fineweb-edu-fortified
收藏魔搭社区2026-01-09 更新2024-11-23 收录
下载链接:
https://modelscope.cn/datasets/AI-ModelScope/fineweb-edu-fortified
下载链接
链接失效反馈官方服务:
资源简介:
# Fineweb-Edu-Fortified
<figure>
<img src="https://cdn-uploads.huggingface.co/production/uploads/646516d2200b583e1e50faf8/79yPdK79m9mA0cCz-3h4v.png" width="500" style="margin-left:auto; margin-right: auto"/>
<figcaption style="text-align: center; margin-left: auto; margin-right: auto; font-style: italic;">
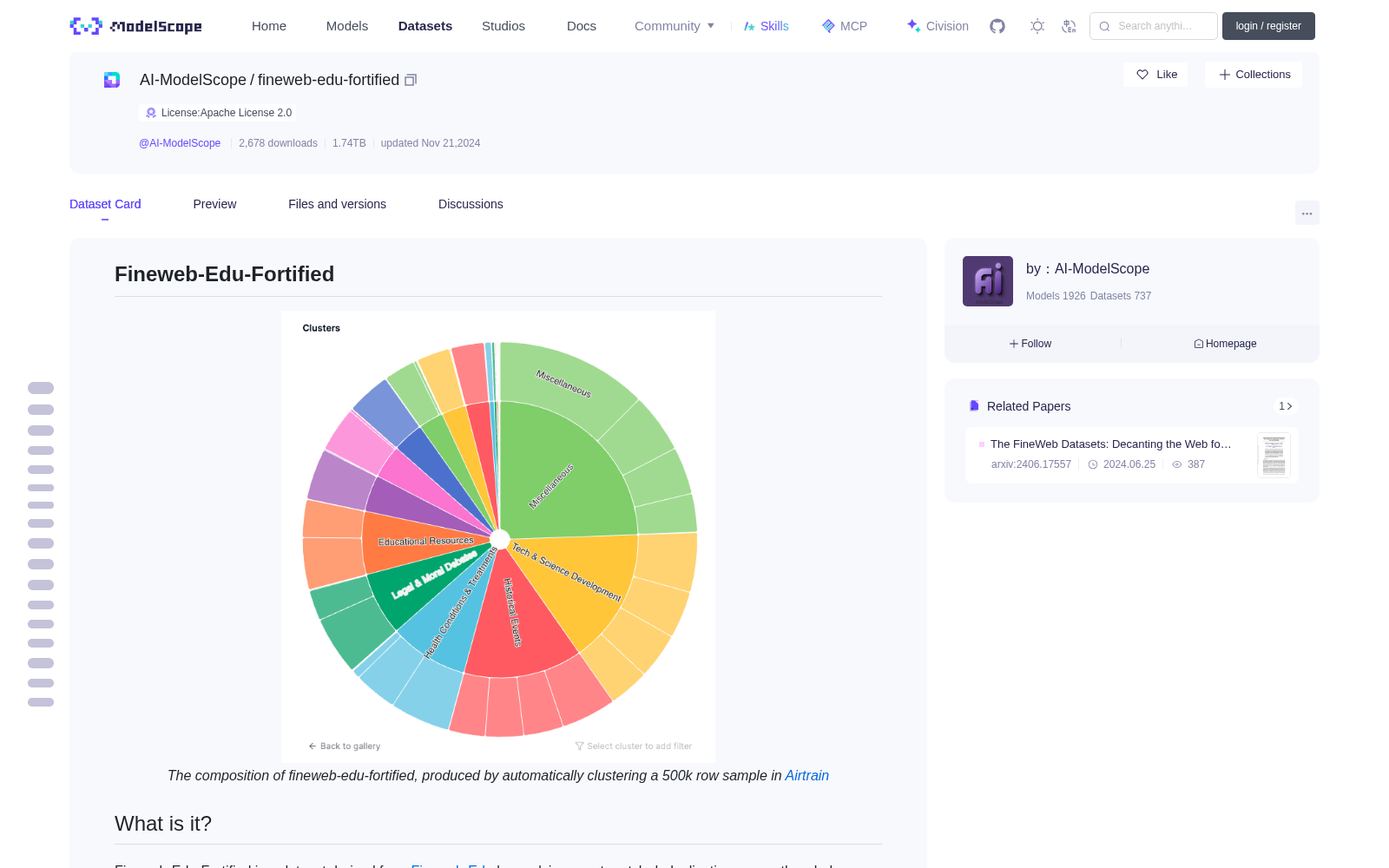
The composition of fineweb-edu-fortified, produced by automatically clustering a 500k row sample in
<a href="https://app.airtrain.ai/dataset/c232b33f-4f4a-49a7-ba55-8167a5f433da/null/1/0"> Airtrain </a>
</figcaption>
</figure>
## What is it?
Fineweb-Edu-Fortified is a dataset derived from
[Fineweb-Edu](https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu) by applying exact-match
deduplication across the whole dataset and producing an embedding for each row. The number of times
the text from each row appears is also included as a `count` column. The embeddings were produced
using [TaylorAI/bge-micro](https://huggingface.co/TaylorAI/bge-micro)
Fineweb and Fineweb-Edu were obtained by processing data from 95 crawls of
[Common Crawl](https://commoncrawl.org/), covering a time period from 2013 to 2024.
More information about the original datasets can be found by consulting:
- [Fineweb-edu dataset card](https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu)
- [Fineweb dataset card](https://huggingface.co/datasets/HuggingFaceFW/fineweb)
- [Fineweb release blog post](https://huggingface.co/spaces/HuggingFaceFW/blogpost-fineweb-v1)
- [Fineweb paper](https://arxiv.org/abs/2406.17557)
The contents of a randomly selected 500k rows from this dataset can be interactively
explored in this
[Airtrain](https://app.airtrain.ai/dataset/c232b33f-4f4a-49a7-ba55-8167a5f433da/null/1/0)
dashboard.
## Deduplication
### Deduplication in original Fineweb and Fineweb-Edu
During creation of the original Fineweb dataset, a variety of deduplication strategies were
explored. The evaluation criteria used to assess deduplication strategies was to train ablation models
on randomly selected subsets of the data, using a subset of up to ~350 billion tokens.
Using this mechanism, the Fineweb authors selected a MinHash algorithm, using parameters
considering documents with approximately 75% similarity or higher to be duplicates. This deduplication was
performed *within* each Common Crawl crawl. For example, it would have removed all approximate duplicates
from the 20th crawl from 2013, but would have retained an identical record that showed up
in both the 2013-20 crawl and the 2013-48 crawl. The authors note that applying the
deduplication *across crawls* reduced the evaluation performance of the ablation models used
for assessment. The proposed reason for this performance degredation is that data
duplicated across crawls is more likely to be high-quality compared to data that is not,
so leaving in the duplicates effectively upsamples the higer-quality data.
Following deduplication in Fineweb, Fineweb-Edu was extracted using a model-based quality classifier
targeting educational content. It thus inherited the same inter-crawl deduplication strategy of Fineweb.
### Deduplication in this dataset
#### Motivation
Given the findings that cross-crawl deduplication reduced ablation model performance, one might ask
what the motivation is for producing a dataset that uses it. Our motivation was threefold:
- Reduce the number of rows that needed to be embedded by avoiding embedding of exact-match content
- Enable easier filtering of the dataset for subsets-of-interest
- Provide a version of the dataset for users whose training goals include avoiding training on non-unique
tokens.
For use cases that would benefit from "re-hydrating" or filtering the rows based on how frequently
the text appeared in the original dataset, the new `count` column retains the number of appearances
of the associated text.
#### Procedure
The overall procedure was to remove exact matches that appeared in multiple crawls (also referred to
as "dumps"). This was achieved by performing an md5 hash on the text column and removing rows with
duplicate hashes. To make this tractable at scale, we first grouped all rows by the first two hex
digits of their hashes, then looked for exact hash matches within each of the resulting 256
buckets of data. Note that unlike the intra-crawl deduplication, we only eliminated exact matches
across crawls. For duplicated rows, a strong preference was given to keep the metadata
(ex: dump, url) from the oldest crawl where the text appeared. Following deduplication and
embedding, the data were grouped by the "dump" column, mirroring the organization of the original
Fineweb-Edu dataset.
### Deduplication stats
Deduplication removed approximately 74.7% of rows from the original dataset
(from 1.279 billion in Fineweb-Edu to 0.324 billion rows in Fineweb-Edu-Fortified).
This indicates that a substantial amount of data in Fineweb-Edu is present across multiple crawls.
The total token count in the deduplicated dataset is approximately 375 billion, compared to the
1,320 billion tokens in Fineweb-Edu.
<figure>
<img src="https://cdn-uploads.huggingface.co/production/uploads/646516d2200b583e1e50faf8/mUFyO1fUWJEXbYwiteR9e.png" width="750" style="margin-left:auto; margin-right: auto"/>
<figcaption style="text-align: center; margin-left: auto; margin-right: auto; font-style: italic;">
A histogram of the `count` column. Histogram was generated using a 500k row sample after
performing global per-row text duplication counting.
</figcaption>
</figure>
## Embeddings
To support use cases with Fineweb-Edu such as classification, clustering, semantic search, etc.,
we have produced an embedding vector for each row in the dataset. The embedding model
[TaylorAI/bge-micro](https://huggingface.co/TaylorAI/bge-micro)
was selected for its tradeoff of strong performance on [MTEB](https://huggingface.co/spaces/mteb/leaderboard)
benchmarks relative to its size (17 million parameters). The model's embedding space
has 384 dimensions. The context-window of the model is 512 tokens (roughly several paragraphs of text);
each row is embedded by using the first 512 tokens in its text field. Producing the embeddings took approximately
412 GPU-hours on Nvidia T4 GPUs.
## Using via `datasets`
```python
from datasets import load_dataset
fw = load_dataset("airtrain-ai/fineweb-edu-fortified", name="CC-MAIN-2024-10", split="train", streaming=True)
```
## Considerations for Using the Data
This "Considerations" section is copied from the parent dataset:
[FineWeb-edu](https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu).
### Social Impact of Dataset
With the release of this dataset we aim to make model training more accessible to the machine learning community at large.
While multiple open-weights models with strong performance have been publicly released in the past, more often than not these releases are not accompanied by the corresponding training dataset. This is unfortunate as the dataset specificities and characteristics have been demonstrated to have a very large impact and role in the performances of the models. As the creation of a high quality training dataset is a fundamental requirement to training an LLM capable of excelling at downstream tasks, with 🍷 FineWeb we (a) not only make the dataset creation process more transparent, by sharing our entire processing setup including the codebase used, we also (b) help alleviate the costs of dataset curation, both in time and in compute, for model creators by publicly releasing our dataset with the community.
### Discussion of Biases
Efforts were made to minimize the amount of NSFW and toxic content present in the dataset by employing filtering on the URL level. However, there are still a significant number of documents present in the final dataset that could be considered toxic or contain harmful content. As 🍷 FineWeb was sourced from the web as a whole, any harmful biases typically present in it may be reproduced on our dataset.
We deliberately avoided using machine learning filtering methods that define text quality based on the similarity to a “gold” source such as wikipedia or toxicity classifiers as these methods have been known to [disproportionately remove content in specific dialects](https://aclanthology.org/D16-1120/) and [overclassify as toxic text related to specific social identities](https://arxiv.org/pdf/2109.07445.pdf), respectively.
### Other Known Limitations
As a consequence of some of the filtering steps applied, it is likely that code content is not prevalent in our dataset. If you are training a model that should also perform code tasks, we recommend you use 🍷 FineWeb with a code dataset, such as [The Stack v2](https://huggingface.co/datasets/bigcode/the-stack-v2). You should also probably consider complementing 🍷 FineWeb with specialized curated sources (such as Wikipedia, for example) as they will likely have better formatting than the wikipedia content included in 🍷 FineWeb (we did not tailor the processing to individual websites).
## Additional Information
### Acknowledgements
Airtrain would like to thank the Fineweb/Fineweb-Edu team at Hugging Face for producing the original datasets,
as well as for their support during work on Fineweb-Edu-Fortified.
We'd also like to thank [@underspirit](https://huggingface.co/underspirit) for
[pointing out](https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu/discussions/7)
the amount of reduction in dataset size that could be achieved via deduplication.
We owe gratitude to [TaylorAI](https://huggingface.co/TaylorAI) for the `bge-micro` embedding model.
Finally, thank you to the Hugging Face community for fostering a thriving ecosystem of models, datasets, and tools
to support open-source AI.
### Licensing Information
The dataset is released under the **Open Data Commons Attribution License (ODC-By) v1.0** [license](https://opendatacommons.org/licenses/by/1-0/). The use of this dataset is also subject to [CommonCrawl's Terms of Use](https://commoncrawl.org/terms-of-use).
# 强化版Fineweb-Edu数据集(Fineweb-Edu-Fortified)
<figure>
<img src="https://cdn-uploads.huggingface.co/production/uploads/646516d2200b583e1e50faf8/79yPdK79m9mA0cCz-3h4v.png" width="500" style="margin-left:auto; margin-right: auto"/>
<figcaption style="text-align: center; margin-left: auto; margin-right: auto; font-style: italic;">
本图展示了强化版Fineweb-Edu数据集的构成,通过对50万行样本自动聚类生成,可在[Airtrain](https://app.airtrain.ai/dataset/c232b33f-4f4a-49a7-ba55-8167a5f433da/null/1/0)平台交互查看
</figcaption>
</figure>
## 数据集简介
强化版Fineweb-Edu数据集源自[Fineweb-Edu](https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu),通过对全数据集执行精确匹配去重,并为每一行数据生成嵌入向量而得到。新增的`count`列会记录每条文本出现的次数。嵌入向量由[TaylorAI/bge-micro](https://huggingface.co/TaylorAI/bge-micro)模型生成。
Fineweb与Fineweb-Edu数据集通过处理[Common Crawl](https://commoncrawl.org/)的95次爬取数据构建,时间跨度覆盖2013年至2024年。更多原始数据集的相关信息可参考:
- [Fineweb-edu数据集卡片](https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu)
- [Fineweb数据集卡片](https://huggingface.co/datasets/HuggingFaceFW/fineweb)
- [Fineweb发布博客](https://huggingface.co/spaces/HuggingFaceFW/blogpost-fineweb-v1)
- [Fineweb研究论文](https://arxiv.org/abs/2406.17557)
该数据集随机选取的50万行样本可在该[Airtrain](https://app.airtrain.ai/dataset/c232b33f-4f4a-49a7-ba55-8167a5f433da/null/1/0)仪表盘上交互式探索。
## 去重机制
### 原始Fineweb与Fineweb-Edu的去重策略
在原始Fineweb数据集的创建过程中,研究人员探索了多种去重方案。评估去重策略的标准为:在最多约3500亿Token(Token)的随机数据子集上训练消融模型,以此衡量去重效果。
通过该评估机制,Fineweb团队选用了MinHash算法,将相似度约75%及以上的文档判定为重复内容。该去重操作**仅在单次Common Crawl爬取范围内执行**。例如,该操作会移除2013年第20次爬取结果中的所有近似重复内容,但会保留同时出现在2013-20次爬取与2013-48次爬取中的完全相同记录。研究团队指出,若在跨爬取范围的维度上执行去重,会降低评估所用消融模型的性能。其背后的原因是:跨爬取范围重复出现的数据,相比非重复数据更有可能具备较高质量,因此保留这些重复内容实际上相当于对高质量数据进行了上采样。
在Fineweb完成去重后,研究团队通过针对教育内容的模型质量分类器提取得到了Fineweb-Edu数据集,因此该数据集继承了Fineweb的爬取内去重策略。
### 本数据集的去重方案
#### 设计动机
既然已有研究表明跨爬取范围去重会降低消融模型的性能,那么为何我们仍要推出采用该策略的数据集?我们的设计动机有三点:
1. 通过避免对精确匹配的文本生成嵌入,减少需要执行嵌入运算的数据行数
2. 便于用户根据自身需求对数据集进行筛选,获取目标子集
3. 为那些训练目标要求避免在非唯一Token上进行训练的用户提供适配的数据集版本
对于希望根据原始数据集中文本出现频率来“重建”或筛选数据的使用场景,新增的`count`列会保留对应文本的出现次数。
#### 执行流程
整体流程为:移除在多个爬取范围(也称为“转储(dump)”)中出现的精确匹配文本。具体实现方式为:对文本列计算MD5哈希值,移除哈希值重复的行。为了在大规模数据下实现该操作的可执行性,我们首先根据哈希值的前两位十六进制字符对所有行进行分组,随后在生成的256个数据桶中逐一查找精确的哈希重复项。请注意,与爬取内去重不同,本次我们仅移除跨爬取范围的精确重复内容。对于重复的行,我们优先保留文本最早出现的那次爬取的元数据(例如转储信息、URL等)。完成去重与嵌入生成后,我们按照“转储(dump)”列对数据进行分组,以延续原始Fineweb-Edu数据集的组织形式。
### 去重统计数据
本次去重操作从原始数据集中移除了约74.7%的行(从Fineweb-Edu的12.79亿行缩减至强化版Fineweb-Edu的3.24亿行),这表明Fineweb-Edu中有大量数据在多个爬取范围中重复出现。
去重后的数据集总Token数约为3750亿,而原始Fineweb-Edu数据集的总Token数为1.32万亿。
<figure>
<img src="https://cdn-uploads.huggingface.co/production/uploads/646516d2200b583e1e50faf8/mUFyO1fUWJEXbYwiteR9e.png" width="750" style="margin-left:auto; margin-right: auto"/>
<figcaption style="text-align: center; margin-left: auto; margin-right: auto; font-style: italic;">
本直方图展示了`count`列的分布情况,基于全局逐行文本重复计数后的50万行样本生成
</figcaption>
</figure>
## 嵌入向量生成
为了支持Fineweb-Edu的各类下游应用,例如分类、聚类、语义搜索等,我们为数据集中的每一行生成了嵌入向量。我们选用了[TaylorAI/bge-micro](https://huggingface.co/TaylorAI/bge-micro)模型,该模型在[MTEB](https://huggingface.co/spaces/mteb/leaderboard)基准测试中的性能与模型体量(1700万参数)之间取得了良好平衡。该模型的嵌入空间维度为384,上下文窗口长度为512个Token(约对应数个段落的文本);每一行数据的嵌入通过对其文本字段的前512个Token进行编码生成。本次嵌入生成操作在Nvidia T4 GPU上耗时约412 GPU小时。
## 通过`datasets`库使用
python
from datasets import load_dataset
fw = load_dataset("airtrain-ai/fineweb-edu-fortified", name="CC-MAIN-2024-10", split="train", streaming=True)
## 数据集使用注意事项
本“注意事项”部分源自父数据集[FineWeb-edu](https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu)。
### 数据集的社会影响
我们发布本数据集的目标是让机器学习社区更便捷地开展模型训练工作。
尽管此前已有多款性能优异的开源权重模型公开发布,但这些发布大多未附带对应的训练数据集。这一点令人遗憾,因为数据集的特性与细节对模型的性能有着极为显著的影响。构建高质量训练数据集是训练出能够在下游任务中表现出色的大语言模型(Large Language Model, LLM)的核心前提,我们通过🍷 Fineweb项目实现了两个目标:(a) 公开完整的处理流程与代码库,使数据集的构建过程更加透明;(b) 向社区公开发布我们的数据集,以帮助模型开发者节省数据集整理所需的时间与计算资源成本。
### 偏差问题说明
我们通过URL层面的过滤,尽可能减少数据集中包含不适宜工作场所(Not Safe For Work, NSFW)与有毒内容的文档数量。但最终数据集中仍存在大量可能被视为有毒或包含有害内容的文档。由于🍷 Fineweb的数据源为整个公开网络,因此该数据集可能会重现公开网络中普遍存在的各类有害偏差。
我们刻意避免使用基于与“黄金”数据源(例如维基百科)的相似度来定义文本质量的机器学习过滤方法,也未使用毒性分类器,因为已有研究表明[前者会不成比例地移除特定方言的内容](https://aclanthology.org/D16-1120/),[后者会过度将与特定社会身份相关的文本判定为有毒内容](https://arxiv.org/pdf/2109.07445.pdf)。
### 已知其他局限性
由于部分过滤步骤的影响,本数据集中代码内容的占比可能较低。如果您正在训练需要处理代码任务的模型,我们建议将🍷 Fineweb与代码数据集结合使用,例如[The Stack v2](https://huggingface.co/datasets/bigcode/the-stack-v2)。此外,您也可以考虑将🍷 Fineweb与经过精心整理的专业数据源(例如维基百科)结合使用,因为这些数据源的格式可能比🍷 Fineweb中包含的维基百科内容更规范(我们并未针对单个网站定制处理流程)。
## 附加信息
### 致谢
Airtrain团队感谢Hugging Face的Fineweb/Fineweb-Edu团队创建了原始数据集,并在强化版Fineweb-Edu的开发过程中提供了支持。
我们还要感谢[@underspirit](https://huggingface.co/underspirit),他[指出了](https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu/discussions/7)通过去重操作可大幅缩减数据集规模。
我们感谢[TaylorAI](https://huggingface.co/TaylorAI)团队开源了`bge-micro`嵌入模型。
最后,感谢Hugging Face社区为开源AI打造了繁荣的模型、数据集与工具生态。
### 许可信息
本数据集采用**开放数据Commons署名许可协议(Open Data Commons Attribution License, ODC-By)v1.0**[许可](https://opendatacommons.org/licenses/by/1-0/)发布。使用本数据集同时需遵守[CommonCrawl的使用条款](https://commoncrawl.org/terms-of-use)。
提供机构:
maas创建时间:
2024-08-16
搜集汇总
数据集介绍
背景与挑战
背景概述
Fineweb-Edu-Fortified是基于Fineweb-Edu数据集通过跨爬取精确去重和嵌入处理生成的版本,包含约0.324亿行和3750亿个令牌,嵌入向量使用TaylorAI/bge-micro模型生成。该数据集来源于2013年至2024年间的95个Common Crawl爬取,去重后行数减少约74.7%,并采用ODC-By v1.0许可证。
以上内容由遇见数据集搜集并总结生成


