ToddWayne113/cmu-arctic
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/ToddWayne113/cmu-arctic
下载链接
链接失效反馈官方服务:
资源简介:
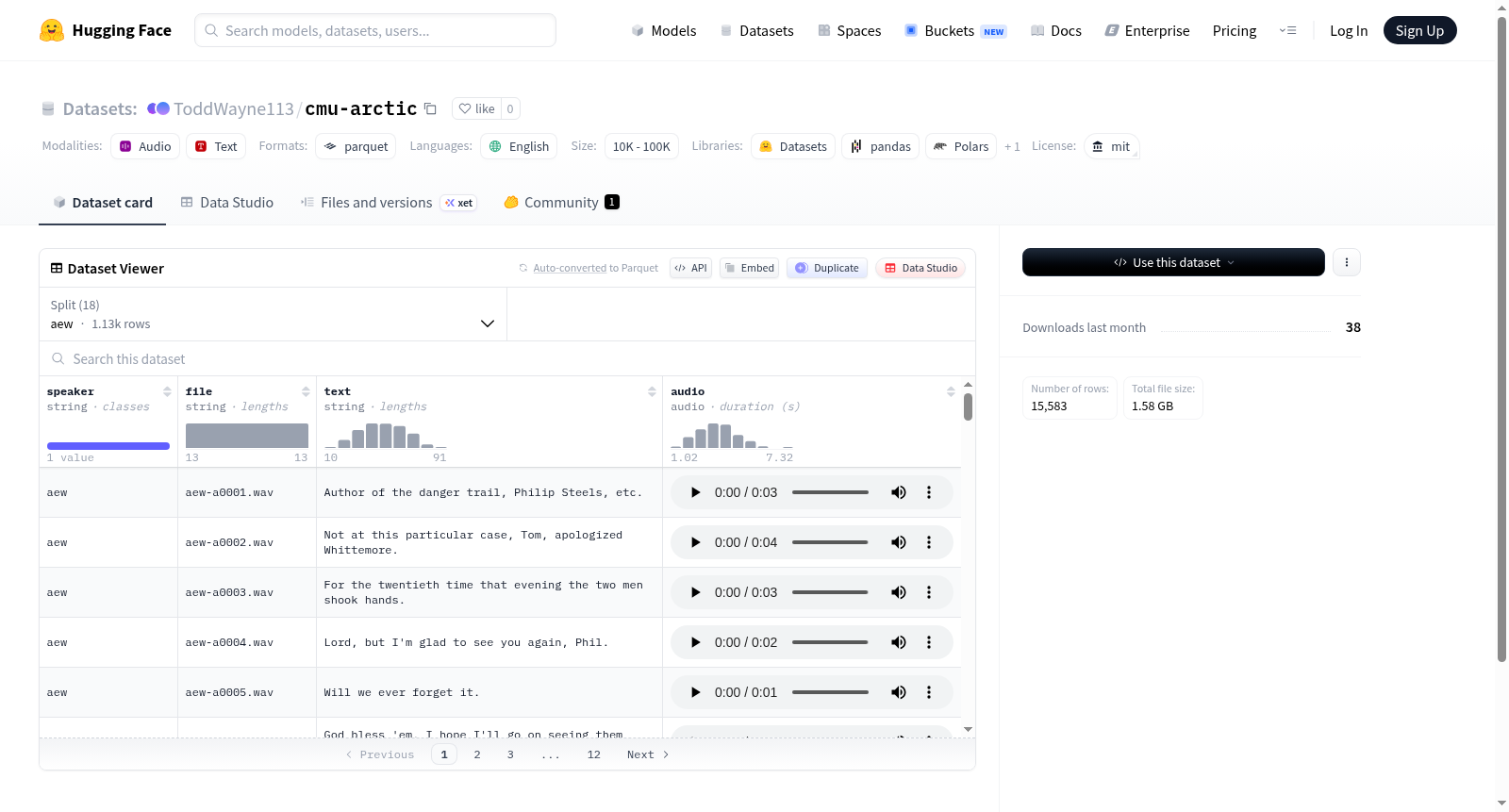
CMU Arctic是一个语音数据集,包含多种说话者的音频文件及其对应文本。数据集包含多个说话者(如aew、ahw等)的录音,每个录音有对应的文本内容,音频采样率为16000Hz。数据集总大小约为1.6GB,包含超过10,000个样本。
The CMU Arctic dataset is a speech dataset containing audio files and their corresponding texts from multiple speakers. The dataset includes recordings from various speakers (e.g., aew, ahw, etc.), each with associated text content, and the audio sampling rate is 16,000 Hz. The total dataset size is approximately 1.6GB, containing over 10,000 samples.
提供机构:
ToddWayne113
搜集汇总
数据集介绍
构建方式
CMU Arctic数据集是一个专为语音合成研究设计的英文语音数据集,由卡内基梅隆大学发布。该数据集采集了18位不同口音与音色的发音人朗读的短句音频,每位发音人包含约593至1132条录音不等,总计超过15000条。每条样本均提供对应的文本转录与16kHz采样率的音频文件。数据被按发音人标识划分为多个独立子集,如bdl、slt等,便于研究者针对特定声学特征进行建模或跨说话人风格迁移研究。
使用方法
在HuggingFace平台上,用户可通过`datasets`库直接加载CMU Arctic数据集。只需调用`load_dataset`函数并指定数据集名称,即可访问各发音人子集。返回的每条记录包含音频数组、采样率、对应文本及说话人标签。研究者可按需选择单个子集进行单说话人训练,或合并多个子集以构建多说话人模型。音频字段兼容常见的深度学习框架,结合`transformers`或`torchaudio`等工具,能够便捷地完成声学特征提取、文本对齐等下游任务开发。
背景与挑战
背景概述
CMU Arctic数据集由卡内基梅隆大学于2003年创建,旨在为语音合成研究提供高质量的声学数据。该数据集聚焦于单元选择和统计参数语音合成领域,收录了18位英语母语者(包含不同性别与年龄)朗读的短篇故事与新闻片段,共计超过1.6GB的16kHz单声道音频。作为语音合成领域的经典基准资源,CMU Arctic不仅推动了基于非参数模型的语音生成技术发展,还为后续的深度学习语音合成研究奠定了数据基础。其影响力体现在被广泛应用于声学模型训练、音素对齐及说话人适应性研究的验证中,成为评估合成语音自然度与可懂度的黄金标准之一。
当前挑战
当前CMU Arctic面临的核心挑战在于多层级语音合成任务的适配性瓶颈。首先,数据集的音素覆盖存在地域性局限,主要为美式英语发音,难以满足多口音、多语种通用合成系统的需求,限制了其在全球化语音交互场景中的泛化能力。其次,构建过程中录音环境的非标准性(如背景噪声与麦克风差异)与文本长度分布不均(部分说话人仅有593条样本)导致模型在学习韵律特征时易产生过拟合。此外,标注粒度的不一致性——仅提供文本对齐而无精细的音素时长或语调标记——增加了跨任务迁移的难度,尤其是在端到端语音合成模型需学习边界模糊的声学映射关系时,数据集对音素间协同发音的建模支持不足,成为提升合成质量的关键障碍。
常用场景
经典使用场景
CMU Arctic数据集作为语音合成领域的经典资源,常被用于构建和评估文本到语音(TTS)系统。研究者借助其中包含的数十位母语者的高质量录音及其对应的文本标注,能够训练出具备自然韵律与清晰发音的声学模型。该数据集特别适合用于单说话人或多说话人语音合成的研究,通过不同说话人的语料,可以探索语音个性与音色迁移的技术路径。其标准化的16kHz采样率和简洁的文本-音频对齐格式,为快速搭建基准系统提供了便利。
解决学术问题
该数据集的发布有效解决了语音合成研究中高质量、多说话人语料匮乏的困境。它使得研究者能够在受控条件下系统性地探索说话人自适应、语音风格迁移以及低资源语音合成等学术难题。基于CMU Arctic,学界得以深入分析音素持续时间、基频轮廓与情感表达之间的精细关联,从而推动从参数化合成到端到端合成范式的演进。其对语音韵律机制建模的贡献,为生成更加自然流畅的合成语音奠定了数据基础。
实际应用
在实际应用中,CMU Arctic数据集支撑了多种辅助技术与交互系统的开发。它常被用于训练语音助手、电子阅读器及导航系统中的核心语音合成模块,使机器能够以清晰且富有表现力的方式朗读文本。此外,在无障碍技术领域,它为视障人士使用的屏幕阅读器提供了高质量的语音输出基础。同时,该数据集也被纳入语音克隆与个性化语音定制服务的技术验证流程中,助力于打造更加人性化的人机交互体验。
数据集最近研究
最新研究方向
CMU Arctic数据集作为语音合成领域经典的高质量单说话人多风格语音库,当前正驱动着情感语音合成与零样本语音克隆的前沿探索。研究者利用其多说话人(如bdl、slt等18个发音人)的丰富标注数据,结合扩散模型与变分自编码器,突破传统参数合成在韵律多样性上的瓶颈。该数据集在基于离散编码的语音表示学习、跨说话人音色迁移等热点议题中扮演基准角色,其开放的MIT许可协议更催化了低资源语音合成系统的公平性评估,对推动个性化语音助手与有声内容生成技术的发展具有深远意义。
以上内容由遇见数据集搜集并总结生成


