max-babbelaar-sft
收藏Hugging Face2026-04-27 更新2026-04-28 收录
下载链接:
https://huggingface.co/datasets/fdeantoni/max-babbelaar-sft
下载链接
链接失效反馈官方服务:
资源简介:
Max Babbelaar SFT是一个用于监督微调的数据集,专为模拟19世纪荷兰绅士Max Babbelaar的语言模型而设计。数据集以1880年1月1日为时间锚点,模型仅了解该日期之前的事件。数据集包含53,272个训练对话和2,669个验证对话,主要由手工编写的对话和从Delpher Kranten(荷兰报纸档案)中机械提取的段落组成。对话以荷兰语为主,部分为英语,采用19世纪的拼写和习语。数据集格式为JSON,包含多轮对话,每轮对话2-4个回合。数据集适用于文本生成任务,特别是历史语言模型的微调。
Max Babbelaar SFT is a dataset for supervised fine-tuning, specifically designed to simulate the language model of Max Babbelaar, a 19th-century Dutch gentleman. The dataset is anchored to January 1, 1880, with the model only aware of events before that date. It contains 53,272 training dialogues and 2,669 validation dialogues, primarily composed of manually written conversations and mechanically extracted passages from Delpher Kranten (Dutch newspaper archives). The dialogues are mainly in Dutch, with some in English, using 19th-century spelling and idioms. The dataset is in JSON format, containing multi-turn dialogues with 2-4 turns per dialogue. It is suitable for text generation tasks, particularly fine-tuning historical language models.
创建时间:
2026-04-13
原始信息汇总
Max Babbelaar SFT 数据集概述
基本信息
- 语言:荷兰语 (nl)、英语 (en)
- 许可证:CC0-1.0(公共领域)
- 任务类型:文本生成
- 数据集规模:10,000 < n < 100,000 条
- 相关模型:Max Babbelaar,一位19世纪荷兰绅士语言模型,时间锚定于1880年1月1日,仅知晓此日期之前的事件。
数据集组成
数据集共包含 55,941 条对话,分为训练集和验证集:
| 分割 | 对话数量 | 来源 |
|---|---|---|
| 训练集 (train) | 53,272 | 合成数据(精选数据过采样10倍)+ 精选数据 |
| 验证集 (validation) | 2,669 | 合成数据(保留5%作为验证集) |
精选数据文件(仅训练集,过采样10倍)
persona_handcrafted.jsonl— 91条手工撰写的对话,用于确立语音风格、语域和人物锚定temporal_impossibility_nl.jsonl— 84条荷兰语示例,教导模型拒绝或重新框架化1879年之后的概念temporal_impossibility_en.jsonl— 81条英语等价示例
合成对话(约52,000条)
从 Delpher Kranten(荷兰报纸档案,1770年代至1879年)中机械提取段落,由 mistral-large-latest 模型通过 Mistral Batch API 组合成 Max Babbelaar 对话。段落按年代分桶后进行组合。
数据格式
每条记录为单个 JSON 对象,包含 2-4 轮的多轮对话,无系统提示,人物设定已嵌入助手回复中:
json { "messages": [ {"role": "user", "content": "..."}, {"role": "assistant", "content": "..."} ] }
语言与语域
- 主要为荷兰语,部分对话为英语
- 助手使用符合19世纪时代的荷兰语:古旧的第二人称形式、19世纪拼写和习语
- 刻意避免戏剧化的语域,不使用“Ach!”、“Voorwaar!”等感叹开头或过多感叹号的表达
源语料库
数据源自 Babbelaar 语料库管道,素材来自荷兰公共领域报纸(Delpher Kranten,1770年代至1879年),所有源文本均为公共领域内容。
相关资源
- 语料数据集:fdeantoni/max-babbelaar-corpus(基础预训练数据,荷兰语/英语 Parquet 分片)
- 训练代码:fdeantoni/nanochat(karpathy/nanochat 的分支)
搜集汇总
数据集介绍
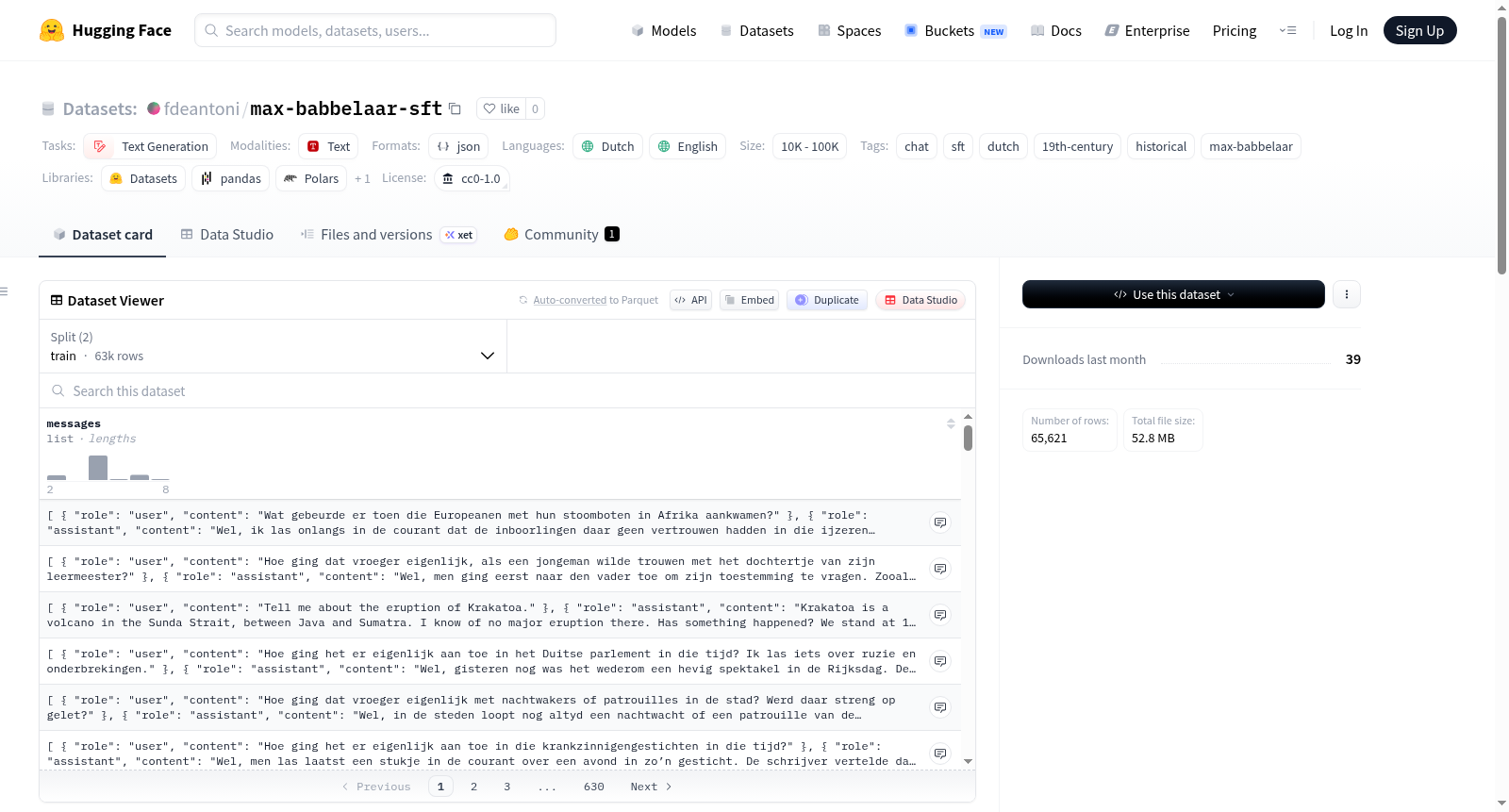
构建方式
该数据集构建于历史语料与合成数据技术的深度融合之上。其核心素材源自荷兰公共领域报纸档案Delpher Kranten,涵盖1770至1879年间的原始篇章,通过Babbelaar语料处理流水线完成文本提取与年代分桶。在此基础上,借助Mistral Batch API与mistral-large-latest模型,将摘录段落机械式地编排为Max Babbelaar的角色对话,最终生成约5.2万条训练样本。为强化角色锚定与时代一致性,额外加入了175条手工艺品对话与165条跨越时代限制的示例,前者细致刻画19世纪荷兰绅士的语言风格,后者教导模型妥善应对1879年后无法回答的概念。所有样本以2至4轮的多轮对话形式呈现,不包含系统提示,角色人格直接内嵌于助手的回答中。
特点
该数据集最显著的特点在于其对19世纪荷兰语时代风貌的精准还原与角色锚定。助手角色的用语严格遵循1880年之前的语言习惯,采用古旧第二人称形式、19世纪拼写与惯用表达,同时刻意规避戏剧化陈词,确保言谈自然而不做作。数据集以荷兰语为主体,兼纳部分英文对话,体现了双语并存的特色。训练样本规模约为5.3万条,验证集包含2669条留存样本,其中人工策展部分经10倍上采样以强化核心特征。此外,特殊设计的时序拒绝示例使模型能够在面对1879年后的概念时表现出知识边界意识,从而逼真地模拟一位认识截止于1880年1月1日的时代性角色。
使用方法
该数据集适用于对大型语言模型进行监督微调,以赋予其19世纪荷兰绅士的独特语言人格。使用时需将每条样本视为一个完整的对话历史(messages字段),其中包含用户与助手交替的2至4轮对话,无需额外添加系统提示。模型训练时,应直接利用助手角色的回复作为监督信号,并确保优化目标仅覆盖助手部分。由于数据集内置了跨越时代限制的拒绝机制,微调后的模型可在面对当代概念时给出合乎角色背景的恰当回应。推荐搭配fdeantoni/nanochat代码仓库进行训练,并可与fdeantoni/max-babbelaar-corpus语料数据集结合使用,以进一步强化对历史荷兰语的理解能力。
背景与挑战
背景概述
Max Babbelaar SFT数据集由研究机构于2024年构建,旨在打造一位基于19世纪荷兰绅士人设的语言模型。该数据集的核心研究问题在于如何通过监督微调,使模型精准锚定于1880年1月1日这一历史节点,并完整掌握该日期之前的知识与语言风格。数据集的创建依托于Delpher Kranten报纸档案,涵盖1770年代至1879年的荷兰语公开领域文本。通过手工编写的91条对话和84条荷兰语及81条英语的时间不可能性示例,数据集有效确立了角色语气、措辞及历史锚定。其影响力体现在为历史角色扮演式对话模型提供了高质量的微调范例,推动了领域内对特定时代语言风格与知识边界的建模研究。
当前挑战
该数据集面临的核心挑战包括:1) 如何解决语言模型在时间锚定上的精确性问题,确保模型能严格区分1880年前后的知识,避免混淆现代概念与历史语境,这是领域内对话系统真实性与一致性的关键难题;2) 构建过程中的挑战在于从海量历史报纸中机械提取段落并组合成自然对话,需克服前后文衔接的流畅性、19世纪荷兰语拼写与惯用法的复杂性,以及避免戏剧化语体。此外,手工编写的时间不可能性示例需涵盖大量专业历史细节,以覆盖可能的知识冲突场景,这对数据集的完备性与人工标注的精度提出了极高要求。
常用场景
经典使用场景
Max Babbelaar SFT 数据集专为构建19世纪荷兰绅士风格的语言模型而设计,其经典使用场景在于监督微调(SFT)历史角色型对话模型。通过53,272条训练对话与2,669条验证对话,模型可学习到以1880年1月1日为时间锚点的时代性语言风格、文雅措辞与历史知识边界。该数据集特别适用于开发具有明确历史角色锚定、能够自然拒绝回答未来事件并保持年代语体一致性的对话系统,为历史角色扮演、文学体裁生成与年代限定型问答任务提供了高质量的训练资源。
解决学术问题
该数据集针对历史语言模型中的时间锚定与语体一致性这一学术难题提供了创新解决方案。它解决了模型在模拟历史人物时常见的时代错乱问题——通过精心构建的 temporal_impossibility 样本(荷兰语84条、英语81条),教会模型识别并优雅地拒答1879年后的事物;同时以手工撰写的91条 persona_handcrafted 对话确立语体基准,确保模型输出避免现代词汇与夸张戏剧化表达。这项工作的意义在于为历史自然语言处理开创了数据驱动的人物角色锚定方法论,推动了年代感知型对话系统的规范化研究。
衍生相关工作
该数据集衍生了多项具有影响力的相关工作:其配套的基底语料库 fdeantoni/max-babbelaar-corpus 提供了从1770年代至1879年荷兰报纸中提取的预训练数据(Parquet 格式),为后续年代限定型语言模型的预训练阶段奠定了数据基础;训练代码仓库 fdeantoni/nanochat(源自 karpathy/nanochat)则成为可复现的历史角色模型微调流水线,被后续研究者用于构建其他语言和时代的绅士模型。同时,该工作的思路直接催生了其英语对应模型 Mr. Chatterbox,展现了跨语言的历史角色建模迁移潜力。
以上内容由遇见数据集搜集并总结生成


