KenLuo/EMPEC
收藏Hugging Face2024-06-04 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/KenLuo/EMPEC
下载链接
链接失效反馈官方服务:
资源简介:
EMPEC(中文医疗人员考试)数据集收集了过去10年中华民国医疗人员专业与技术考试的多项选择题。该数据集涵盖了多种医疗专业,如医学技术师、医学放射技术师、注册专业护士、物理治疗师等,总共包含81761道单选题,涉及广泛的学科,包括一般临床心理学、解剖学和生理学、呼吸护理基础、职业治疗技术等。EMPEC为AI模型提供了一个显著的挑战,并可以作为评估模型在中文医疗知识方面的有效工具。
EMPEC(中文医疗人员考试)数据集收集了过去10年中华民国医疗人员专业与技术考试的多项选择题。该数据集涵盖了多种医疗专业,如医学技术师、医学放射技术师、注册专业护士、物理治疗师等,总共包含81761道单选题,涉及广泛的学科,包括一般临床心理学、解剖学和生理学、呼吸护理基础、职业治疗技术等。EMPEC为AI模型提供了一个显著的挑战,并可以作为评估模型在中文医疗知识方面的有效工具。
提供机构:
KenLuo
原始信息汇总
数据集概述
数据集名称
EMPEC (Examinations for Medical PErsonnel in Chinese)
数据集描述
EMPEC收集了中华民国近10年的医疗人员专业技术考试的多项选择题。涵盖了包括医学技术师、医学放射技术师、注册专业护士、物理治疗师等在内的多种医疗专业人员考试。总共包含81761道单项选择题,涉及广泛的科目,如普通临床心理学、解剖生理学、呼吸护理基础、职业治疗技术等。
数据集用途
EMPEC对AI模型构成显著挑战,可作为评估模型医疗知识(以中文编码)的有效工具。旨在支持大型多语言或中文语言模型(特别是在医疗领域)的探索和构建。
数据文件结构
- 配置名称: default
- 训练集: train.jsonl
- 验证集: dev.jsonl
- 测试集: test_8k.jsonl
许可证
cc-by-nc-nd-4.0
引用信息
@misc{EMPEC, title={EMPEC, Examinations-for-Medical-PErsonnel-in-Chinese}, author={Zheheng Luo}, year = {2024}, publisher = {GitHub}, journal = {GitHub repository}, howpublished = {url{https://github.com/zhehengluoK/Examinations-for-Medical-PErsonnel-in-Chinese}}, }
搜集汇总
数据集介绍
构建方式
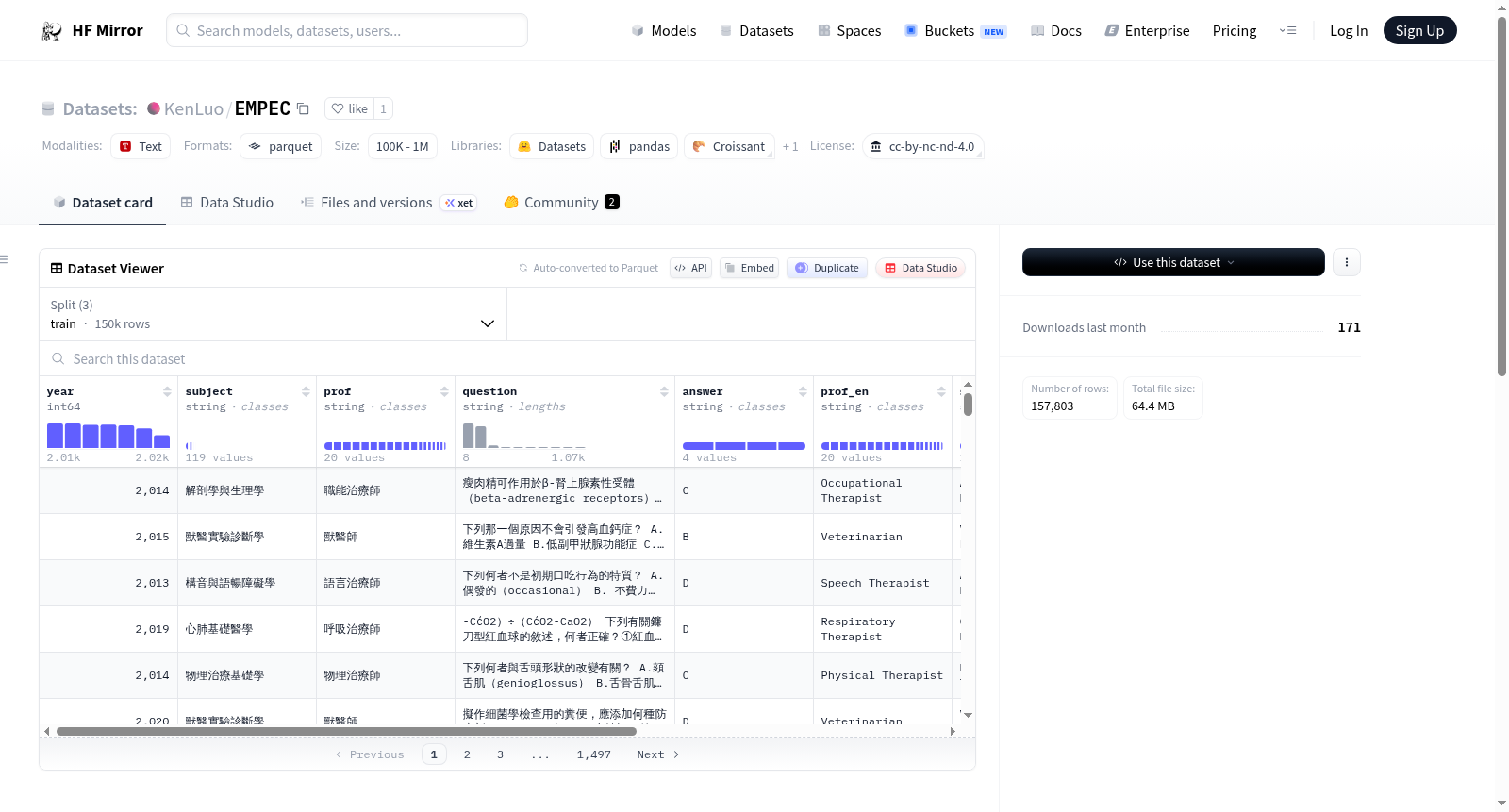
EMPEC(Examinations for Medical PErsonnel in Chinese)数据集源自台湾考选部近十年举办的医事人员专业技术人员考试,系统收集了涵盖医事检验师、医事放射师、护理师、物理治疗师等多元医疗职业类别的单选题。数据集中共包含81761道题目,每道题目均附有年份、科目、专业领域、问题、答案及中英文对照信息。为便于多语言处理,数据集还提供了简体中文和英文版本的问题。数据划分为训练集(149603条)、验证集(200条)和测试集(8000条),以支持模型训练与评估。
特点
该数据集具有鲜明的领域专业性与语言多样性特征。题目覆盖临床心理学、解剖生理学、呼吸照护基础、职能治疗技术等广泛医学学科,构成了对人工智能模型在中文医学知识理解上的严峻挑战。每条数据包含原始中文问题与答案、英文专业术语、简体中文版本,便于跨语言研究。数据集规模适中,结构清晰,既可用于评估模型在中文医学领域的知识储备,也可作为多语言或中文大语言模型在医疗场景下的基准测试工具。
使用方法
使用者可通过HuggingFace Datasets库直接加载该数据集,指定配置名称为'default',并选择训练、验证或测试分割。数据以JSON格式存储,字段包括year、subject、prof、question、answer等,便于按需筛选与解析。适用于监督学习中的多项选择问答任务,可配合预训练语言模型进行微调或零样本评估。建议研究者结合中文医学知识库进行交叉验证,以全面考察模型在专业医疗语境下的推理能力。
背景与挑战
背景概述
在自然语言处理与医学人工智能交叉领域,高质量的中文医学知识评测数据集长期匮乏,制约了中文大语言模型在医疗场景下的能力验证与优化。EMPEC(Examinations for Medical PErsonnel in Chinese)数据集由研究者Zheheng Luo于2024年创建,源自中国台湾考选部近十年医学专业人员专业技术考试的多选题,涵盖医检师、放射师、护理师、物理治疗师等十余类职业资格考试,涉及临床心理学、解剖生理学、呼吸照护基础及职能治疗技术等广泛学科。该数据集包含81761道单选题,划分为训练集149603条、验证集200条、测试集8000条,以年份、科目、题目、答案等结构化字段存储,旨在为评估模型的中文医学知识掌握程度提供标准化基准,对推动多语言及中文大模型在医疗领域的纵深研究具有重要影响力。
当前挑战
EMPEC所解决的领域问题在于为中文医学知识推理提供高难度评测基准,现有模型在处理专业术语密集、逻辑严谨的医学选择题时,常因语义歧义或跨学科知识整合不足而表现欠佳。构建过程中面临多重挑战:首先,原始试题来源于官方考试机构,需严格遵循版权声明(cc-by-nc-nd-4.0)进行非商业性使用,且数据完整性不可随意增删;其次,数据需经清洗与结构化处理,将繁体中文试题转换为简体中文及英文版本(如question_simp与question_eng字段),同时保留专业术语的准确性;此外,多职业类别(prof字段)与多学科(subject字段)的交叉分类增加了标签体系设计的复杂度,需确保训练-验证-测试分片在学科分布上保持均衡,以规避模型对高频类别的过拟合风险。
常用场景
经典使用场景
EMPEC(中文医务人员考试)数据集汇聚了来自台湾考选部近十年医学专业人员资格考试中的八万余道单选题,覆盖临床心理学、解剖生理学、呼吸治疗基础等广泛医学学科。其经典使用场景在于作为大规模中文医学知识评估基准,通过多领域、多层次的题目结构,系统性地检验人工智能模型在中文语境下对医学知识的掌握深度与推理能力。研究者可借助该数据集开展模型在专业术语理解、临床逻辑判断及跨学科知识整合方面的能力测试,从而精准定位模型在医学认知中的薄弱环节。
解决学术问题
该数据集核心解决了当前中文医学自然语言处理研究中缺乏高质量、大规模、结构化评估资源的困境。EMPEC通过提供包含题目、答案及学科标注的标准化测试集,使学术界能够量化比较不同预训练语言模型、大型语言模型在中文医学知识问答上的表现差异。它填补了现有英文医学基准如MedQA在中文场景下的空白,推动了多语言医学AI评测体系的构建,为评估模型在低资源语言中的医学编码能力提供了关键工具,进而促进跨语言医学知识迁移研究的深入发展。
衍生相关工作
EMPEC的发布催生了多项衍生研究,其中最经典的工作包括将其作为中文医学大语言模型评估榜单的核心组成部分,例如在CMB(Chinese Medical Benchmark)等综合基准中引入EMPEC子集以细化评测维度。此外,研究者基于该数据集开发了医学知识蒸馏方法,通过对比模型在不同学科上的错误模式来优化训练策略;也有工作利用EMPEC的跨学科特性,构建了医学概念关联图谱,用于增强模型的推理可解释性。这些衍生工作进一步拓展了EMPEC在模型鲁棒性分析、学科特异性知识增强等前沿方向的应用价值。
以上内容由遇见数据集搜集并总结生成


