damlab/HIV_FLT
收藏Hugging Face2022-02-08 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/damlab/HIV_FLT
下载链接
链接失效反馈官方服务:
资源简介:
该数据集来源于Los Alamos National Laboratory HIV sequence (LANL)数据库,包含2016年版本的1,609个高质量的HIV全基因组序列。这些序列通过GeneCutter工具处理,并使用BioPython库的Seq.translate函数翻译成相应的氨基酸序列。数据集旨在训练一个名为HIV-BERT的模型,用于预测HIV序列相关的多种特征。数据集包含ID、gag、pol、env、nef、tat、rev和proteome等字段,每个字段代表HIV基因组的蛋白质氨基酸序列。数据集的社会影响在于可用于研究HIV的序列相关特征,HIV是一种在过去几十年中在全球范围内夺去许多人生命的病毒。数据集的管理者为Will Dampier,引用信息待定。
This dataset is sourced from the Los Alamos National Laboratory HIV Sequence (LANL) Database, containing 1,609 high-quality complete HIV genome sequences from its 2016 release. These sequences were first processed using the GeneCutter tool, then translated into their corresponding amino acid sequences via the Seq.translate function from the BioPython library. This dataset is designed to train the HIV-BERT model for predicting multiple sequence-related characteristics of HIV. The dataset includes fields such as ID, gag, pol, env, nef, tat, rev, and proteome, where each field corresponds to the amino acid sequence of a protein encoded by the HIV genome. Its social impact lies in facilitating research on sequence-associated traits of HIV, a virus that has claimed millions of lives worldwide over the past few decades. The dataset is curated by Will Dampier, and the citation information is to be determined.
提供机构:
damlab
原始信息汇总
数据集描述
数据集概述
该数据集源自洛斯阿拉莫斯国家实验室(LANL)的HIV序列数据库,包含2016年最新版本的1,609个高质量全长基因组。这些序列中的基因通过GeneCutter工具处理,并使用BioPython库的Seq.translate函数翻译成相应的氨基酸序列。
支持的任务和排行榜:无
语言:英语
数据集结构
数据实例
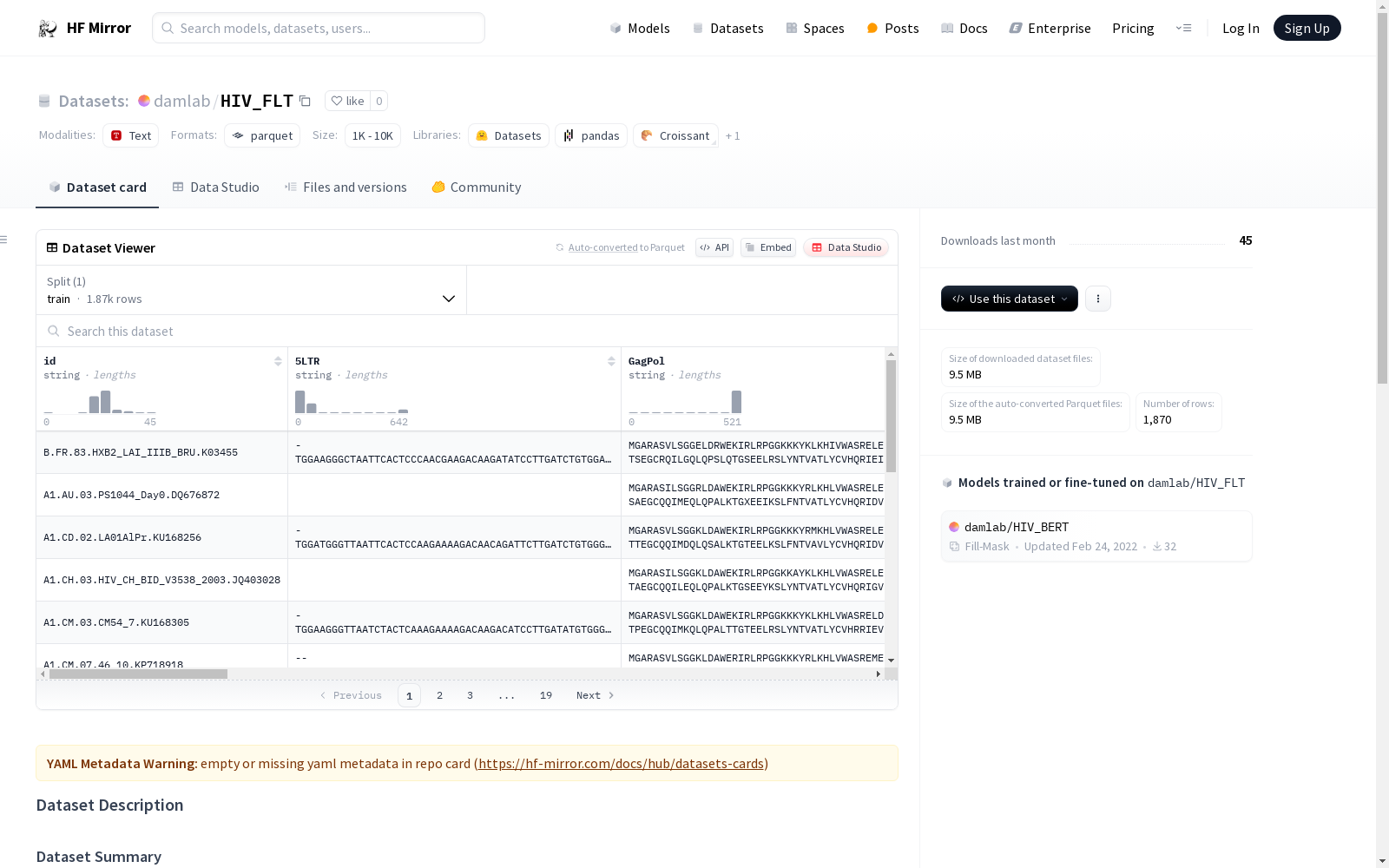
每列代表HIV基因组的蛋白质氨基酸序列。ID字段表示未来交叉引用的Genbank参考ID。共有1,609个全长HIV基因组。
数据字段:ID, gag, pol, env, nef, tat, rev, proteome
数据分割:无
数据集创建
数据集理由
该数据集是为了训练一个名为HIV-BERT的模型,该模型旨在预测与HIV序列相关的各种特征。
初始数据收集和规范化
数据集于2021年12月21日下载和整理。
使用数据时的考虑
数据集的社会影响
该数据集可用于研究HIV的序列依赖性特征,HIV是一种在过去几十年中在全球范围内夺去许多生命的病毒。
偏见的讨论
该数据集源自洛斯阿拉莫斯国家实验室(LANL)的全基因组数据库,包含每个亚型和地理区域的典型样本。
附加信息
- 数据集策展人:Will Dampier
- 引用信息:待定
搜集汇总
数据集介绍
构建方式
damlab/HIV_FLT数据集的构建,源于洛斯阿拉莫斯国家实验室HIV序列数据库(LANL)的2016年全基因组版本。该数据集包含1609个高质量的全长基因组,通过GeneCutter工具对基因进行处理,并使用BioPython库的Seq.translate函数将其翻译为相应的氨基酸序列。
使用方法
在使用damlab/HIV_FLT数据集时,研究者可以直接访问包含蛋白质氨基酸序列的数据实例,每个实例都包括一个Genbank参考ID,以便进行后续的交叉引用。由于数据集不包含数据划分,研究者需根据具体研究需求自行进行数据切分和预处理。
背景与挑战
背景概述
在人类免疫缺陷病毒(HIV)研究领域,序列分析是理解病毒变异和感染机制的关键。damlab/HIV_FLT数据集,源自洛斯阿拉莫斯国家实验室(LANL)的HIV序列数据库,由Will Dampier于2021年12月21日整理完成,包含了1609个高质量的全基因组序列。该数据集旨在为HIV-BERT模型的训练提供支持,进而预测与序列相关的各种特征,对于HIV的研究具有重大影响力。
当前挑战
该数据集在构建过程中所面临的挑战主要包括数据的准确性和代表性。首先,确保序列的高质量是关键,这需要通过精确的生物信息学工具处理,如GeneCutter和BioPython的Seq.translate功能。其次,数据集必须代表性地涵盖HIV的各个亚型和地理区域,以避免偏差,这对于全球HIV研究尤为重要。此外,由于HIV的高度变异性,数据集的时效性也是一个挑战,需要不断更新以反映最新的病毒序列。
常用场景
经典使用场景
在探索HIV病毒变异与适应性机制的科研领域,damlab/HIV_FLT数据集提供了一个宝贵的信息宝库。该数据集包含的高质量全长基因组序列,常被用于构建和训练生物信息学模型,如HIV-BERT,旨在预测序列依赖性特征,成为研究者和临床医生深入理解HIV病毒变异动态的重要工具。
解决学术问题
damlab/HIV_FLT数据集的构建,有效解决了HIV研究领域中对于全长基因组序列信息的迫切需求。它为科研人员提供了详尽的基因编码区和蛋白质序列,有助于解析HIV病毒的基因变异模式,从而对疾病的防控和治疗提供了科学依据。
实际应用
在实际应用中,damlab/HIV_FLT数据集的应用遍及HIV病毒的监测、疫苗设计、药物研发等多个方面。通过对该数据集的分析,研究者能够发现病毒传播的规律,为新药开发和疫苗设计提供了重要的数据支撑。
数据集最近研究
最新研究方向
在当今艾滋病研究领域,damlab/HIV_FLT数据集以其高质量的HIV全基因组序列,为科研人员提供了宝贵的资源。该数据集的构建旨在支撑HIV-BERT模型的训练,进而预测HIV序列依赖性特征,这标志着生物信息学在HIV研究中的应用迈出了新的一步。近期,该数据集被广泛应用于探索HIV的变异机制、病毒适应性及其与宿主相互作用的深入研究,对于揭示病毒传播规律及疫苗设计具有重要的科学价值和现实意义。
以上内容由遇见数据集搜集并总结生成


