naidu1999/tourism-test
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/naidu1999/tourism-test
下载链接
链接失效反馈官方服务:
资源简介:
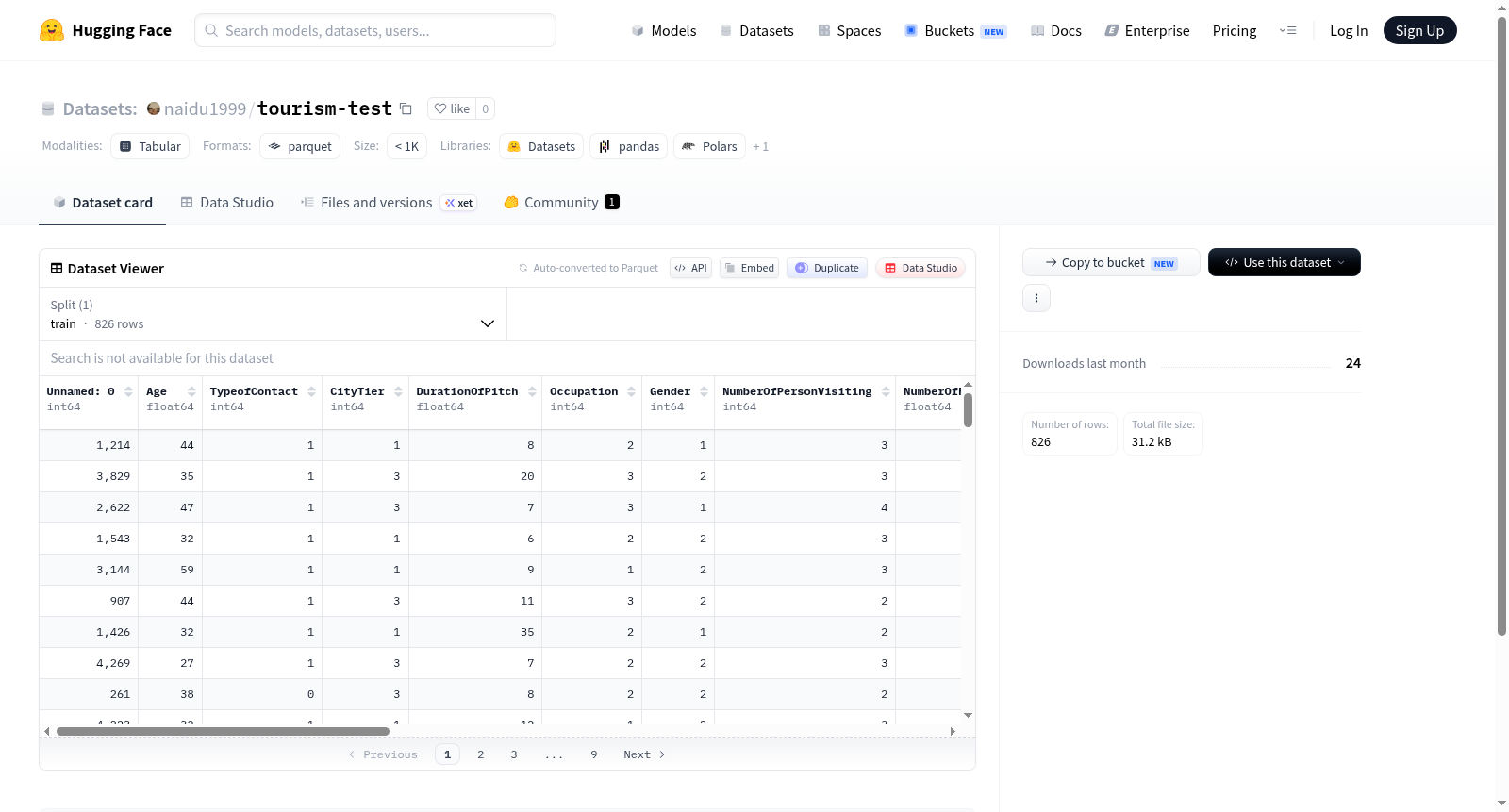
该数据集是一个包含826个样本的训练集,用于分析或预测客户行为,可能涉及旅游或推销场景。特征包括年龄、联系方式类型、城市等级、推销时长、职业、性别、访问人数、跟进次数、推销产品、首选酒店星级、婚姻状况、旅行次数、护照持有情况、推销满意度评分、汽车拥有情况、随行儿童数量、职务和月收入等数值和分类变量。数据集未提供明确的背景描述,但结构表明适用于机器学习分类或回归任务。
This dataset is a training set with 826 samples, likely used for analyzing or predicting customer behavior, possibly in tourism or sales contexts. Features include age, type of contact, city tier, duration of pitch, occupation, gender, number of persons visiting, number of follow-ups, product pitched, preferred property star rating, marital status, number of trips, passport status, pitch satisfaction score, car ownership, number of children visiting, designation, and monthly income, comprising numerical and categorical variables. No explicit background description is provided in the README, but the structure suggests suitability for machine learning classification or regression tasks.
提供机构:
naidu1999
搜集汇总
数据集介绍
构建方式
tourism-test数据集是专为旅游领域机器学习任务设计的测试数据集,其构建基于对旅游客户行为数据的系统化整理。该数据集共包含826个样本,以结构化表格形式存储,涵盖20个特征维度,包括年龄、联系方式类型、城市等级、职业、性别、同行人数、随访次数、产品偏好、酒店星级偏好、婚姻状况、出行次数、护照持有情况、推销满意度评分、拥有汽车与否、随行儿童数量、职位等级及月收入等变量。数据采用CSV格式,通过单训练集划分方式组织,便于直接加载与模型训练评估。
特点
该数据集最显著的特点在于其多维度的特征设计,精准刻画了旅游消费者的画像与决策行为。数值型与类别型特征并存,且包含部分缺失值(如年龄、月收入等字段以浮点数形式记录),真实反映了实际业务场景中的数据质量。特征涵盖人口统计学属性、消费能力指标、产品偏好以及历史行为记录,为预测客户对旅游产品的购买意愿或满意度提供了丰富的信息。此外,数据集规模适中,适合作为教学案例或快速原型验证的基准。
使用方法
使用tourism-test数据集时,可借助Python的Pandas库或HuggingFace Datasets库轻松读取。若采用Datasets库,可通过load_dataset('tourism-test')直接加载,数据自动以默认配置返回训练集。数据预处理环节需关注缺失值处理(如对DurationOfPitch、MonthlyIncome等浮点字段进行填充或删除),以及类别特征(如Occupation、Gender等整型编码字段)的标签编码或独热编码。该数据集适用于监督学习任务,如使用随机森林、XGBoost或神经网络预测PitchSatisfactionScore评分,或构建二分类模型判断客户是否成交。
背景与挑战
背景概述
旅游行业作为全球经济的重要支柱,其数字化转型催生了大量基于机器学习的预测与推荐需求。tourism-test数据集由相关研究机构于近年发布,聚焦于旅游产品购买意向预测这一核心问题,涵盖客户年龄、联系方式类型、城市等级、职业、婚姻状况、月收入、护照持有、过往旅行次数等多维特征,旨在构建用户画像并探究影响旅游决策的关键因素。该数据集为旅游营销、客户关系管理及个性化服务等领域的研究提供了宝贵的基准资源,推动了从传统统计建模向深度学习方法的范式迁移。
当前挑战
该数据集所解决的领域问题在于精准预测旅游产品购买意向,以提升营销转化效率并降低资源浪费。然而,其构建过程面临多重挑战:样本量有限(仅826条训练数据),易导致模型过拟合与泛化能力不足;特征中存在大量缺失值(如DurationOfPitch、NumberOfFollowups等),需谨慎处理以保留信息完整性;此外,数值与类别型特征并存,且部分变量(如PitchSatisfactionScore)可能存在主观偏差,增加了特征工程与模型选择的复杂度。这些挑战要求研究者采用正则化、集成学习或数据增强等技术,以在有限资源下实现稳健预测。
常用场景
经典使用场景
旅游行业的数据驱动决策日益成为研究热点,而tourism-test数据集作为旅游营销领域的结构化样本集合,为深入探究客户转化预测提供了宝贵资源。该数据集最经典的用法是构建客户购买意向分类模型,通过整合客户人口统计学特征(如年龄、性别、收入)、行程相关信息(如同行人数、旅行次数)以及营销沟通指标(如跟进次数、产品推介满意度),预测潜在客户最终是否会完成旅游产品预订。这一任务不仅能够评估特征工程与机器学习算法的效能,还为理解影响客户决策的关键因素奠定了实证基础,成为旅游推荐系统与精准营销研究的基准测试平台。
解决学术问题
在学术研究中,tourism-test数据集有效解决了旅游消费行为预测中特征稀疏与样本不平衡的挑战,为实证分析提供了可复现的研究标准。该数据集促使学者深入探讨客户特征与购买意愿之间的非线性关系,推动了对传统逻辑回归、支持向量机以及集成学习方法的改进与创新。同时,通过细致刻画联系方式、产品偏好与满意度评分等多维变量,该数据集帮助研究者检验了营销干预策略对客户决策路径的调节效应,从而丰富了旅游消费行为理论,并为后续构建更精准的客户流失预警与价值评估模型奠定了方法论基础。
衍生相关工作
围绕tourism-test数据集,学界与工业界已衍生出多项具有代表性的经典工作。在特征工程层面,研究者开发了面向旅游客户的多模态特征交互方法,将人口统计属性与行为序列特征进行深度融合;在模型构建方面,梯度提升机与深度神经网络被创新应用于该数据集,显著提升了少数类样本的召回性能。此外,该数据集催生了面向旅游营销的迁移学习框架,使得在小样本场景下仍能保持稳定的预测精度。这些衍生工作不仅推动了机器学习在旅游垂直领域的实用化进程,也为跨行业客户行为建模提供了可迁移的算法范本,持续激发着相关领域的创新探索。
以上内容由遇见数据集搜集并总结生成


