClassificationFacebook AI Research · 2016年
- 3Learning Word Vectors for 157 LanguagesFacebook AI Research · 2018年
- 4Advances in Pre-Training Distributed Word RepresentationsGoogle AI Language · 2018年
- 5Efficient Estimation of Word Representations in Vector SpaceGoogle AI Language · 2013年
以上内容由遇见数据集搜集并总结生成


