RoleAgent/RoleAgentBench
收藏Hugging Face2024-06-13 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/RoleAgent/RoleAgentBench
下载链接
链接失效反馈官方服务:
资源简介:
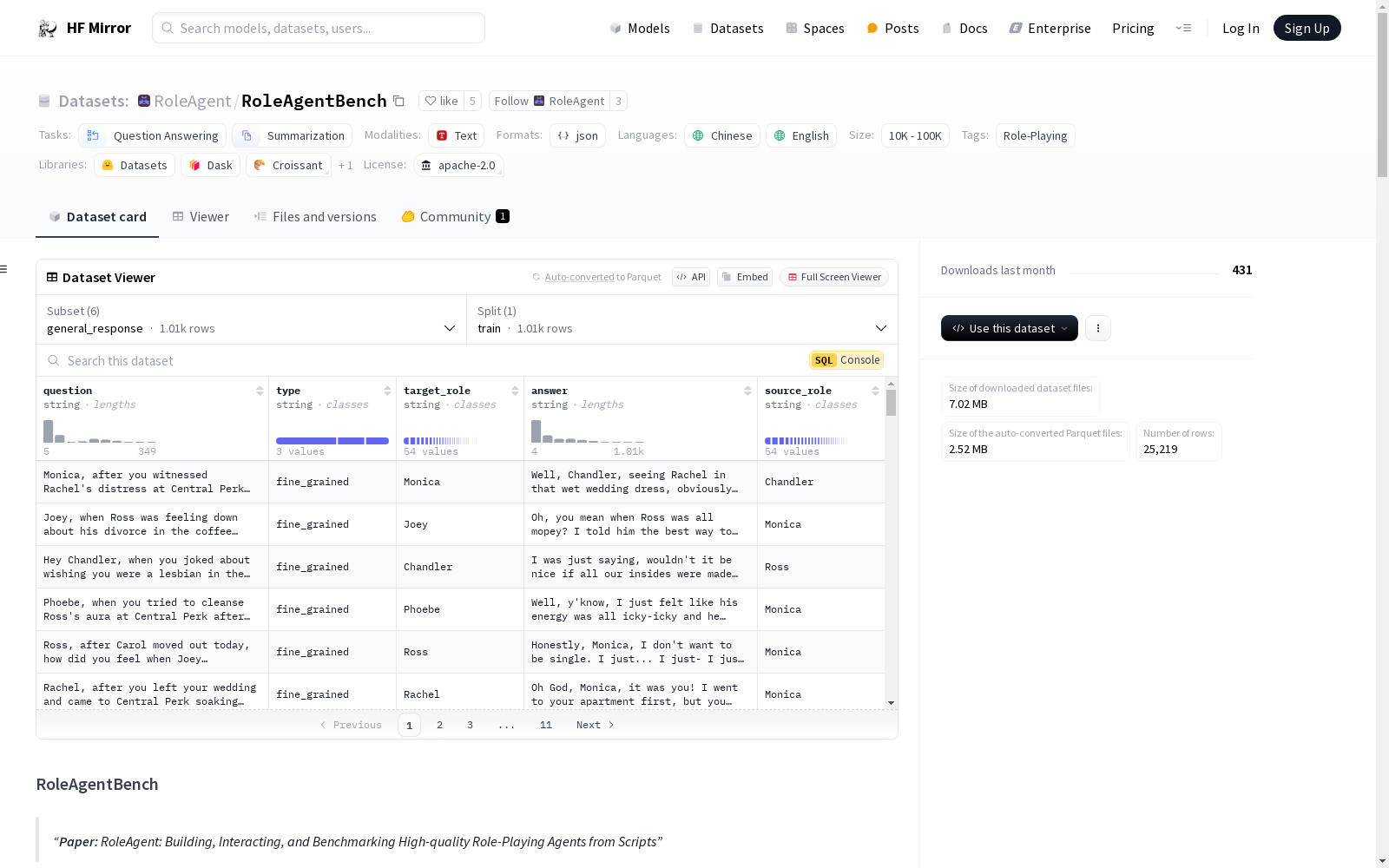
RoleAgentBench数据集包含128个角色,来自5个中文和20个英文脚本,用于评估角色扮演代理的模拟质量和记忆系统。数据集包括四个子任务:Summarization、Self-Knowledge、Reaction和General Response。每个子任务都有详细的评估方法和指标。数据集的脚本列表包括多个知名的中文和英文影视作品,每个作品都有对应的角色列表。数据集的结构包括原始数据、角色档案和不同任务的测试集。
The RoleAgentBench dataset includes 128 characters sourced from 5 Chinese and 20 English scripts, designed to evaluate the simulation quality and memory system of role-playing AI agents. The dataset encompasses four subtasks: Summarization, Self-Knowledge, Reaction, and General Response, each with detailed evaluation methods and metrics. The script list of the dataset covers multiple renowned Chinese and English film and television works, with corresponding character lists for each work. The structure of the dataset consists of raw data, character profiles, and test sets for different tasks.
提供机构:
RoleAgent
原始信息汇总
数据集概述
基本信息
- 许可证: Apache 2.0
- 任务类别:
- 问答
- 摘要生成
- 语言:
- 中文
- 英文
- 标签: Role-Playing
配置详情
- 初始化:
- 数据文件:
*/profiles/*.jsonl
- 数据文件:
- 检索:
- 数据文件:
*/retrieval.json
- 数据文件:
- 摘要:
- 数据文件:
*/summary.json
- 数据文件:
- 自我知识:
- 数据文件:
*/self_knowledge.json
- 数据文件:
- 反应:
- 数据文件:
*/reaction.json
- 数据文件:
- 通用响应:
- 数据文件:
*/general_response.json
- 数据文件:
数据集内容
- 角色数量: 128个角色
- 剧本数量: 5个中文剧本和20个英文剧本
- 评估任务:
- 摘要生成: 评估生成摘要的实体密度和实体召回率。
- 自我知识: 测试角色代理识别其属性的能力。
- 反应: 测试角色代理对不同角色的反应能力。
- 通用响应: 测试角色代理的一般问答能力。
剧本列表
- 英文剧本:
- 《Friends》, 《Harry Potter》, 《Merchant of Venice》, 《Sherlock》, 《The Big Bang Theory》, 等20个剧本。
- 中文剧本:
- 《家有儿女》, 《九品芝麻官》, 《狂飙》, 《唐人街探案》, 《西游记》。
数据结构
- info.json: 存储数据集结构和每个剧本的信息。
- raw: 剧本的原始数据。
- profiles: 不同角色的观察数据,用于初始化。
- 其他文件:
retrieval.jsonsummary.jsonself_knowledge.jsonreaction.jsongeneral_response.json
下载方式
-
使用
git lfs进行下载: bash git lfs install git clone https://huggingface.co/datasets/RoleAgent/RoleAgentBench -
使用
datasets库加载数据集: python from datasets import load_dataset dataset = load_dataset("RoleAgent/RoleAgentBench")
搜集汇总
数据集介绍
构建方式
RoleAgentBench数据集通过精心挑选的5部中文和20部英文剧本构建,涵盖了128个角色。数据集的构建过程包括从剧本中提取角色信息,并利用GPT-4生成问题和答案,随后由人工标注者进行修订,确保数据的准确性和质量。数据集分为多个子任务,包括总结、自我知识、反应和通用响应,每个子任务都有特定的评估指标和数据文件。
特点
RoleAgentBench数据集的显著特点在于其多语言支持(中文和英文)和多任务评估框架。数据集不仅涵盖了丰富的角色和剧本,还通过四个子任务评估角色代理的模拟质量和记忆系统。每个子任务都有独特的评估方法,如总结任务中的实体密度和召回率,自我知识任务中的准确性,反应任务中的角色间互动,以及通用响应任务中的通信能力。
使用方法
使用RoleAgentBench数据集时,用户可以通过HuggingFace的datasets库加载数据集,并根据需要选择不同的配置文件进行分析。数据集的结构清晰,包括原始剧本数据、角色配置文件和各子任务的测试集。用户可以利用这些数据进行角色代理的训练和评估,特别是在角色扮演和对话生成领域,以提升模型的表现和适应性。
背景与挑战
背景概述
RoleAgentBench数据集由RoleAgent项目构建,旨在通过从5部中文和20部英文剧本中提取的128个角色,评估角色扮演代理的高质量模拟及其记忆系统。该数据集的核心研究问题集中在代理模拟的整体质量和特定记忆系统的性能上,通过四个子任务进行评估:总结、自我知识、反应和通用响应。RoleAgentBench不仅为角色扮演代理的研究提供了丰富的资源,还通过GPT-4生成并经人工校正的问题和答案,确保了数据的高质量和多样性。该数据集的构建对提升角色扮演代理的交互能力和模拟质量具有重要意义,为相关领域的研究提供了新的基准。
当前挑战
RoleAgentBench数据集在构建过程中面临多项挑战。首先,从多语言剧本中提取和标准化角色信息,确保角色属性的准确性和一致性,是一项复杂且耗时的任务。其次,生成高质量的问答对,既要基于剧本内容,又要通过GPT-4和人工校正确保答案的准确性和风格化,这对数据生成和校正流程提出了高要求。此外,评估代理的反应能力和通用沟通能力时,如何设计既能反映角色特性又能覆盖广泛情境的测试问题,也是一大挑战。最后,数据集的多任务特性要求在不同任务间保持数据的一致性和可比性,这对数据管理和评估方法的设计提出了更高的要求。
常用场景
经典使用场景
RoleAgentBench数据集的经典使用场景主要集中在角色扮演代理的构建与评估。通过该数据集,研究者可以训练和测试角色扮演代理在不同情境下的表现,包括角色间的对话生成、角色自我认知的准确性以及对不同角色反应的适应性。这些任务不仅涵盖了问答和摘要生成,还涉及角色记忆系统的评估,从而为构建高质量的角色扮演代理提供了丰富的数据支持。
实际应用
RoleAgentBench数据集在实际应用中具有广泛的前景。在虚拟助手和聊天机器人领域,该数据集可用于训练能够模拟特定角色进行对话的智能代理,提升用户体验。在教育领域,它可以用于开发角色扮演学习系统,帮助学生通过模拟角色互动来增强学习效果。此外,在娱乐产业中,该数据集可用于创建更加逼真和互动性强的虚拟角色,提升游戏和影视作品的沉浸感。
衍生相关工作
RoleAgentBench数据集的发布催生了一系列相关研究工作。研究者们基于该数据集开发了多种角色扮演代理模型,探索了不同角色间的互动机制和记忆系统的优化方法。此外,该数据集还激发了对角色扮演代理在多语言环境下的适应性研究,推动了跨文化交流领域的技术进步。同时,基于该数据集的评估方法也被广泛应用于其他类似数据集的构建和评估中,促进了角色扮演代理领域的整体发展。
以上内容由遇见数据集搜集并总结生成


