TINYFABULIST TRANSLATION FRAMEWORK (TF2)
收藏arXiv2025-09-09 更新2025-09-11 收录
下载链接:
https://huggingface.co/datasets/klusai/tf2-en-ro-15k, https://huggingface.co/datasets/klusai/tf2-en-ro-3m, https://huggingface.co/klusai/tf2-1b, https://huggingface.co/klusai/tf2-4b, https://huggingface.co/klusai/tf2-12b
下载链接
链接失效反馈官方服务:
资源简介:
TINYFABULIST TRANSLATION FRAMEWORK (TF2)是一个用于数据集创建、微调和评估的统一框架,专注于英语到罗马尼亚语的文学翻译。它创建并公开发布了一个紧凑的、微调的语言模型(TF2-12B)和大规模的合成平行数据集(DS-TF2-EN-RO-3M和DS-TF2-ENRO-15K)。基于迄今为止最大的合成英语寓言集合DS-TF1-EN-3M(TF1),我们解决了低资源语言(如罗马尼亚语)中丰富、高质量的文学数据集的需求。我们的管道首先使用高性能的LLM从TF1池中生成15k高质量的罗马尼亚语参考。然后,我们对一个12B参数的开放权重模型应用两阶段的微调过程:(i)指令微调以捕获特定类型的叙事风格,(ii)适配器压缩以提高部署效率。评估结合了语料库级别的BLEU和基于五维LLM的评分标准(准确性、流畅性、连贯性、风格、文化适应)来提供对翻译质量的细微评估。结果显示,我们的微调模型在流畅性和充分性方面与顶级的大型专有模型具有竞争力,同时是开放、可访问的,并且成本效益显著。除了微调模型和两个数据集之外,我们还公开发布了所有脚本和评估提示。因此,TF2为研究成本效益高的翻译、跨语言叙事生成以及在低资源语言中广泛采用开放模型以获取具有文化意义的文学作品提供了一个端到端的可重复的流程。
The TINYFABULIST TRANSLATION FRAMEWORK (TF2) is a unified framework for dataset creation, fine-tuning, and evaluation, focusing on English-to-Romanian literary translation. It has created and publicly released a compact, fine-tuned language model (TF2-12B) and large-scale synthetic parallel datasets (DS-TF2-EN-RO-3M and DS-TF2-ENRO-15K). Building on the largest-to-date synthetic English fable collection DS-TF1-EN-3M (TF1), we address the demand for rich, high-quality literary datasets in low-resource languages such as Romanian. Our pipeline first generates 15k high-quality Romanian references from the TF1 pool using a high-performance LLM. Then, we apply a two-stage fine-tuning process to a 12B-parameter open-weight model: (i) instruction fine-tuning to capture specific narrative styles of the target genre, and (ii) adapter compression to improve deployment efficiency. Evaluation combines corpus-level BLEU scores and a five-dimensional LLM-based scoring criterion covering accuracy, fluency, coherence, style, and cultural adaptation to provide a nuanced assessment of translation quality. Results show that our fine-tuned model competes with top large proprietary models in terms of fluency and adequacy, while being open, accessible, and significantly cost-effective. In addition to the fine-tuned model and the two datasets, we have also publicly released all scripts and evaluation prompts. Therefore, TF2 provides an end-to-end reproducible workflow for researching cost-effective translation, cross-lingual narrative generation, and the widespread adoption of open models in low-resource languages to obtain culturally significant literary works.
提供机构:
罗马尼亚克卢日-纳波卡巴贝什-博里亚伊大学数学与计算机科学学院,KlusAI实验室,罗马尼亚
创建时间:
2025-09-09
搜集汇总
数据集介绍
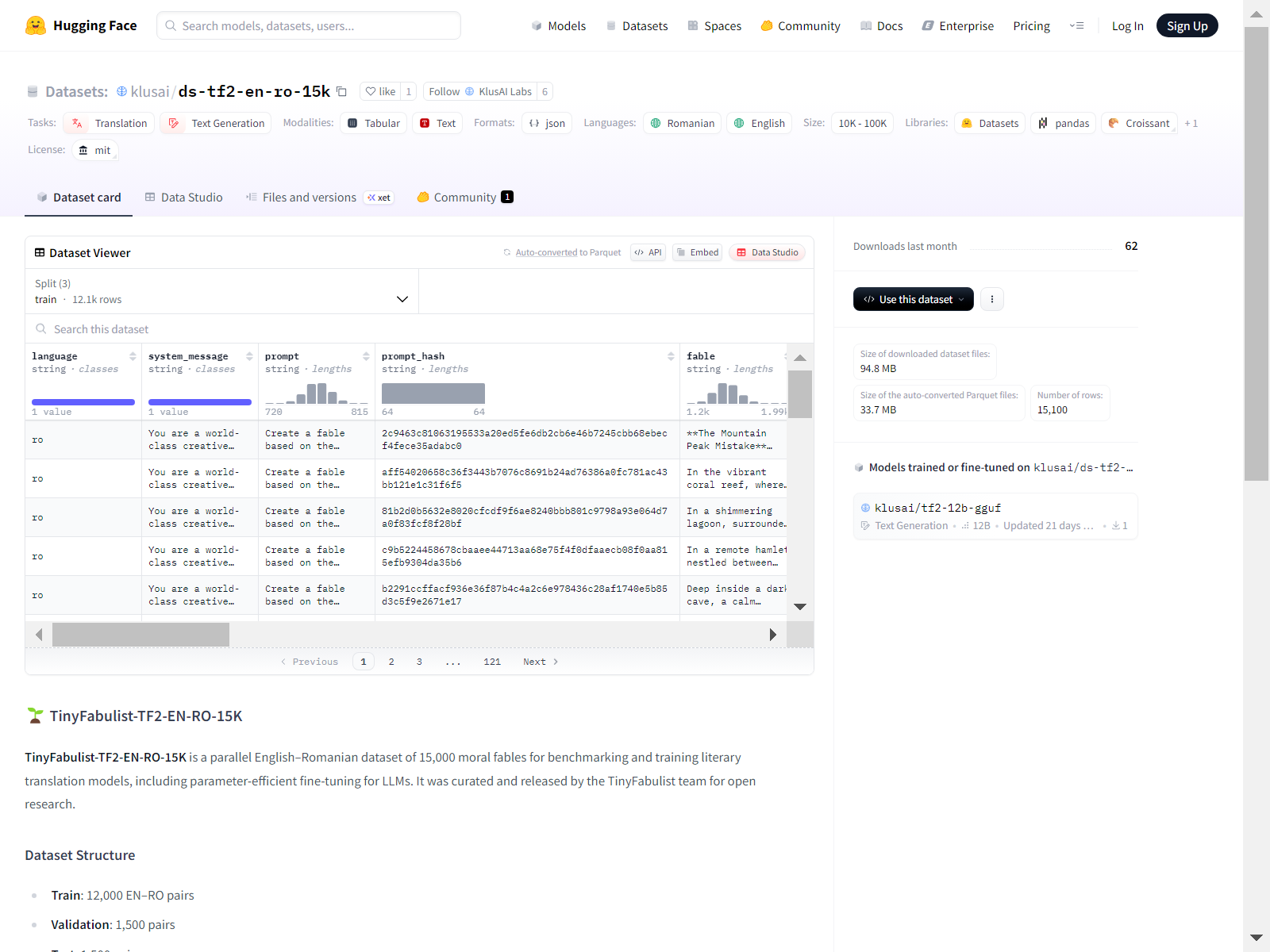
构建方式
该数据集采用四阶段流水线构建方法,首先通过多模型评估筛选最优翻译系统,随后利用高性能LLM将15,000篇英文寓言翻译为罗马尼亚语形成高质量平行语料。基于此采用参数高效的LoRA适配器技术对开放权重模型进行领域适配,最终通过微调后模型完成300万篇寓言的规模化翻译。整个过程融合了指令微调与适配器压缩技术,确保在严格控制成本的前提下实现文学翻译数据的规模化生成。
特点
数据集涵盖英语-罗马尼亚语双语平行语料,专门针对道德寓言这一文学体裁,具有明确的叙事结构和道德训诫特征。其核心优势在于规模性与高质量并存,包含精确到句子级别的对齐标注和丰富的元数据体系。每个样本均配备生成时间戳、模型版本哈希和语言代码等溯源信息,支持可复现研究。数据分布均匀覆盖不同角色、道德主题和场景设定,避免了模板化偏差,为低资源文学机器翻译提供了稀缺的基准资源。
使用方法
该数据集支持多种自然语言处理任务,包括低资源神经机器翻译模型训练、跨语言叙事生成研究以及文化适应性分析。研究人员可借助其15K高质量子集进行监督微调,利用3M大规模语料探索少样本学习范式。评估时建议结合BLEU指标与五维LLM评估框架(准确性、流畅性、连贯性、风格一致性和文化适应性),同时可通过Hugging Face平台获取配套的评估脚本和提示词模板,实现端到端的可复现实验流程。
背景与挑战
背景概述
文学机器翻译作为自然语言处理领域的重要分支,近年来在低资源语言处理方面面临显著挑战。TINYFABULIST TRANSLATION FRAMEWORK (TF2)由罗马尼亚巴比什-波雅依大学与KlusAI实验室于2025年联合创建,旨在解决英语-罗马尼亚语文学翻译中高质量平行语料匮乏的核心问题。该数据集以道德寓言为特定文本类型,通过合成数据生成与参数高效微调技术,为低资源语言场景下的叙事风格保持与文化适应性提供了重要研究基础,显著推动了开源模型在文学翻译领域的应用进程。
当前挑战
该数据集首要解决文学翻译中叙事连贯性、文化适配与风格一致性的领域挑战,尤其针对低资源语言对中创造性文本的语义保真度问题。构建过程中面临双重困难:一是缺乏现成的高质量文学平行语料,需通过大语言模型生成合成数据并确保其语言学品质;二是需要在严格成本约束下实现模型优化,涉及计算资源分配、多维度评估体系设计,以及自动化评估与人工评判之间的有效性验证等关键技术障碍。
常用场景
经典使用场景
在低资源文学机器翻译研究中,TINYFABULIST TRANSLATION FRAMEWORK (TF2)数据集被广泛应用于训练和评估英语→罗马尼亚语的叙事文本翻译模型。该数据集通过包含300万条平行寓言文本,为研究社区提供了稀缺的文学翻译资源,特别适用于探究小参数模型在保持叙事连贯性和文化适应性方面的表现。其多维度评估框架结合了BLEU指标和基于大语言模型的五维评分体系,为文学翻译质量提供了细致入微的评估基准。
解决学术问题
TF2数据集有效解决了低资源语言文学翻译中的核心学术问题:一是填补了罗马尼亚语高质量文学平行语料的空白,为低资源语言机器翻译研究提供了数据基础;二是通过参数高效的微调方法,证明了小规模开源模型在文学翻译任务上可以达到与大型专有模型相近的性能,显著降低了研究成本;三是建立了结合自动指标与语义维度的评估体系,推动了文学翻译评估方法的发展,对跨语言叙事生成和文化适应研究具有重要启示意义。
衍生相关工作
TF2数据集衍生出多个方向的重要研究工作。在模型架构方面,推动了参数高效微调技术(如LoRA适配器)在文学翻译领域的应用创新;在评估体系上,启发了基于大语言模型的多维度翻译质量评估方法,如后续研究的文化适应性专项评估框架;在数据构建领域,其合成数据生成范式被扩展至其他低资源语言对(如英语→匈牙利语、英语→乌克兰语等)的文学语料创建。这些衍生工作共同推动了开放模型在文化敏感文本处理方面的技术进步。
以上内容由遇见数据集搜集并总结生成


