TORGO-database
收藏TORGO 数据库:来自构音障碍者的语音数据集
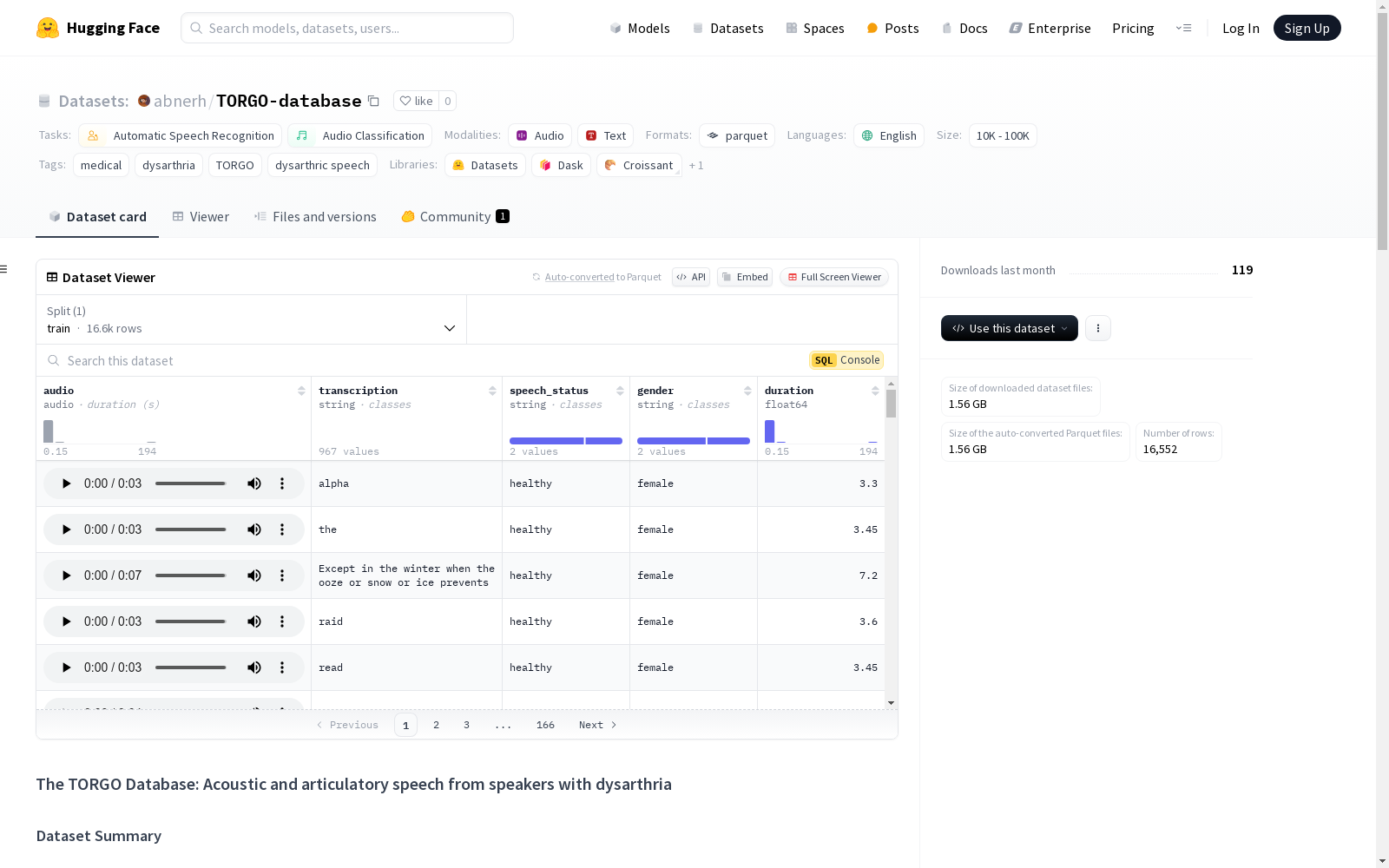
数据集概述
- 数据来源:仅包含 TORGO 数据集中短词和受限句子的部分。
- 完整数据集:如需包含非词和非受限句子的完整数据集,请访问 TORGO 数据集页面。
- 数据处理:转录文本已标准化,去除了标点符号,保留了大小写。部分仅包含 xxx 的转录文本已被移除。
- 数据量:约 5.5 小时的构音障碍语音数据和 8 小时的正常语音数据。
数据类别
短词
- 用途:适用于无需词边界检测的语音声学研究。
- 包含内容:
- 英语数字、yes、no、up、down、left、right、forward、back、select、menu 以及国际无线电字母表(如 alpha、bravo、charlie)的重复。
- 来自 Frenchay Dysarthria Assessment 的 50 个词。
- 来自 Yorkston-Beukelman Assessment of Intelligibility of Dysarthric Speech 的 360 个词。
- 英国国家语料库中最常见的 10 个词。
受限句子
- 用途:用于利用词汇、句法和语义处理的自动语音识别(ASR)。
- 包含内容:
- 预选的音素丰富的句子,如 "The quick brown fox jumps over the lazy dog"。
- 祖父段落。
- 来自 Yorkston-Beukelman Assessment of Intelligibility of Dysarthric Speech 的 162 个句子。
- MOCHA-TIMIT 数据库中使用的 460 个 TIMIT 派生句子。
数据集结构
- 数据点:包含音频文件路径及其转录文本。
- 附加字段:性别、语音状态(构音障碍或正常)和持续时间。
- 文件命名:格式为
speakerNumber_sessionNumber_micType_utteranceNumber.wav。- 说话者编号格式为
gender-speechStatus-speakerNumber(例如,FC01 = 女性控制组 #1,M04 = 男性构音障碍组 #4)。
- 说话者编号格式为
数据集加载示例
python from datasets import load_dataset
dataset = load_dataset("abnerh/TORGO-database") print(dataset) DatasetDict({ train: Dataset({ features: [audio, transcription, speech_status, gender, duration], num_rows: 16552 }) })
数据点示例
python print(dataset[train][0]) {audio: {path: FC01_1_arrayMic_0066.wav, array: array([ 0.00125122, 0.00387573, 0.00115967, ..., 0.00149536, -0.00326538, 0.00027466]), sampling_rate: 16000}, transcription: alpha, speech_status: healthy, gender: female, duration: 3.3}
python print(dataset[train][12200]) {audio: {path: M02_1_headMic_0066.wav, array: array([ 0.00115967, 0.00106812, 0.00091553, ..., -0.00073242, -0.00082397, -0.00054932]), sampling_rate: 16000}, transcription: yet he still thinks as swiftly as ever, speech_status: dysarthria, gender: male, duration: 7.605}
引用
- 如在出版物中使用此数据库,请至少引用以下论文之一:
- Rudzicz, F., Hirst, G., Van Lieshout, P. (2012) Vocal tract representation in the recognition of cerebral palsied speech. The Journal of Speech, Language, and Hearing Research, 55(4):1190-1207, August.
- Rudzicz, F., Namasivayam, A.K., Wolff, T. (2012) The TORGO database of acoustic and articulatory speech from speakers with dysarthria. Language Resources and Evaluation, 46(4), pages 523--541.
- Rudzicz, F.(2012) Using articulatory likelihoods in the recognition of dysarthric speech. Speech Communication, 54(3), March, pages 430--444.