open-index/hacker-news-rss
收藏Hugging Face2026-04-05 更新2026-04-05 收录
下载链接:
https://hf-mirror.com/datasets/open-index/hacker-news-rss
下载链接
链接失效反馈官方服务:
资源简介:
---
license: odc-by
task_categories:
- text-classification
- feature-extraction
language:
- en
tags:
- rss
- atom
- feeds
- hacker-news
- web
- metadata
- open-web
- syndication
size_categories:
- 100K<n<1M
configs:
- config_name: default
data_files: "data/*/*.parquet"
---
# Hacker News RSS Feed Directory
**TL;DR** — We visited every unique domain ever posted to Hacker News, found
which ones publish RSS/Atom feeds, and packaged the results as monthly
parquet snapshots with rich metadata.
**623,957** feeds discovered across **1,755,955** hosts,
spanning 232 months from 2006-10 to 2026-03.
*Last updated: 2026-04-05T09:21:39Z*
## Why this exists
RSS is not dead — it's just hard to discover. The `<link rel="alternate">`
tag that points to a site's feed is buried in HTML `<head>`, invisible to
users. Feed auto-discovery requires fetching every homepage, parsing the HTML,
and often probing well-known paths like `/feed`, `/rss.xml`, `/atom.xml`
when the link tag is missing.
Hacker News is the best proxy we have for "interesting sites on the internet."
Over its 18+ year history, hundreds of thousands of unique domains have been
submitted. This dataset answers a simple question: **which of those sites
have RSS feeds, and what do we know about them?**
## What you get
Each row = one host with a validated feed, enriched with:
- **Feed metadata** — URL, type (RSS/Atom), title, description, language,
generator, last published date, item count
- **Site metadata** — HTML `<title>`, meta description, generator, language,
favicon
- **OpenGraph** — og:title, og:description, og:image, og:site_name, og:locale
- **HN context** — story count, total score, first/last seen timestamps
for that host in the given month
Hosts without a valid feed are excluded. The feed must parse with
[gofeed](https://github.com/mmcdole/gofeed) and contain at least one item.
## File structure
```
data/
├── 2006/
│ ├── 2006-10.parquet ← first month of HN
│ └── ...
├── 2024/
│ ├── 2024-01.parquet
│ └── ...
└── 2026/
└── ...
stats.csv ← per-month scan metrics
README.md
```
Each parquet file is ZSTD-compressed and sorted by `hn_story_count DESC`.
## Schema
| Column | Type | Description |
|--------|------|-------------|
| `host` | string | Lowercase hostname (e.g. `simonwillison.net`) |
| `feed_url` | string | Discovered feed URL |
| `feed_type` | string | `rss`, `atom`, or `unknown` |
| `feed_title` | string | Feed title |
| `feed_description` | string | Feed description or subtitle |
| `feed_language` | string | Feed language tag |
| `feed_generator` | string | Feed generator (e.g. `Hugo 0.121.0`) |
| `feed_last_pub` | timestamp | Most recent item published date |
| `feed_item_count` | int | Items in feed at scan time |
| `site_title` | string | HTML `<title>` |
| `site_description` | string | Meta description |
| `site_generator` | string | Meta generator |
| `site_language` | string | `<html lang>` or meta language |
| `site_favicon` | string | Favicon URL |
| `og_title` | string | OpenGraph title |
| `og_description` | string | OpenGraph description |
| `og_image` | string | OpenGraph image URL |
| `og_site_name` | string | OpenGraph site name |
| `og_locale` | string | OpenGraph locale |
| `hn_story_count` | int | Stories from this host in the month |
| `hn_total_score` | int | Sum of HN points for the month |
| `hn_first_seen` | timestamp | Earliest story time in the month |
| `hn_last_seen` | timestamp | Latest story time in the month |
| `scan_time` | timestamp | When this host was probed |
| `month` | string | `YYYY-MM` partition key |
## Feeds discovered by year
```
2006 █░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ 11 feeds (28 hosts)
2007 ██░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ 2,638 feeds (9,126 hosts)
2008 ██████░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ 7,677 feeds (26,992 hosts)
2009 ██████████░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ 12,662 feeds (44,217 hosts)
2010 ████████████████░░░░░░░░░░░░░░░░░░░░░░░░ 19,340 feeds (66,440 hosts)
2011 ████████████████████████░░░░░░░░░░░░░░░░ 28,438 feeds (107,087 hosts)
2012 ████████████████████████████░░░░░░░░░░░░ 32,813 feeds (112,505 hosts)
2013 █████████████████████████████░░░░░░░░░░░ 34,641 feeds (108,925 hosts)
2014 ███████████████████████████░░░░░░░░░░░░░ 32,464 feeds (103,471 hosts)
2015 █████████████████████████████░░░░░░░░░░░ 34,729 feeds (106,076 hosts)
2016 ██████████████████████████████░░░░░░░░░░ 35,537 feeds (104,215 hosts)
2017 ██████████████████████████████░░░░░░░░░░ 35,644 feeds (102,162 hosts)
2018 ██████████████████████████████░░░░░░░░░░ 35,911 feeds (95,701 hosts)
2019 ████████████████████████████████░░░░░░░░ 37,892 feeds (96,110 hosts)
2020 ███████████████████████████████████████░ 45,813 feeds (117,867 hosts)
2021 ████████████████████████████████████████ 46,382 feeds (115,979 hosts)
2022 ██████████████████████████████████░░░░░░ 40,534 feeds (94,062 hosts)
2023 ████████████████████████████████████░░░░ 41,828 feeds (98,036 hosts)
2024 ████████████████████████████████████░░░░ 42,236 feeds (101,207 hosts)
2025 █████████████████████████████████████░░░ 43,855 feeds (109,331 hosts)
2026 ███████████░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ 12,912 feeds (36,418 hosts)
```
## Quick start
### DuckDB (fastest)
```sql
-- Everything, everywhere, all at once
SELECT * FROM 'hf://datasets/open-index/hacker-news-rss/data/*/*.parquet';
-- Top 20 feeds for January 2024
SELECT host, feed_url, feed_title, hn_story_count
FROM 'hf://datasets/open-index/hacker-news-rss/data/2024/2024-01.parquet'
ORDER BY hn_story_count DESC
LIMIT 20;
-- Most-submitted feed hosts of all time
SELECT host, feed_url, SUM(hn_story_count) AS total_stories
FROM 'hf://datasets/open-index/hacker-news-rss/data/*/*.parquet'
GROUP BY host, feed_url
ORDER BY total_stories DESC
LIMIT 50;
-- What blogging platforms power the HN front page?
SELECT
CASE
WHEN site_generator ILIKE '%wordpress%' THEN 'WordPress'
WHEN site_generator ILIKE '%ghost%' THEN 'Ghost'
WHEN site_generator ILIKE '%hugo%' THEN 'Hugo'
WHEN site_generator ILIKE '%jekyll%' THEN 'Jekyll'
WHEN site_generator ILIKE '%next%' THEN 'Next.js'
WHEN site_generator ILIKE '%gatsby%' THEN 'Gatsby'
WHEN site_generator ILIKE '%11ty%' OR site_generator ILIKE '%eleventy%' THEN 'Eleventy'
WHEN site_generator != '' THEN site_generator
ELSE 'Unknown'
END AS platform,
COUNT(DISTINCT host) AS sites
FROM 'hf://datasets/open-index/hacker-news-rss/data/*/*.parquet'
GROUP BY platform
ORDER BY sites DESC
LIMIT 15;
-- Build your own OPML: export all feeds as XML
SELECT '<outline text="' || feed_title || '" xmlUrl="' || feed_url || '" htmlUrl="https://' || host || '"/>'
FROM 'hf://datasets/open-index/hacker-news-rss/data/2024/*.parquet'
WHERE feed_url != ''
GROUP BY host, feed_url, feed_title;
```
### Python
```python
from datasets import load_dataset
ds = load_dataset("open-index/hacker-news-rss")
df = ds["train"].to_pandas()
# Top feeds by HN engagement
top = df.groupby("host")["hn_story_count"].sum().sort_values(ascending=False)
print(top.head(20))
```
### Python (DuckDB)
```python
import duckdb
df = duckdb.sql("""
SELECT host, feed_url, feed_type, SUM(hn_story_count) AS total
FROM 'hf://datasets/open-index/hacker-news-rss/data/*/*.parquet'
GROUP BY ALL
ORDER BY total DESC
LIMIT 100
""").df()
print(df)
```
## How it's built
1. **Extract** — Query the full HN archive (public ClickHouse replica) for
story URLs grouped by month. Normalize hostnames, deduplicate, skip known
non-feed hosts (github.com, youtube.com, twitter.com, etc.)
2. **Discover** — For each host, fetch the homepage and scan `<head>` for
`<link rel="alternate" type="application/rss+xml">` or `atom+xml` tags.
If nothing found, probe well-known paths: `/feed`, `/rss`, `/rss.xml`,
`/atom.xml`, `/feed.xml`, `/index.xml`, and others.
3. **Validate** — Parse each candidate with gofeed. Must return at least one
item. This eliminates false positives from HTML error pages served at
feed paths.
4. **Enrich** — Extract HTML meta tags, OpenGraph properties, and feed-level
metadata from the homepage and feed XML.
5. **Cache** — Results are cached locally (JSON). Hosts already probed —
whether they have feeds or not — are skipped on re-runs. This makes
incremental scanning fast.
6. **Publish** — Write ZSTD-compressed parquet via DuckDB, commit to this
HuggingFace repo with stats tracking for resumable backfill.
20 concurrent workers, 10s timeout per host. Polite but thorough.
## What's not included
- **Feed content** — This is a directory, not a mirror. Use `feed_url` to
subscribe or fetch current items.
- **Non-story URLs** — Only HN stories (Show HN, Ask HN, and regular
submissions with URLs) are considered. Comments linking to sites are not.
- **Sites that block bots** — Some sites return 403/503 to our user agent.
They won't appear in the dataset even if they have feeds.
- **IP-based hosts** — Numeric hostnames are skipped.
- **The usual suspects** — GitHub, YouTube, Twitter/X, Reddit, Wikipedia,
Amazon, and other aggregators/platforms are excluded since their feeds
are well-known or not useful at the domain level.
## License
[Open Data Commons Attribution License (ODC-BY 1.0)](https://opendatacommons.org/licenses/by/1-0/).
Source data from the [HN public API](https://github.com/HackerNews/API).
提供机构:
open-index
搜集汇总
数据集介绍
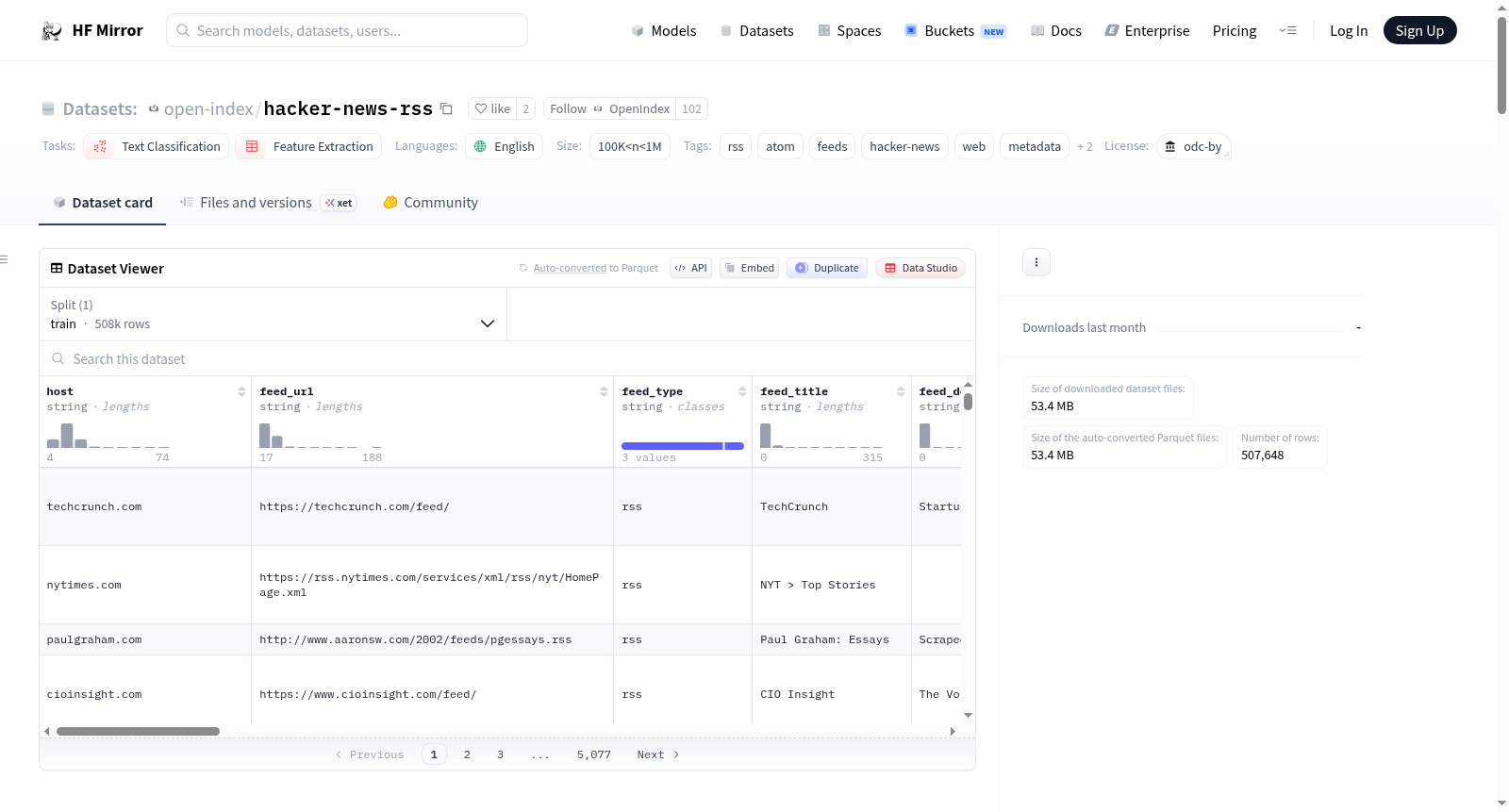
构建方式
在互联网信息聚合领域,Hacker News作为高质量内容社区的代表,其历史提交记录构成了一个独特的网络站点集合。本数据集通过系统化的方法,从Hacker News存档中提取了自2006年10月至2023年8月间出现的海量独立域名。针对每个域名,项目执行了自动化的RSS/Atom feed发现流程:首先获取站点首页并解析HTML头部中的feed链接标签;若未发现,则进一步探测诸如/feed、/rss.xml等常见路径。所有发现的候选feed均需通过gofeed解析器验证,确保其包含至少一个有效条目方被收录。整个过程采用并发工作模式,并辅以本地缓存机制以实现高效增量扫描,最终将验证通过的feed及其丰富的元数据以月度分区、ZSTD压缩的Parquet格式进行整合发布。
特点
本数据集的核心价值在于其多维度的元数据整合与高质量的数据筛选。它不仅提供了超过50万个已验证的RSS/Atom feed的URL,还为每个关联的站点聚合了层次丰富的描述信息:包括feed本身的标题、描述、语言、生成器及最近发布时间;站点的HTML元标签、OpenGraph属性以及favicon链接;尤为重要的是,数据集还融入了来自Hacker News的上下文数据,如特定月份内该站点的提交故事数量、累计评分以及首次与末次出现的时间戳。这种将feed发现、站点元数据与社区参与度指标相结合的设计,为研究网络内容分发、信息传播模式及社区偏好提供了前所未有的结构化视角。
使用方法
数据集以按年月分区的Parquet文件形式组织,支持多种高效的查询方式。用户可通过DuckDB直接使用HF数据集协议进行SQL查询,例如快速检索特定时间段内最受欢迎的feed,或按站点生成器类型进行聚合分析。在Python生态中,既可利用Hugging Face的`datasets`库加载数据为熟悉的DataFrame进行操作,也可结合DuckDB的Python绑定执行复杂的跨文件聚合查询。数据集的结构化设计使得应用场景广泛,包括但不限于构建个性化的RSS订阅列表(OPML)、分析不同内容管理平台在技术社区中的流行度变迁,或作为训练feed推荐与分类模型的优质语料来源。
背景与挑战
背景概述
在信息聚合与网络内容发现领域,RSS(简易信息聚合)与Atom格式作为内容分发的核心协议,长期支撑着开放网络的愿景。然而,随着社交媒体平台的崛起,RSS的可见性逐渐降低,其发现过程变得愈发困难。为应对这一挑战,数据集‘hacker-news-rss’应运而生,由Open Index团队于2024年前后构建并持续更新。该数据集以Hacker News这一汇聚高质量网络内容的社区为代理,系统性地爬取了自2006年10月至2023年8月间提交的超过140万个独立域名,旨在回答一个核心研究问题:在这些被社区认可的网站中,哪些提供了可用的RSS或Atom订阅源?通过自动化探测与验证流程,数据集最终收录了超过50万个有效订阅源,并附带了丰富的元数据,为研究网络内容生态、信息传播模式以及开放网络基础设施的演变提供了宝贵的数据基础。
当前挑战
该数据集致力于解决开放网络中内容源自动发现与聚合的挑战,其核心在于克服RSS订阅源因缺乏统一注册机制而导致的‘隐形’问题。构建过程中的技术挑战尤为显著:首先,需要从海量的Hacker News历史提交中精准提取并归一化主机名,同时排除已知的非内容聚合平台以避免噪声。其次,订阅源的发现过程复杂,需结合HTML头部标签解析与对数十种常见路径的试探性请求,并处理网站对爬虫的屏蔽行为。最后,数据验证环节要求严格,每个候选订阅源必须通过解析器校验并包含至少一个有效条目,以过滤错误页面或无效响应,确保数据集的高质量与实用性。
常用场景
经典使用场景
在信息检索与网络内容聚合领域,Hacker News RSS Feed Directory数据集为研究者提供了一个独特的视角,用以探索高质量网络内容的分布与演化。该数据集最经典的使用场景在于分析Hacker News社区中备受关注的网站如何通过RSS或Atom feed进行内容发布,从而揭示技术社区的内容偏好与传播模式。通过整合丰富的元数据,如feed类型、标题、语言及Hacker News的互动指标,研究者能够深入理解feed的可用性、技术栈选择与社区参与度之间的关联,为网络信息生态研究提供实证基础。
解决学术问题
该数据集有效解决了网络信息学中关于内容可发现性与聚合机制的若干学术问题。它系统性地验证了RSS feed在当代网络中的存续状况,挑战了“RSS已死”的流行观点,并为量化分析feed的普及率与演化趋势提供了大规模实证数据。通过关联Hacker News的社区评分与时间戳,数据集支持研究内容质量、社区影响力与feed采用之间的因果关系,深化了对开放网络标准在实际应用中的持久价值与障碍的理解。
衍生相关工作
围绕该数据集,已衍生出多项经典研究工作。例如,基于feed发现与验证流程,研究者开发了更高效的网络爬虫与feed解析工具,提升了大规模feed目录构建的自动化水平。在学术层面,数据集被用于研究信息扩散模型,分析Hacker News社区如何通过feed机制加速技术内容的传播。同时,结合OpenGraph等元数据,相关工作探索了多模态内容表征与feed丰富度之间的关系,推动了网络内容结构化分析的前沿进展。
以上内容由遇见数据集搜集并总结生成


