NERsocial
收藏NERsocial: 面向人机交互的高效命名实体识别数据集
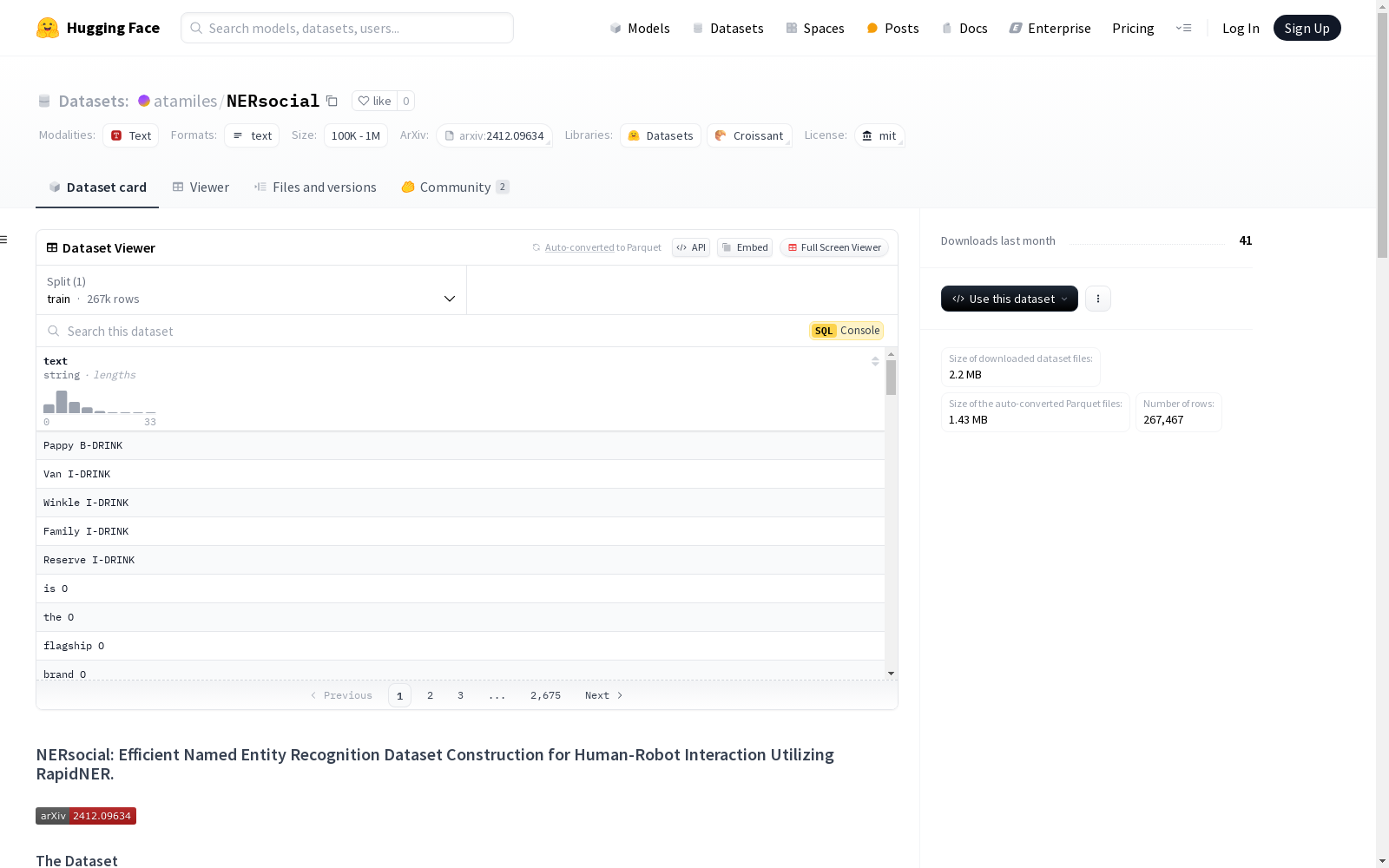
数据集概述
NERsocial 是一个专门为人机交互(HRI)应用设计的命名实体识别(NER)数据集。该数据集包含99,448条句子,153,102个实体标记,以及134,074个实体,涵盖以下六种实体类型:
- 饮品(drinks)
- 食物(foods)
- 爱好(hobbies)
- 职业(jobs)
- 宠物(pets)
- 运动(sports)
此外,数据集通过重新标注 CoNLL2003 数据集,增加了三种新的实体类型:
- 人名(PEOPLENAME)
- 国家(COUNTRY)
- 组织(ORGANIZATION)
数据集构建
NERsocial 数据集利用了 RapidNER 框架,结合了从 Wikidata 提取的知识图谱和从 Wikipedia、Reddit 以及 Stack Exchange 等多个来源收集的文本。数据集的构建过程创新且高效,使用 Elasticsearch 进行快速标注,将每句话的标注时间从1分钟缩短到0.9毫秒。
数据格式
数据集以字典形式存储,包含两个主要字段:
tokens:句子中的词汇列表。tags:每个词汇对应的实体标签。
标签与ID的映射关系如下:
label2id:标签到ID的映射。id2label:ID到标签的映射。
使用许可
数据集基于 MIT 许可证 发布,允许在研究之外的用途使用。
引用
如果使用该数据集,请引用以下内容:
@misc{atuhurra2024nersocialefficientnamedentity, title={NERsocial: Efficient Named Entity Recognition Dataset Construction for Human-Robot Interaction Utilizing RapidNER}, author={Jesse Atuhurra and Hidetaka Kamigaito and Hiroki Ouchi and Hiroyuki Shindo and Taro Watanabe}, year={2024}, eprint={2412.09634}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2412.09634}, }