davanstrien/Haiku_Dataset
收藏Hugging Face2024-03-22 更新2024-06-11 收录
下载链接:
https://hf-mirror.com/datasets/davanstrien/Haiku_Dataset
下载链接
链接失效反馈官方服务:
资源简介:
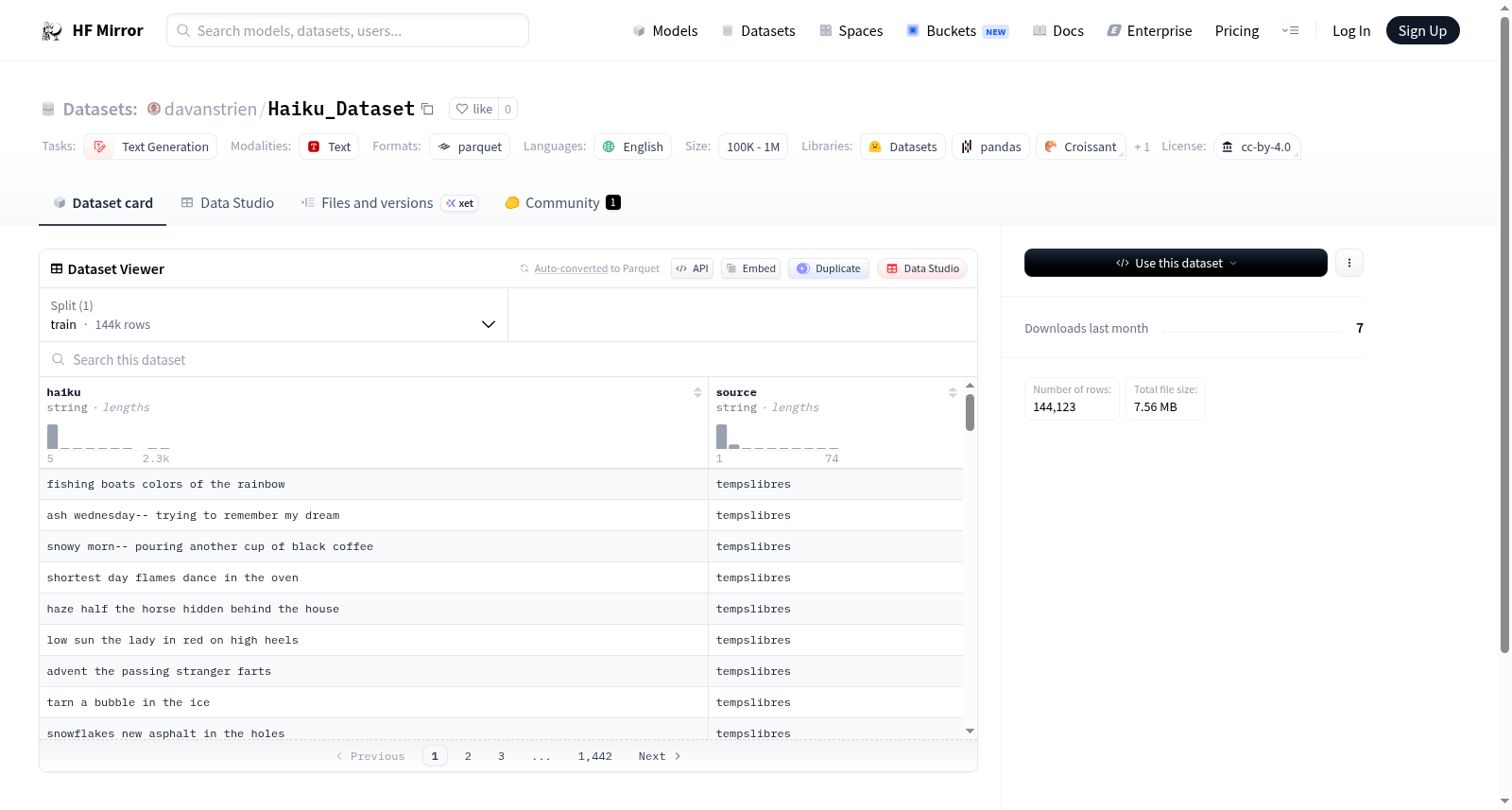
该数据集名为Haiku Dataset,主要用于文本生成任务。数据集包含两个特征:haiku和source,分别存储俳句文本和来源信息。数据集分为一个训练集,包含144,123个样本,总大小为11,725,740字节。数据集的语言为英语,许可证为CC-BY-4.0。
该数据集名为Haiku Dataset,主要用于文本生成任务。数据集包含两个特征:haiku和source,分别存储俳句文本和来源信息。数据集分为一个训练集,包含144,123个样本,总大小为11,725,740字节。数据集的语言为英语,许可证为CC-BY-4.0。
提供机构:
davanstrien
原始信息汇总
数据集概述
数据集信息
- 特征:
haiku: 类型为字符串source: 类型为字符串
- 分割:
train: 字节数为11725740,样本数为144123
- 下载大小: 7554208字节
- 数据集大小: 11725740字节
配置
- 默认配置:
- 数据文件:
train: 路径为data/train-*
- 数据文件:
许可
- 许可证: cc-by-4.0
任务类别
- 文本生成
语言
- 英语
数据集名称
- Haiku Dataset
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个英文俳句集合,包含约14.4万条文本数据,适用于文本生成任务。数据以parquet格式存储,遵循CC BY 4.0开放许可证,来源主要为tempslibres等平台,特点是专注于短诗形式的自然语言处理应用。
以上内容由遇见数据集搜集并总结生成


