miracl/miracl-corpus
收藏数据集卡片 for MIRACL Corpus
数据集描述
MIRACL(Multilingual Information Retrieval Across a Continuum of Languages)是一个多语言检索数据集,专注于18种不同语言的搜索,这些语言共同覆盖了全球超过30亿母语使用者。
该数据集包含16种“已知语言”的收集数据。其余2种“惊喜语言”将在稍后发布。
每个语言的语料库是从维基百科转储中准备的,我们只保留纯文本并丢弃图像、表格等。每个文章使用WikiExtractor根据自然论述单元(例如,`
`在维基标记中)分割成多个段落。每个段落构成一个“文档”或检索单元。我们保留每个段落的维基百科文章标题。
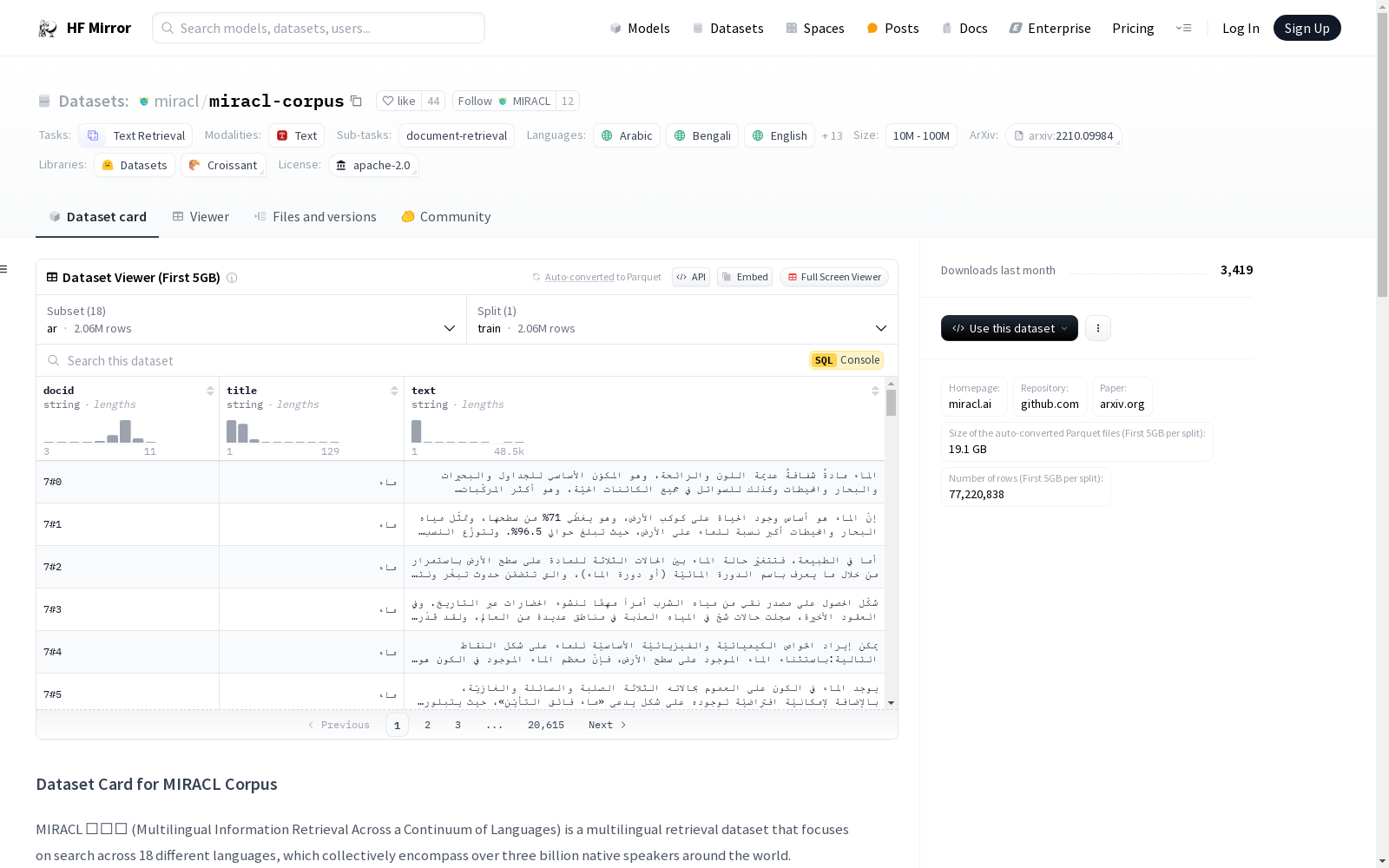
数据集结构
每个检索单元包含三个字段:docid、title和text。以下是一个来自英语语料库的示例:
json { "docid": "39#0", "title": "Albedo", "text": "Albedo (meaning whiteness) is the measure of the diffuse reflection of solar radiation out of the total solar radiation received by an astronomical body (e.g. a planet like Earth). It is dimensionless and measured on a scale from 0 (corresponding to a black body that absorbs all incident radiation) to 1 (corresponding to a body that reflects all incident radiation)." }
docid的格式为X#Y,其中所有具有相同X的段落来自同一篇维基百科文章,而Y表示该文章中的段落,按顺序编号。text字段包含段落的文本,title字段包含段落来源的文章名称。
可以使用以下代码加载集合:
python lang=ar # 或任何16种语言之一 miracl_corpus = datasets.load_dataset(miracl/miracl-corpus, lang)[train] for doc in miracl_corpus: docid = doc[docid] title = doc[title] text = doc[text]
数据集统计和链接
下表包含每个语言集合中的段落数量和维基百科文章数量,以及数据集和原始维基百科转储的链接。
| 语言 | 段落数量 | 文章数量 | 数据集链接 | 原始维基转储 |
|---|---|---|---|---|
| 阿拉伯语 (ar) | 2,061,414 | 656,982 | 🤗 | 🌏 |
| 孟加拉语 (bn) | 297,265 | 63,762 | 🤗 | 🌏 |
| 英语 (en) | 32,893,221 | 5,758,285 | 🤗 | 🌏 |
| 西班牙语 (es) | 10,373,953 | 1,669,181 | 🤗 | 🌏 |
| 波斯语 (fa) | 2,207,172 | 857,827 | 🤗 | 🌏 |
| 芬兰语 (fi) | 1,883,509 | 447,815 | 🤗 | 🌏 |
| 法语 (fr) | 14,636,953 | 2,325,608 | 🤗 | 🌏 |
| 印地语 (hi) | 506,264 | 148,107 | 🤗 | 🌏 |
| 印度尼西亚语 (id) | 1,446,315 | 446,330 | 🤗 | 🌏 |
| 日语 (ja) | 6,953,614 | 1,133,444 | 🤗 | 🌏 |
| 韩语 (ko) | 1,486,752 | 437,373 | 🤗 | 🌏 |
| 俄语 (ru) | 9,543,918 | 1,476,045 | 🤗 | 🌏 |
| 斯瓦希里语 (sw) | 131,924 | 47,793 | 🤗 | 🌏 |
| 泰卢固语 (te) | 518,079 | 66,353 | 🤗 | 🌏 |
| 泰语 (th) | 542,166 | 128,179 | 🤗 | 🌏 |
| 中文 (zh) | 4,934,368 | 1,246,389 | 🤗 | 🌏 |