Draw-In-Mind (DIM)
收藏github2025-09-04 更新2025-09-06 收录
下载链接:
https://github.com/showlab/DIM
下载链接
链接失效反馈官方服务:
资源简介:
Draw-In-Mind (DIM)数据集包含两个互补部分:DIM-T2I包含1400万个长上下文图像-文本对,用于加强指令理解;DIM-Edit包含23.3万个来自GPT-4o的思维链想象,提供明确的设计蓝图
The Draw-In-Mind (DIM) dataset comprises two complementary parts: DIM-T2I holds 14 million long-context image-text pairs to enhance instruction comprehension, while DIM-Edit features 233,000 chain-of-thought imaginations generated by GPT-4o that offer explicit design blueprints.
创建时间:
2025-09-03
原始信息汇总
Draw-In-Mind (DIM) 数据集概述
数据集简介
Draw-In-Mind (DIM) 是一个用于精确图像编辑的数据集,旨在解决统一模型在精确编辑方面的局限性。该数据集包含两个互补部分:
- DIM-T2I:包含1400万条长上下文图像-文本对,用于增强指令理解能力。
- DIM-Edit:包含23.3万条由GPT-4o生成的思维链想象,提供明确的设计蓝图。
数据集组成
- DIM-T2I:1400万条图像-文本对
- DIM-Edit:23.3万条思维链想象数据
相关模型
基于该数据集训练的两个主要模型:
- DIM-4.6B-T2I:用于文本到图像生成任务
- DIM-4.6B-Edit:用于图像编辑任务
模型架构采用冻结的Qwen2.5-VL-3B与可训练的SANA1.5-1.6B通过轻量级MLP连接而成。
性能表现
文本到图像生成性能
在GenEval和MJHQ-30K基准测试中:
- DIM-4.6B-T2I在总体得分达到0.77
- 在MJHQ-30K上FID得分为5.50,表现优异
图像编辑性能
在ImgEdit基准测试中:
- DIM-4.6B-Edit总体得分为3.67
- 在多个编辑类别(添加、调整、扩展、替换、移除、背景、风格、混合、动作)均表现良好
开源计划
数据集和模型发布计划:
- [x] DIM论文
- [ ] DIM-4.6B-T2I模型
- [ ] DIM-4.6B-Edit模型
- [ ] DIM-Edit数据
- [ ] DIM-T2I数据
评估基准
支持多个标准评估基准:
- GenEval
- MJHQ-30K
- ImgEdit
- GEdit-Bench-EN
模型访问
模型可通过Hugging Face获取:
- DIM-4.6B-T2I:https://huggingface.co/stdKonjac/DIM-4.6B-T2I
- DIM-4.6B-Edit:https://huggingface.co/stdKonjac/DIM-4.6B-Edit
搜集汇总
数据集介绍
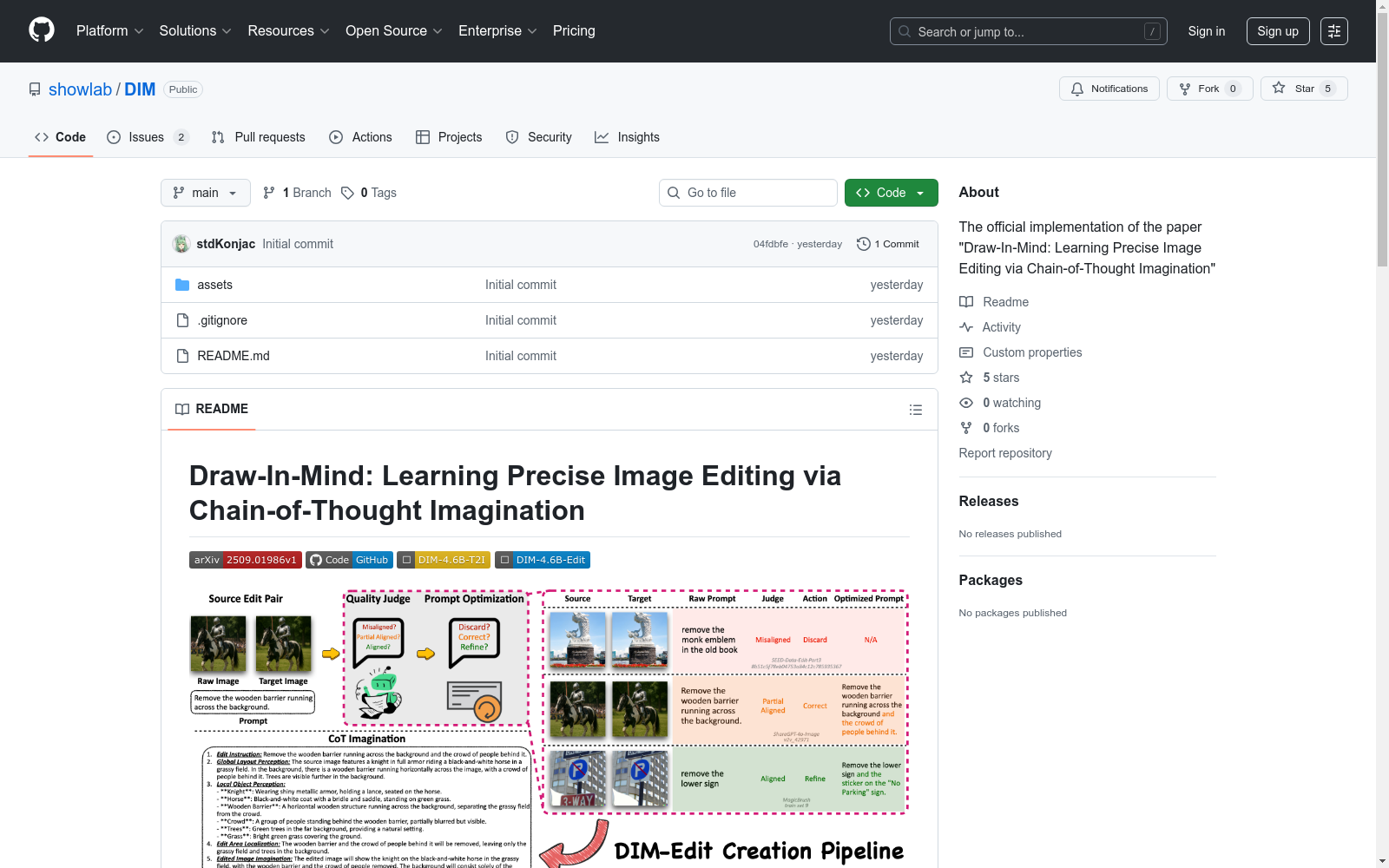
构建方式
在图像编辑领域,精确指令理解与执行一直是技术难点。Draw-In-Mind数据集的构建采用双轨策略:DIM-T2I部分通过收集1400万条长上下文图像-文本对,强化模型对复杂指令的语义解析能力;DIM-Edit部分则借助GPT-4o生成23.3万条链式思维想象数据,为编辑任务提供显式设计蓝图。这种构建方式通过解耦理解与生成任务,为模型提供了结构化的学习范式。
特点
该数据集的核心特点在于其思维链引导的编辑范式与模块化责任分配机制。DIM-Edit包含的链式思维数据将抽象编辑指令分解为可执行的设计步骤,使模型能够进行逐步推理。同时,数据集支持冻结视觉理解模块与可训练生成模块的协同架构,显著降低了生成模块的认知负荷。这种设计使参数量仅46亿的模型在ImgEdit等基准测试中超越规模更大的竞争对手。
使用方法
使用该数据集时需通过Hugging Face平台获取预训练模型权重,并按照指定目录结构部署检查点。推理过程支持两种模式:文本到图像生成需准备包含提示词的JSONL文件,执行脚本后输出结果将保存至指定路径;图像编辑任务则需配置外部设计器API,可选择GPT-4o或Qwen-VL系列模型生成思维链指导,最终实现基于蓝图的精确图像修改。评估阶段需下载标准基准数据集并按规范组织文件结构运行相应脚本。
背景与挑战
背景概述
在人工智能视觉生成领域,统一模型虽在文本到图像生成任务中表现卓越,却在精确图像编辑方面存在显著局限。Draw-In-Mind (DIM) 数据集由研究团队于2024年提出,旨在通过重构责任分配机制解决此问题。该数据集包含DIM-T2I和DIM-Edit两个子集,分别强化指令理解与提供链式思维设计蓝图,其核心研究在于将理解模块定位为设计师角色,生成模块专注于渲染,从而提升编辑精度。这一创新对多模态人工智能的发展具有重要推动作用,为精细化视觉内容生成设立了新基准。
当前挑战
DIM数据集致力于解决精确图像编辑中指令与生成结果不一致的核心挑战,包括复杂空间关系理解、多对象属性协同修改及上下文一致性保持等难题。构建过程中面临双重挑战:一是需生成高质量链式思维数据,依赖GPT-4o等大模型产生可靠的设计蓝图;二是需协调冻结视觉语言模型与可训练生成模块的交互,通过轻量级MLP桥接实现责任分离,同时确保数据规模与模型效率的平衡。
常用场景
经典使用场景
在计算机视觉与生成式人工智能领域,Draw-In-Mind数据集通过其独特的链式思维想象机制,为精确图像编辑任务提供了标准化评估框架。该数据集广泛应用于多模态模型的指令理解与执行能力测试,尤其在处理复杂编辑指令时展现出显著优势。研究者通常利用DIM-Edit子集的233K条GPT-4o生成的思维链数据,训练模型分解编辑任务为逻辑步骤,从而实现从全局构图到局部细节的精准控制。
衍生相关工作
基于DIM数据集衍生的经典工作包括Janus-Pro系列模型的迭代优化和BAGEL架构的改进。研究者通过引入DIM的链式思维监督机制,开发出具有显式推理路径的多模态对话系统;在图像生成领域,MetaQuery-L等模型借鉴其责任分离理念,实现了更精细的跨模态对齐。这些衍生工作不仅持续刷新ImgEdit和GEdit-Bench等基准测试的性能记录,更推动了整个行业向可解释性强、可控性高的生成式人工智能方向发展。
数据集最近研究
最新研究方向
在视觉内容生成领域,Draw-In-Mind (DIM) 数据集正推动精确图像编辑技术的范式革新。其核心突破在于通过思维链(Chain-of-Thought)想象力机制,将传统统一模型中理解模块与生成模块的职责重新分配。DIM-Edit 部分提供的23.3万条GPT-4o生成的推理蓝图,使理解模块承担设计职责,而生成模块专注于渲染执行,有效解决了多模态大模型在细粒度编辑任务中的责任失衡问题。当前研究热点集中于外部设计器与生成模型的协同优化,特别是在保持模型轻量化同时提升编辑精度方面。该数据集在ImgEdit和GEdit-Bench等基准测试中展现的竞争优势,为构建更高效的多模态推理系统提供了重要范式参考,推动了可控图像生成技术向更高阶的认知协同方向发展。
以上内容由遇见数据集搜集并总结生成


