Xuhui/human-sim
收藏Hugging Face2026-04-25 更新2026-03-29 收录
下载链接:
https://hf-mirror.com/datasets/Xuhui/human-sim
下载链接
链接失效反馈官方服务:
资源简介:
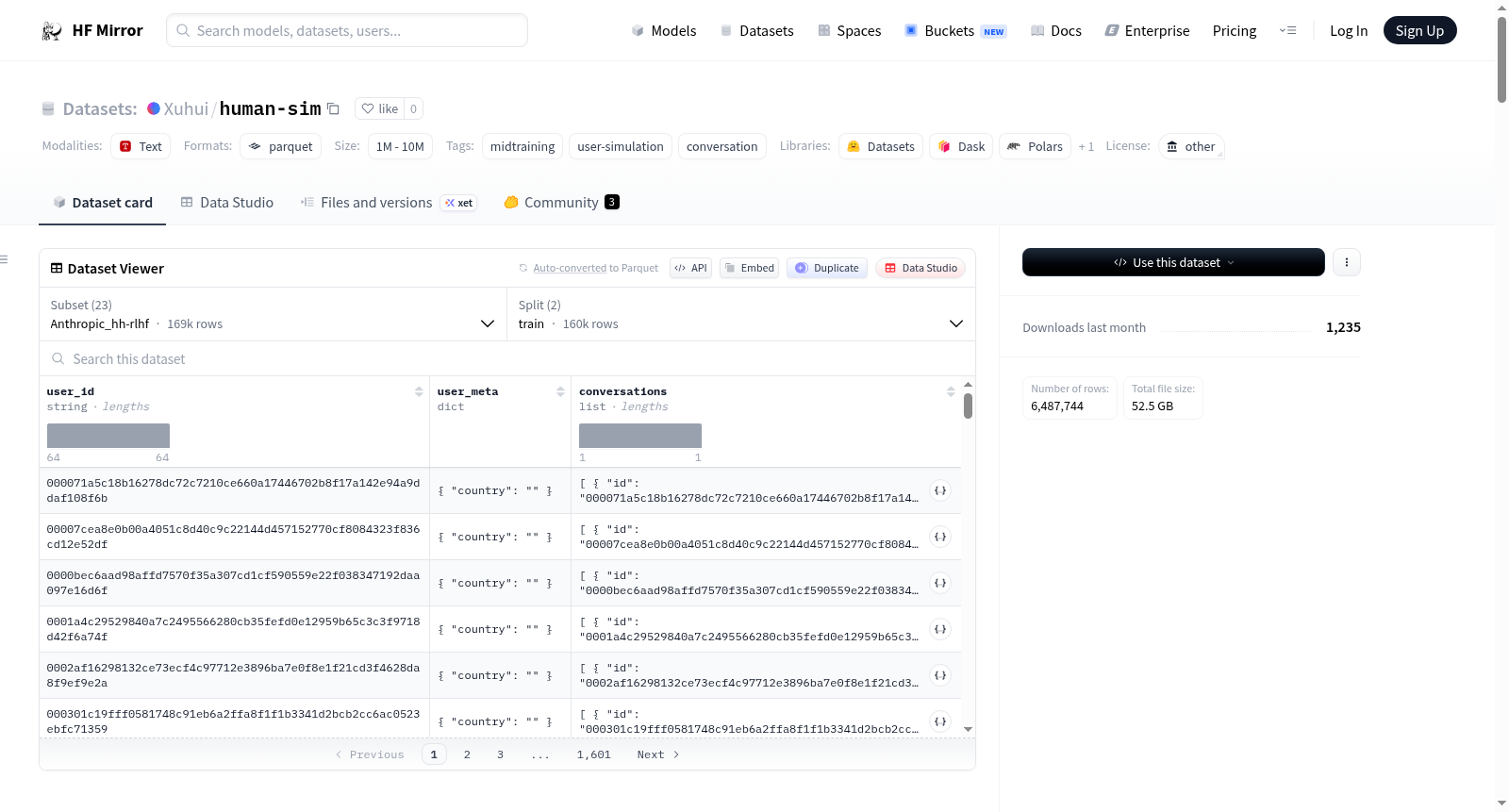
用于用户模拟的已处理数据集。每行代表一个用户,包含分组的对话。数据集包含多个子数据集,如OpenAssistant_oasst2、Anthropic_hh-rlhf等,每个子数据集都有训练和测试分割,并提供了用户数量统计。数据模式描述了数据的结构,包括用户ID、用户元数据以及包含消息和元数据的对话列表。
Processed dataset for user simulation. One row per user with grouped conversations. The dataset includes multiple sub-datasets like OpenAssistant_oasst2, Anthropic_hh-rlhf, etc., each with train and test splits, and provides user counts for each split. The schema describes the structure of the data, including user_id, user_meta, and conversations with messages and metadata.
提供机构:
Xuhui
搜集汇总
数据集介绍
构建方式
human-sim数据集专为对话智能体用户模拟任务而构建,汇聚了22个领域各异的高质量对话数据集。构建过程遵循用户级聚合范式,将来源于OpenAssistant、Anthropic、DailyDialog等知名语料库中的每条对话记录,通过SHA-256哈希对用户IP进行匿名化处理后,按用户标识(user_id)进行归并,从而为每个用户构建一个包含其全部历史对话的结构化档案。每个用户档案由元信息字段(如国家)和对话列表组成,后者详细记录了每条对话的来源、消息序列及元数据属性(如模型、轮次、时间戳等),最终以高效的Parquet格式存储,以支持大规模训练与评估。
特点
该数据集的核心特色在于其规模宏大与领域多样性并存,总计涵盖超过6.5百万个用户,对话来源跨越日常闲聊(如DailyDialog)、情感支持(EmpatheticDialogues)、技术问答(Ubuntu)、角色扮演(CoSER)及个性化新闻评论(humanual子集)等多种场景。通过统一的以用户为中心的数据结构,human-sim能够真实反映不同用户群体的交互偏好与行为模式,为构建更具个性化和情境适应性的用户模拟器提供了前所未有的数据支撑。此外,数据集内置了训练/测试划分,便于开展可复现的基准实验。
使用方法
在HuggingFace生态中,用户可通过指定配置名称(config_name)加载特定子数据集,例如使用'OpenAssistant_oasst2'或'Anthropic_hh-rlhf'等参数。加载后,每条数据直接以用户为单位,包含'user_id'、'user_meta'和'conversations'键,研究者可直接遍历conversations列表获取完整的对话历史,用于训练用户状态追踪模型或对话策略模块。由于数据已按用户聚合,非常适合回放式评估或构建基于用户画像的个性化对话系统。建议结合HuggingFace Datasets库的流式加载功能处理海量数据,以优化内存占用。
背景与挑战
背景概述
在大语言模型与人类交互日益频繁的当下,如何精准模拟真实用户的多轮对话行为已成为提升对话系统智能水平的关键课题。human-sim数据集由研究团队于近期构建,旨在为对话模拟提供高质量的多源训练数据。该数据集汇聚了来自OpenAssistant、Anthropic、ConvLab等多个知名对话数据源的用户级对话信息,通过SHA-256哈希处理用户身份并聚合其完整对话历史,构建出极具生态多样性的用户画像。其核心研究问题是:能否通过整合大规模、跨场景的真实用户对话数据,训练出能够复现人类对话模式与偏好的用户模拟器。该数据集的出现为强化学习中的奖励建模、基于人类反馈的微调(RLHF)以及对话系统的鲁棒性评估提供了重要资源,有望推动智能对话代理向更自然、更拟人化的方向迈进。
当前挑战
human-sim数据集所面临的挑战涵盖领域问题与构建过程两个层面。在领域问题层面,对话系统长期受困于用户行为多样性与对话模式复杂性难以完整建模的困境,现有用户模拟往往局限于特定场景或单一风格,泛化能力不足。该数据集旨在解决的正是这种跨域、跨风格的对应用户模拟难题,以提升模拟代理在未见对话场景中的适应性与真实性。在构建过程中,从多个来源聚合用户对话记录面临数据格式异构性大、元数据与对话信息对齐困难等障碍。此外,涉及用户隐私信息的处理(如采用哈希方式对IP进行脱敏),在保障数据可用性与隐私保护之间寻找平衡也是一项不小的技术挑战。同时,不同来源的对话数据在语言风格、对话长度和内容质量上参差不齐,如何筛选与融合以保持训练数据整体的一致性与高质量,同样是构建该数据集必须攻克的关键难题。
常用场景
经典使用场景
在对话系统与用户模拟研究的交汇处,human-sim数据集为构建高保真度用户代理提供了坚实基础。该数据集将多个公开可用的对话数据集整合为以用户为中心的格式,每一行记录对应一个特定用户及其全部对话历史。研究者可利用这些丰富的用户级信息,训练能够模拟真实用户行为、偏好和对话模式的智能体,从而在无需与真实用户交互的情况下,对对话系统进行大规模、可控且可复现的评估与优化。特别是在强化学习、偏好对齐和个性化对话生成等任务中,此数据集作为用户行为建模的黄金标准,推动了从静态基准测试向动态用户模拟的范式转变。
解决学术问题
human-sim数据集直面对话系统研究中长期存在的用户多样性建模与评估泛化性两大核心挑战。传统研究常依赖单一数据集或手工设计的规则来模拟用户,难以捕捉真实世界中用户意图、表达方式和偏好的巨大差异。该数据集通过聚合来自OpenAssistant、Anthropic、WildChat等二十余个高质量对话源的用户级数据,使研究者能够系统性地探讨个性化对话生成、跨领域用户行为迁移学习以及对话策略的鲁棒性评估等学术问题。其意义在于,首次将用户模拟从辅助性评估工具提升为核心研究课题,为开发更加人性化、可适应且对齐人类价值观的对话系统奠定了方法论基础。
衍生相关工作
围绕human-sim数据集已萌发出一系列具有里程碑意义的研究工作。在用户模拟方法上,衍生出基于大语言模型的上下文感知模拟器,它们能够动态生成贴合用户历史行为的对话轨迹,突破了传统规则系统缺乏泛化能力的局限。在评测体系方面,该数据集催生了标准化用户模拟评测基准,将对话成功率和用户满意度等指标纳入统一框架,推动了不同模拟方法的可复现比较。更前沿的工作探索了利用该数据集进行联邦用户建模,在保护隐私的前提下共享跨数据集的行为知识,为人机交互研究中的数据稀缺与隐私保护矛盾提供了创新解决方案,极大丰富了对话系统的研究生态。
以上内容由遇见数据集搜集并总结生成


