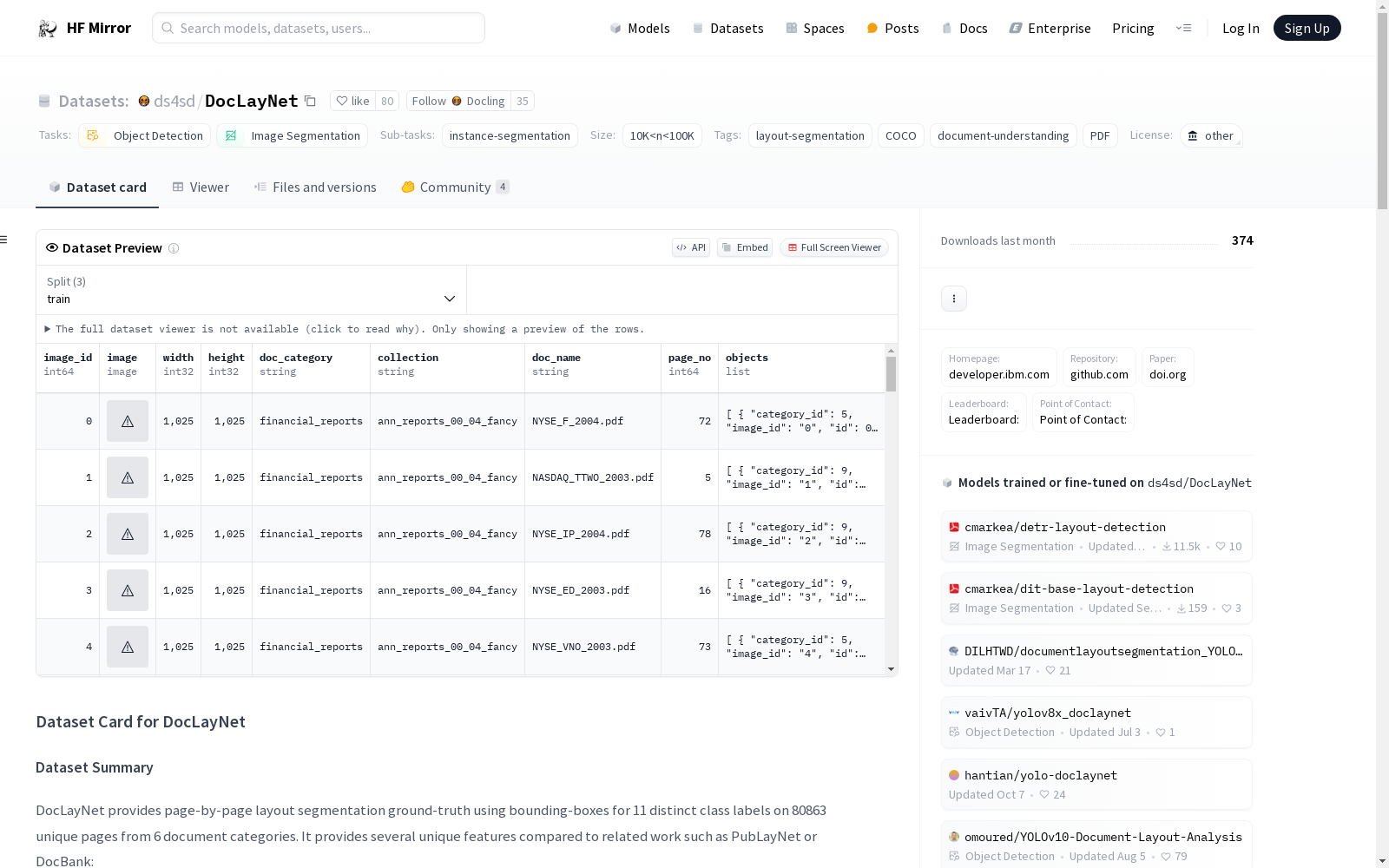
ds4sd/DocLayNet
收藏数据集卡片 for DocLayNet
数据集描述
数据集概述
DocLayNet 提供了 80863 个独特页面的页面布局分割地面实况,使用边界框为 11 个不同的类别标签。它与 PubLayNet 或 DocBank 等现有工作相比具有以下独特特点:
- 人工标注:DocLayNet 由训练有素的专家手工标注,通过人类识别和解释每个页面布局,提供布局分割的金标准。
- 布局多样性:DocLayNet 包括来自金融、科学、专利、招标、法律文本和手册等多个公共来源的多样化和复杂布局。
- 详细的标签集:DocLayNet 定义了 11 个类别标签,以高细节区分布局特征。
- 冗余标注:DocLayNet 中的一部分页面进行了双重或三重标注,允许估计标注不确定性和机器学习模型可达到的预测准确性的上限。
- 预定义的训练、测试和验证集:DocLayNet 提供了固定的集合,以确保类别标签的比例表示,并避免独特布局风格在集合之间的泄露。
支持的任务和排行榜
我们将在 ICDAR 2023 上基于 DocLayNet 数据集举办竞赛。更多信息请参见 https://ds4sd.github.io/icdar23-doclaynet/。
数据集结构
数据字段
DocLayNet 提供了四种数据资产:
- 所有页面的 PNG 图像,调整为
1025 x 1025px的正方形。 - 每个 PNG 图像的 COCO 格式边界框标注。
- 额外的:与每个 PNG 图像匹配的单页 PDF 文件。
- 额外的:与每个 PDF 页面匹配的 JSON 文件,提供带有坐标和内容的数字文本单元格。
COCO 图像记录定义如下示例:
js { "id": 1, "width": 1025, "height": 1025, "file_name": "132a855ee8b23533d8ae69af0049c038171a06ddfcac892c3c6d7e6b4091c642.png", "doc_category": "financial_reports", "collection": "ann_reports_00_04_fancy", "doc_name": "NASDAQ_FFIN_2002.pdf", "page_no": 9, "precedence": 0 }
doc_category 字段使用以下常量之一:
financial_reports, scientific_articles, laws_and_regulations, government_tenders, manuals, patents
数据分割
数据集提供了三个分割:
trainvaltest
数据集创建
标注
标注过程
用于训练标注专家的标注指南可在 DocLayNet_Labeling_Guide_Public.pdf 获取。
标注者
标注是众包的。
附加信息
数据集策展人
数据集由 IBM Research 的 Deep Search 团队 策展。
策展人:
- Christoph Auer, @cau-git
- Michele Dolfi, @dolfim-ibm
- Ahmed Nassar, @nassarofficial
- Peter Staar, @PeterStaar-IBM
许可信息
引用信息
bib @article{doclaynet2022, title = {DocLayNet: A Large Human-Annotated Dataset for Document-Layout Segmentation}, doi = {10.1145/3534678.353904}, url = {https://doi.org/10.1145/3534678.3539043}, author = {Pfitzmann, Birgit and Auer, Christoph and Dolfi, Michele and Nassar, Ahmed S and Staar, Peter W J}, year = {2022}, isbn = {9781450393850}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, booktitle = {Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining}, pages = {3743–3751}, numpages = {9}, location = {Washington DC, USA}, series = {KDD 22} }
贡献
感谢 @dolfim-ibm, @cau-git 添加此数据集。