OCR Document Text Recognition Dataset
收藏www.kaggle.com2023-09-07 更新2025-03-24 收录
下载链接:
https://www.kaggle.com/trainingdatapro/text-detection-in-the-documents
下载链接
链接失效反馈官方服务:
资源简介:
# OCR Text Detection in the Documents Object Detection dataset
The dataset is a collection of images that have been annotated with the location of text in the document. The dataset is specifically curated for text detection and recognition tasks in documents such as scanned papers, forms, invoices, and handwritten notes.
The dataset contains a variety of document types, including different *layouts, font sizes, and styles*. The images come from diverse sources, ensuring a representative collection of document styles and quality. Each image in the dataset is accompanied by bounding box annotations that outline the exact location of the text within the document.
# 💴 For Commercial Usage: To discuss your requirements, learn about the price and buy the dataset, leave a request on **[TrainingData](https://trainingdata.pro/datasets?utm_source=kaggle&utm_medium=cpc&utm_campaign=text-detection-in-the-documents)** to buy the dataset
The Text Detection in the Documents dataset provides an invaluable resource for developing and testing algorithms for text extraction, recognition, and analysis. It enables researchers to explore and innovate in various applications, including *optical character recognition (OCR), information extraction, and document understanding*.
.png?generation=1691059158337136&alt=media)
# Dataset structure
- **images** - contains of original images of documents
- **boxes** - includes bounding box labeling for the original images
- **annotations.xml** - contains coordinates of the bounding boxes and labels, created for the original photo
# Data Format
Each image from `images` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the bounding boxes and labels for text detection. For each point, the x and y coordinates are provided.
### Labels for the text:
- **"Text Title"** - corresponds to titles, the box is **red**
- **"Text Paragraph"** - corresponds to paragraphs of text, the box is **blue**
- **"Table"** - corresponds to the table, the box is **green**
- **"Handwritten"** - corresponds to handwritten text, the box is **purple**
# Example of XML file structure
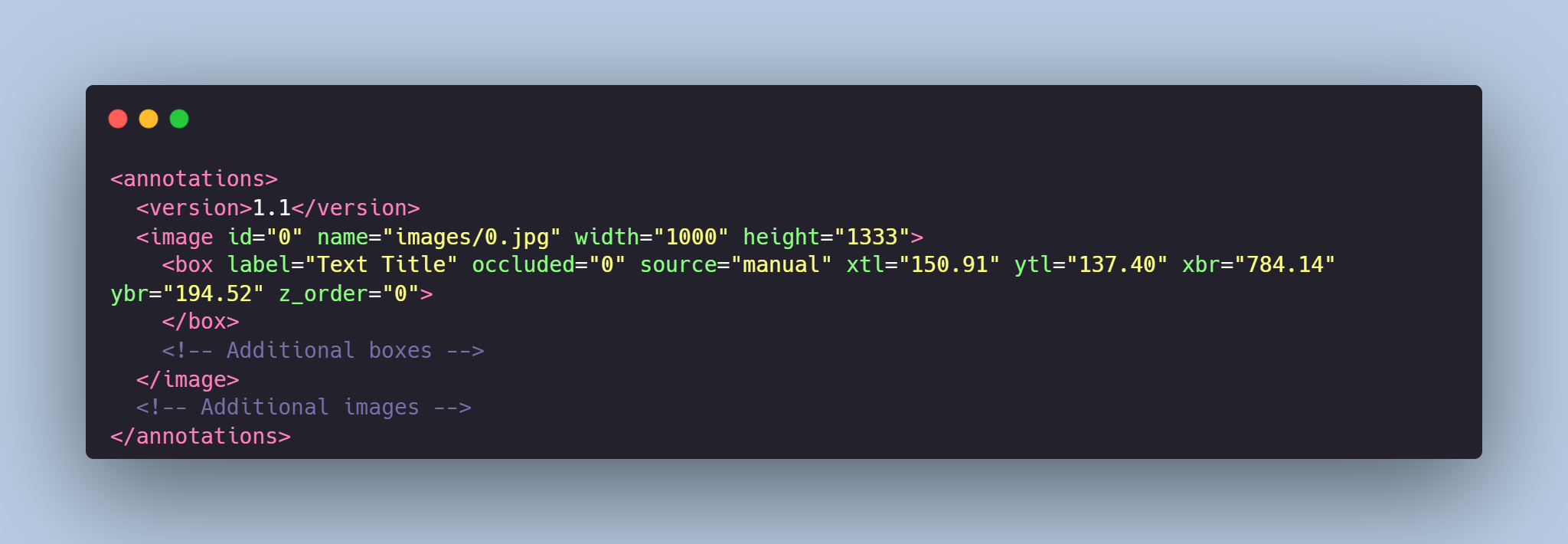
# Text Detection in the Documents might be made in accordance with your requirements.
# 💴 Buy the Dataset: This is just an example of the data. Leave a request on **[https://trainingdata.pro/datasets](https://trainingdata.pro/datasets?utm_source=kaggle&utm_medium=cpc&utm_campaign=text-detection-in-the-documents)** to discuss your requirements, learn about the price and buy the dataset
## **[TrainingData](https://trainingdata.pro/datasets?utm_source=kaggle&utm_medium=cpc&utm_campaign=text-detection-in-the-documents)** provides high-quality data annotation tailored to your needs
*keywords: text detection, text recognition, optical character recognition, document text recognition, document text detection, detecting text-lines, object detection, scanned documents, deep-text-recognition, text area detection, text extraction, images dataset, image-to-text*
## 文档文本检测数据集
本数据集汇集了一系列标注了文档中文本位置图像的集合。该数据集特别针对文档中的文本检测与识别任务进行精心构建,包括扫描的纸张、表格、发票以及手写笔记等文档类型。
数据集包含了多样化的文档类型,涵盖了不同的布局、字体大小和风格。图像来源广泛,确保了文档风格和质量的代表性集合。数据集中的每一张图像均附有边界框标注,精确描绘了文本在文档中的具体位置。
# 💴 商业用途:如需讨论需求、了解价格并购买数据集,请至 **[TrainingData](https://trainingdata.pro/datasets?utm_source=kaggleu0026utm_medium=cpcu0026utm_campaign=text-detection-in-the-documents)** 留下购买请求
文档文本检测数据集为文本提取、识别与分析算法的开发与测试提供了无价资源。它允许研究人员探索与创新,应用于包括光学字符识别(OCR)、信息提取以及文档理解在内的多种应用领域。
.png?generation=1691059158337136u0026alt=media)
## 数据集结构
- **images** - 包含文档的原始图像
- **boxes** - 包含原始图像的边界框标注
- **annotations.xml** - 包含边界框坐标和标签,专为原始照片创建
## 数据格式
`images` 文件夹中的每一张图像均由 `annotations.xml` 文件中的XML标注伴随,指出边界框坐标和文本检测标签。对于每个点,均提供了x和y坐标。
### 文本标签:
- **"Text Title"** - 对应标题,边界框为**红色**
- **"Text Paragraph"** - 对应文本段落,边界框为**蓝色**
- **"Table
提供机构:
Training Data


