Preethi Dataset
收藏arXiv2025-09-30 更新2025-10-02 收录
下载链接:
https://huggingface.co/datasets/Blue7Bird/Preethi_dataset
下载链接
链接失效反馈官方服务:
资源简介:
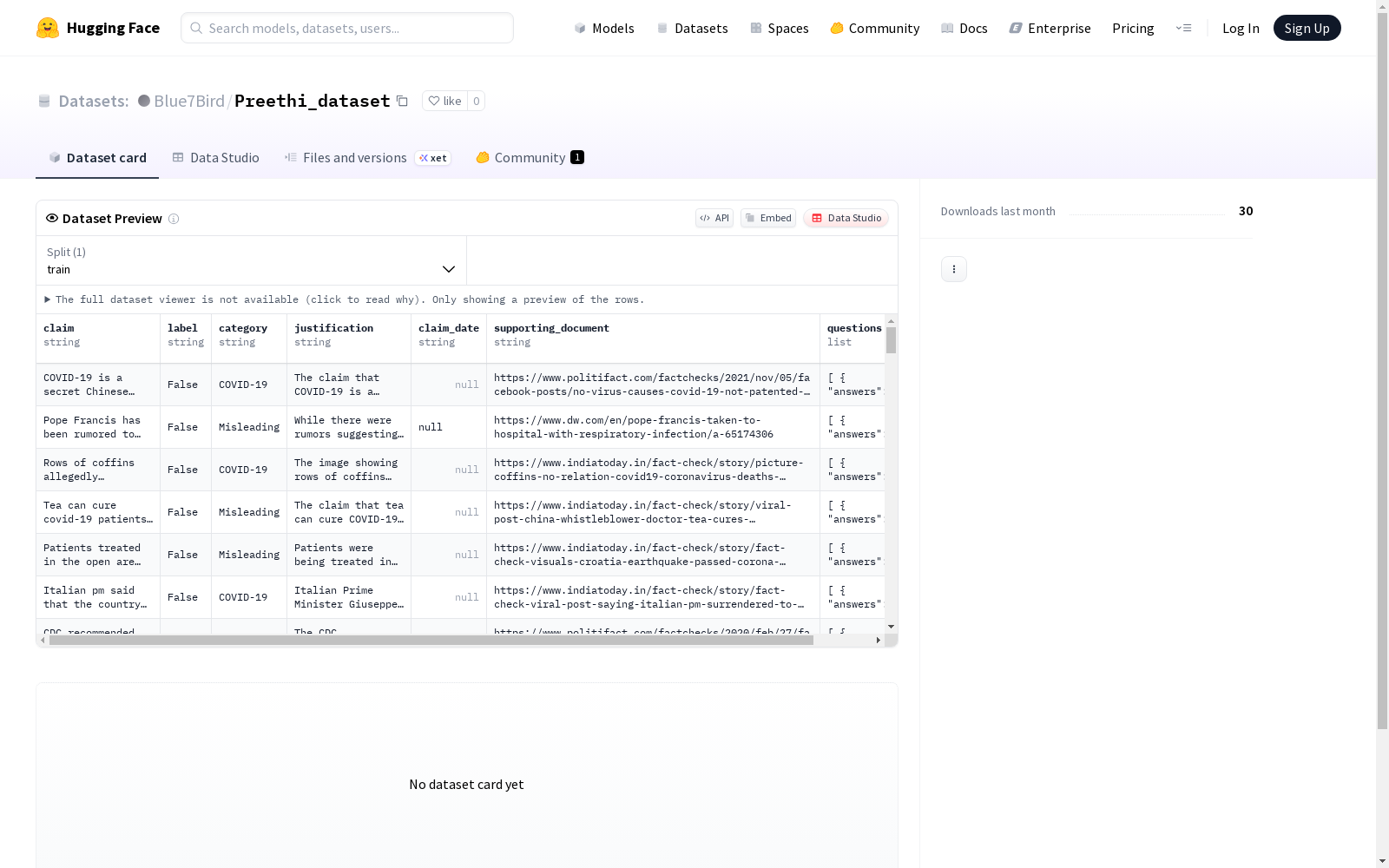
Preethi数据集是一个包含英语和泰卢固语的双语事实核查数据集,旨在支持多语言声明验证。该数据集基于公开的IFND数据集创建,包含来自IFND的2500个真实声明和从事实核查网站收集的2435个虚假声明。Preethi数据集为每个声明提供了额外的元数据,包括来自网络的支撑文档、声明日期、黄金解释和黄金QA对。数据集在泰卢固语中通过机器翻译后由人工后编辑以确保质量。该数据集旨在解决印度等多语言国家中通过翻译技术传播虚假信息的问题,并提高大型语言模型在事实核查任务中的性能。
The Preethi Dataset is a bilingual English-Telugu fact-checking dataset designed to support multilingual claim verification. It is built upon the publicly available IFND dataset, containing 2500 genuine claims sourced from IFND and 2435 false claims collected from public fact-checking websites. The dataset provides supplementary metadata for each claim, including web-retrieved supporting documents, claim publication dates, gold-standard explanations, and gold-standard QA pairs. The Telugu subset of the dataset was first machine-translated and then manually post-edited to ensure data quality. This dataset aims to address the issue of disinformation spread via translation technologies in multilingual countries such as India, and to improve the performance of large language models (LLMs) in fact-checking tasks.
提供机构:
Saarland University
创建时间:
2025-09-30
搜集汇总
数据集介绍
构建方式
在虚假信息检测研究领域,Preethi数据集的构建体现了对多语言事实核查资源的迫切需求。该数据集基于公开的印度虚假新闻数据集(IFND)进行优化,通过人工标注从原始数据中筛选出5,006条可验证的英文声明,涵盖新冠疫情、选举、政府事务、误导性信息和暴力事件五大主题。为确保声明完整性,研究团队通过谷歌搜索和微软Copilot追溯原始信息来源,重构因表述不完整或包含多命题而无法验证的声明条目。每条声明均附带人工标注的元数据,包括网络支持文档、声明日期、标准答案对和黄金论证文本,并通过三名标注者达成80%的声明真实性标注一致性与75%的布尔问题对一致性。
特点
作为双语事实核查资源,Preethi数据集最显著的特点是同时覆盖英语与泰卢固语两种语言体系,填补了低资源印度语言在开源标注数据方面的空白。其声明标注体系采用二元分类框架,将部分真实声明归为虚假类别以防范误导性信息传播。数据集创新性地引入三类人工构建的问题对:通过直接布尔问题验证声明真伪,间接布尔问题提供关联性证据链,抽象性与抽取性问题对则分别通过信息概括和原文摘录强化可解释性。与同类数据集相比,该资源首次在泰卢固语领域整合了人工标注的论证文本与问题对,并通过反向翻译与母语者人工校对确保跨语言数据的语义一致性。
使用方法
该数据集支持多种自然语言处理任务的基准测试,特别针对大语言模型在多语言环境下的声明验证与论证生成能力评估。研究实践中可采用简单提示法直接测试模型的内在知识储备,或结合检索增强生成框架构建多层次验证流程。在检索增强生成应用中,可通过朴素检索增强生成架构实现文档检索与向量匹配,进阶版本则融入查询重写、文档重排序与提示压缩技术以提升证据质量。自动爬取方法通过语义相似度计算从支持文档中提取关键内容,有效突破模型上下文长度限制。评估体系综合运用F1分数衡量声明分类性能,结合METEOR、ROUGE-L等指标评估生成文本质量,并通过匈牙利算法实现问题对的自动对齐分析。
背景与挑战
背景概述
随着虚假信息在全球范围内的传播日益严重,自动事实核查技术成为自然语言处理领域的重要研究方向。Preethi数据集由萨拉兰大学、巴斯克大学等机构的研究团队于2025年联合创建,旨在解决印度语境下多语言事实核查的挑战。该数据集基于公开的印度假新闻数据集进行优化,包含5,006条人工标注的英语声明,涵盖新冠疫情、选举、政府事务等五个关键领域,并通过机器翻译与人工校对构建了泰卢固语版本。作为首个同时提供人工标注问答对与论证依据的双语事实核查资源,该数据集显著提升了低资源语言事实核查模型的训练效果。
当前挑战
该数据集主要面临双重挑战:在领域问题层面,需应对多语言声明验证中存在的语义歧义与文化语境差异,特别是泰卢固语等低资源语言缺乏高质量训练数据的问题;在构建过程中,原始数据存在声明不完整、多声明混合等质量问题,需通过人工重构与跨语言对齐确保数据可靠性。此外,机器翻译带来的语法错误与语义偏差需通过31,465次人工校对修正,而双语论证生成的质量控制也要求设计复杂的评估指标体系。
常用场景
经典使用场景
在跨语言事实核查研究中,Preethi数据集作为首个公开的英语-泰卢固语双语标注资源,其经典应用场景聚焦于评估大语言模型在多语言环境下的声明验证能力。该数据集通过人工标注的真实性标签、问答对和理由说明,为研究者提供了系统测试检索增强生成框架与简单提示方法性能的基准平台,特别是在处理印度语境下的新冠疫情、选举等五大主题声明时展现出独特价值。
实际应用
在现实应用层面,该数据集为多语言社会的信息治理提供了技术支撑。新闻机构可基于其构建自动化事实核查系统,实时监测泰卢固语社交媒体中的虚假信息传播;政府监管部门能利用其跨语言验证能力,识别经由机器翻译篡改的政策谣言;教育机构则可借助其标注体系开发数字素养课程,帮助公众提升对多语言虚假信息的辨识能力。
衍生相关工作
该数据集的发布催生了多个创新研究方向:在方法层面,研究者基于其双语特性开发了混合提示模板优化策略,显著提升低资源语言的推理质量;在架构设计上,衍生出针对印度语境的多源检索增强框架,整合本地新闻源的实时更新机制;评估体系方面,推动建立了融合语义相似度与人工评估的多维质量指标体系,为后续跨语言事实核查数据集建设树立了新范式。
以上内容由遇见数据集搜集并总结生成


