MultiZebraLogic
收藏arXiv2025-11-05 更新2025-11-07 收录
下载链接:
https://huggingface.co/datasets/alexandrainst/zebra_puzzles
下载链接
链接失效反馈官方服务:
资源简介:
MultiZebraLogic 是一个多语言逻辑推理基准数据集,旨在为各种推理能力的语言模型提供比较。数据集包含多种语言、主题、大小的斑马谜题,并包括14种不同的线索类型和8种误导线索。数据集已发布,支持9种日耳曼语系语言,包含2x3和4x5大小的谜题。该数据集可用于评估语言模型的逻辑推理能力,并有助于开发更高级的逻辑推理模型。
MultiZebraLogic is a multilingual logical reasoning benchmark dataset designed to facilitate comparative assessments of language models across diverse reasoning capabilities. It includes Zebra puzzles spanning various languages, thematic domains and scales, with 14 distinct clue types and 8 types of distractor clues. The dataset has been publicly released, supports 9 languages from the Germanic language family, and features puzzles with grid sizes of 2x3 and 4x5. This dataset can be utilized to evaluate the logical reasoning capacities of language models, and aids in the development of more advanced logical reasoning models.
提供机构:
亚历山大研究所
创建时间:
2025-11-05
原始信息汇总
数据集概述
基本信息
- 数据集名称: MultiZebraLogic
- 许可证: Apache-2.0
- 创建者: Sofie Helene Bruun 和 Dan Saattrup Nielsen(Alexandra Institute)
- 资助方: EU Horizon项目TrustLLM(资助协议号101135671)和Danish Foundation Models
数据集描述
- 类型: 斑马谜题(约束满足问题)
- 用途: 评估逻辑推理能力
- 语言: 丹麦语(da)、荷兰语(nl)、英语(en)、法罗语(fo)、德语(de)、冰岛语(is)、挪威博克马尔语(nb)、挪威尼诺斯克语(nn)、瑞典语(sv)
配置规格
谜题尺寸
- 2x3尺寸: 2个对象×3个属性
- 4x5尺寸: 4个对象×5个属性
主题类型
- 房屋主题: 对象为房屋,属性为居民特征(国籍、职业等)
- Smørrebrød主题: 对象为开放式三明治,属性为配料(仅丹麦语版本)
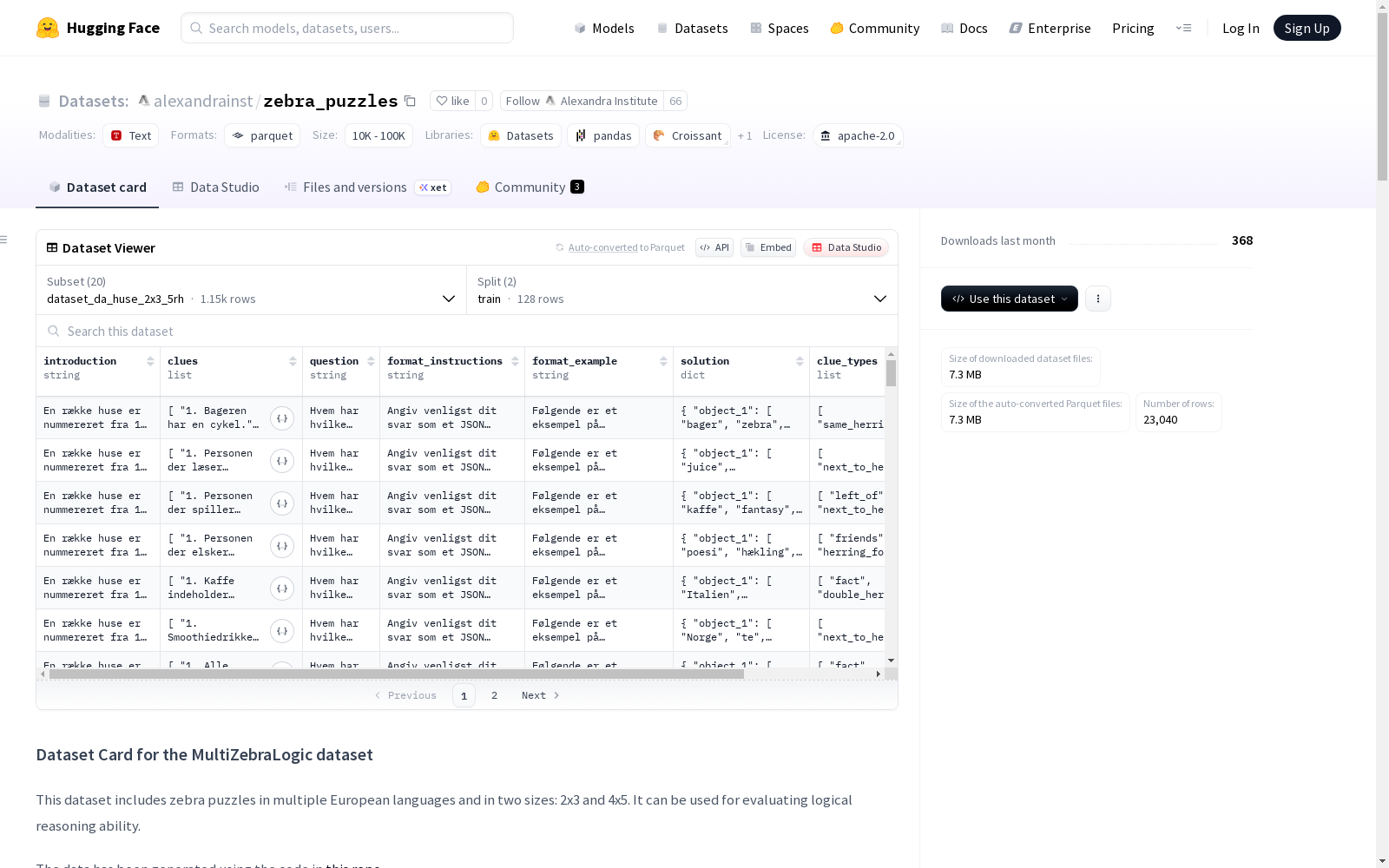
数据集结构
特征字段
- introduction: 介绍文本
- clues: 线索序列
- question: 问题描述
- format_instructions: 格式说明
- format_example: 格式示例
- solution: 解决方案结构体
- clue_types: 线索类型序列
- red_herrings: 干扰线索索引
数据划分
- 训练集: 每个配置128个样本
- 测试集: 每个配置1024个样本
技术特点
- 每个谜题包含5个干扰线索
- 提供建议的JSON响应格式用于LLM评估
- 解决方案表示为N_objects × N_attributes矩阵
数据生成
- 代码仓库: https://github.com/alexandrainst/zebra_puzzles
- 论文状态: 进行中
相关项目
- 部分数据计划用于EuroEval项目
搜集汇总
数据集介绍
构建方式
在逻辑推理评估领域,MultiZebraLogic数据集通过系统化生成斑马谜题构建而成。其核心流程首先生成随机解矩阵,随后基于约束满足问题框架迭代添加线索,确保每个谜题存在唯一解。生成过程中采用多语言属性短语库以适应不同语言结构,并通过翻译验证机制保证九种日耳曼语言的语义一致性与语法正确性。最终通过线索效用筛选与干扰项混排,形成具有严格逻辑结构的标准化数据集。
特点
该数据集突出表现为多维度可调节的难度特性,通过谜题尺寸扩展、干扰线索插入与文化特定主题设计实现梯度挑战。其核心优势在于涵盖14类真实线索与8类干扰线索的丰富组合,支持从2×3到4×5的多种规模配置。跨语言测试表明,模型在丹麦语与英语、传统房屋主题与特定文化主题间的表现无显著差异,印证了逻辑推理能力的泛化性。数据集同时提供128个训练样本与1024个测试样本的标准化划分。
使用方法
该数据集适用于大语言模型逻辑推理能力的系统性评估,使用者可通过加载标准化JSON格式谜题进行多维度测试。评估流程需遵循特定输出规范,要求模型生成包含完整属性分配的解矩阵。性能度量采用谜题级准确率与单元级准确率双重指标,通过对比预测解与标准解的匹配程度量化推理能力。针对不同模型类型,建议分别采用2×3规模测试非推理模型与4×5规模测试推理模型,并可结合干扰项索引实现难度微调。
背景与挑战
背景概述
MultiZebraLogic数据集由Alexandra Institute的Sofie Helene Bruun与Dan Saattrup Smart于2025年创建,旨在构建一个多语言逻辑推理基准,填补现有评测体系在跨语言逻辑推理能力评估上的空白。该数据集以斑马谜题为核心,通过约束满足问题设计,支持九种日耳曼语种,并引入文化特异性主题如丹麦开放式三明治,以增强语言模型的泛化能力。其生成代码具备高度可扩展性,推动了自然语言处理领域对多步骤推理任务的系统性评测。
当前挑战
该数据集致力于解决多语言环境下逻辑推理任务的统一评估难题,核心挑战在于平衡语言多样性与逻辑一致性,例如在语法结构差异较大的语言中保持线索无歧义性。构建过程中面临多重挑战:一是生成算法需在语言正确性、自然度与生成效率间取得权衡,尤其在处理德语等屈折语格位变化时;二是红鲱鱼线索的引入显著增加了推理复杂度,使大型语言模型在4×5谜题上的准确率下降约15%;三是多语言翻译需依赖自动化工具与人工审核结合,确保文化特定主题的语义等效性。
常用场景
经典使用场景
在自然语言处理领域,MultiZebraLogic数据集被广泛用于评估多语言逻辑推理能力,特别是针对大型语言模型在约束满足问题上的表现。该数据集通过生成包含多种语言、主题和难度的斑马谜题,为研究者提供了标准化的测试平台,能够系统性地比较不同模型在复杂逻辑推理任务中的性能差异。
解决学术问题
该数据集有效解决了多语言逻辑推理基准缺失的学术难题,填补了传统评测集如EuroEval在逻辑推理任务上的空白。通过引入红鲱鱼线索和文化特定主题,它揭示了语言模型在干扰信息下的推理鲁棒性,为研究模型泛化能力和跨语言迁移提供了重要实证基础。
衍生相关工作
该数据集催生了系列创新研究,包括基于约束满足的推理框架优化、多语言语义解析器的改进,以及红鲱鱼对抗训练方法的提出。后续工作如跨文化主题的适应性扩展、动态难度调整算法,均建立在MultiZebraLogic的基准之上,推动了逻辑推理评估范式的演进。
以上内容由遇见数据集搜集并总结生成


